on the 6th of april 2022 openai announced their latest model dali 2 that can create high resolution images and art given a text description the images dolly 2 creates are original and realistic it can also mix and match different attributes concepts and styles the photorealism of the images that are created the variations that w2 can come up with and also being able to create images that are highly relevant to the captions that are given is what makes delhi 2 one of the most exciting innovations this year so what can it do validu's main functionality is
to create images given a certain text or a caption but on top of that it can also edit images and add some new information for example add a couch to a empty living room space and on top of that you can also create alternatives or variations to a given image let's take a look inside and understand how it works deli 2 consists of two parts one to convert captions into a representation of an image called the prior and another to turn this representation into an actual image and this part is called the decoder the text
and image representations used in deli 2 are coming from another technology again developed by open ai called clip so to understand how clip is used in dali 2 let's take a closer look first at what clip is clip is a neural network model that returns the best caption given an image so it basically does the opposite of what we want to do with dali too but it is still helpful for us it is a contrastive model so it doesn't try to classify images instead what it does is match images to their corresponding captions so it
shouldn't be surprising to you to learn that it is trained on image and caption pairs that is collected from the internet so just imagine how many caption and image pairs can be collected only from instagram so to be able to do the matching clip trains two encoders one encoder turns images into image embeddings and the other encoder turns text or caption into text embeddings if the word embedding is not familiar to you just know that it is basically a mathematical way of representing information for example taking a sentence that looks like this and turning it
into a vector we are basically embedding it in a different space so the problem clip is optimizing for is making sure that the similarity between the embedding of an image and the embedding of its caption is as high as possible if we organize the image and text embeddings like so let's say i1 being the embedding of the first image t1 being the embedding of the first image's caption and values in the matrix being the similarity between intersecting embeddings we want the blue highlighted cells to have the highest value and the gray ones to have the
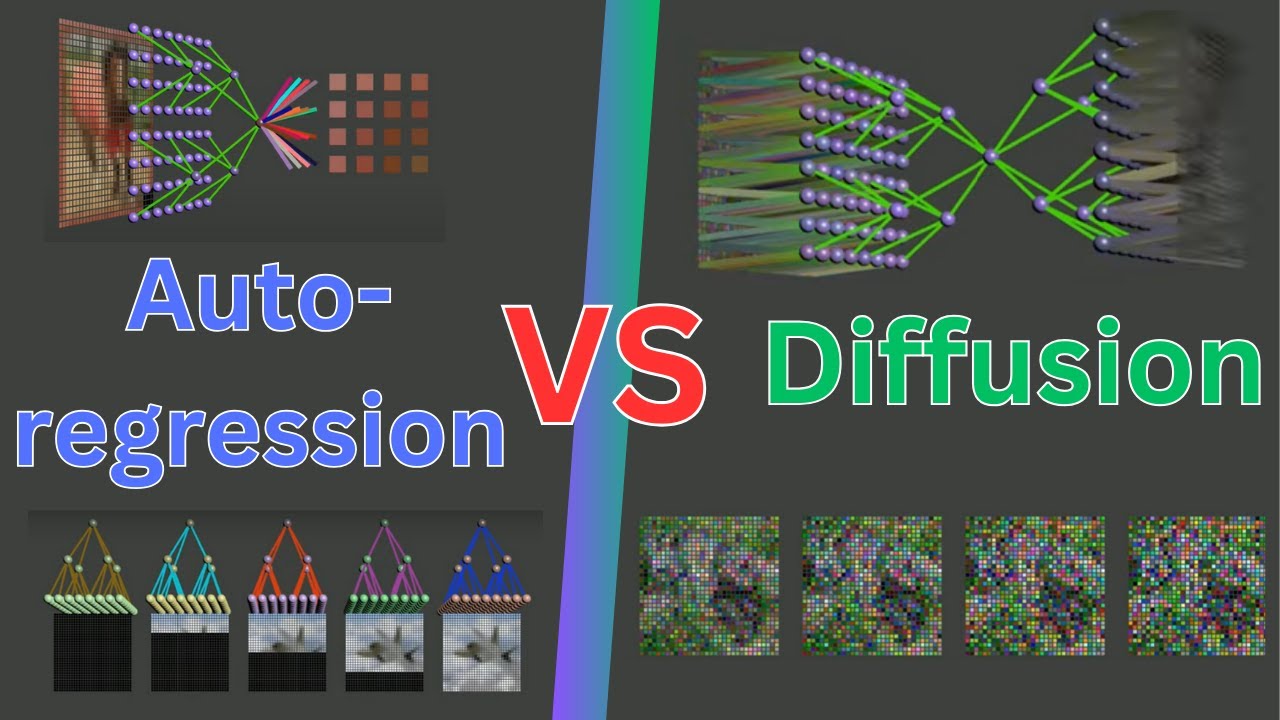
lowest value there is more you can learn about clip of course but this is enough to understand how it is used in dali so let's get back to the dolly architecture the blue vector shown here is the clip text embedding and the orange one is the clip image embedding the prior takes the clip text embedding which is easily generated from the caption through the clip text encoder and creates a clip image embedding out of it in the paper the researchers try two different options for the prior one of them is called the auto regressive prior
and the other one is called the diffusion prior but they found out that the diffusion model worked better for delhi 2. in case you're not familiar with it let's talk about what diffusion models are for a second diffusion models are generative models and their working principle is actually quite simple diffusion models take a piece of data for example a photo and gradually add noise to it over time steps until it is not recognizable anymore and from that point they try to reconstruct this image to go back to its original form and by doing that they
learn how to generate images or data all right back to dolly too so once the prior creates the clipped image embedding the next step is to create the image itself and the decoder is responsible for that but before we go further here you might think hey wait a minute why can't we just pass the caption or the text embedding directly to the decoder to create the image why do we need a prior at all well that's a really good question and the authors ask themselves the same thing too so they tried the model by passing
the caption directly to the decoder and also the text embedding directly to the decoder and they found that having the prior actually yields the best results let's look at an example that was shared in the paper to understand this a little bit better so for the caption a hedgehog using a calculator passing the caption directly to the decoder gives this image or passing the text embedding directly to the decoder gives this other image there as if we have a prior this is the output image that we get so you can see that using the text
embedding actually gives acceptable results right but the problem with that is then you lose the capability of generating variations over images but we will talk about how dolly 2 generates variations of images a little bit later in this video let's move on to the decoder in delhi 2 the decoder is also a diffusion model but it is an adjusted one as the decoder the authors are using another model that was created by openai called glide the light itself is an image generation model but differently from a pure division model it also includes the embedding of
the text that was given to the model to support the image creation process so at the end you will be creating an image based on the text in dolly too the decoder is set up so that it not only includes the text information like in glide but it also includes the clip embeddings to support the image generation after a preliminary image is created that is 64 times 64 pixels there are two up-sampling steps to make the images high resolution and this is how image generation happens with dali 2. but let's also take a look at
how the variations are created with deli 2. making a variation of a given image means that you keep the main element and the style of an image but change the trivial details in dolly 2 this is done by obtaining the images clip image embedding and running that through the decoder by encoding an image using clip and then decoding this image embedding using the diffusion decoder we can also see what information was caught by clip and what information was lost for example we see that in salvador dali's painting clip manages to keep the detail of the
existence of a clock as well as the stylistic details while varying the trivial details of the image alright we learned how dolly 2 works but how can you make sure that this is a good model how can you evaluate it as you can imagine evaluating a creative model like dali 2 is challenging because you cannot just use simple metrics like accuracy or mean percentage error to evaluate dolly 2 the authors asked humans to assess the products of this model in terms of caption similarity photorealism and sample diversity by looking at example created images and answering
some questions the authors found that delhi 2 was strongly preferred when it came to sample diversity all in all looking at the examples that are created it is not hard to be convinced that this is a groundbreaking model now it's time to talk about some limitations as impressive as dali 2 is there are still some shortcomings and potential risks of it first of all dolly 2 is worse at binding attributes to objects than other models like glide for example when asked to depict a red cube on top of a blue cube it tends to confuse
which cube needs to be red and which one needs to be blue furthermore it is not yet good at creating coherent text in images here is what it came out with when asked to create an image of a sign that says deep learning the authors also observed that the model has a hard time producing details in complex scenes for example when generating an image of the time square the screens seem to not have any readable or understandable detail to them apart from its shortcomings as with all highly successful generative deep learning models there are some
risks to delhi too it has biases commonly seen in models trained on data that was collected from the internet for example gender bias profession representation and images depicting dominantly western locations and there are of course risks of dolly 2 being used to create fake images with malicious intent open ai has a page with a deeper look into the limitations and risks of dali too you can read more about it through the link in the description so knowing all these limitations and risks what is openai doing to make sure they don't cause any harm well following
the announcement for dali 2 the openai team has come up with some precautions to mitigate risks such as removing adult hateful or violent images from their training not accepting prompts that do not match their guidelines and facing access to users to contain possible unforeseen issues alright so delhi is an amazing model it is all fun and creative but it is fair to ask the question what is the benefit of a model like this open ai explains their goal like so our hope is that dali 2 will empower people to express themselves creatively dali 2 also
helps us understand how advanced ai systems see and understand our world which is critical to our mission of creating ai that benefits humanity as it stands it is one of the only bridges between image and text understanding and it is a really good step towards bigger achievements it can even help us understand how brains and creative processes work and now a question for you do you know what dolly 2 is named after if you have a guess leave it in the comment section