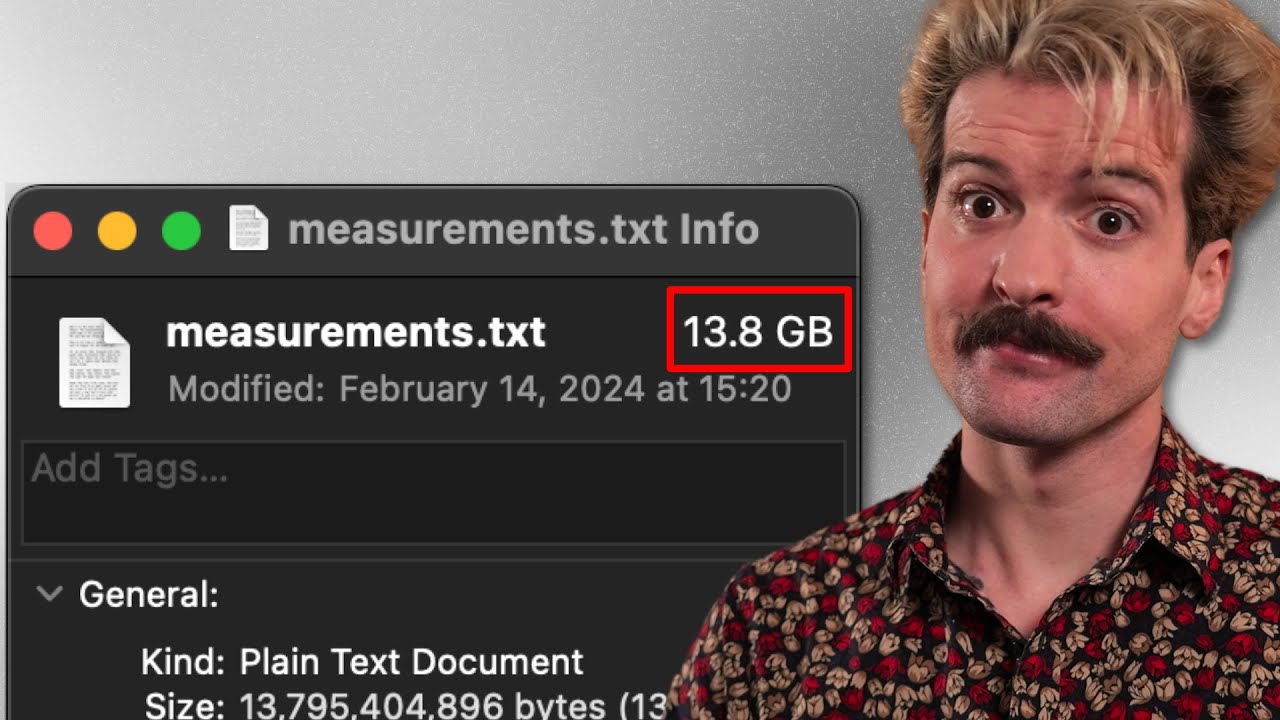
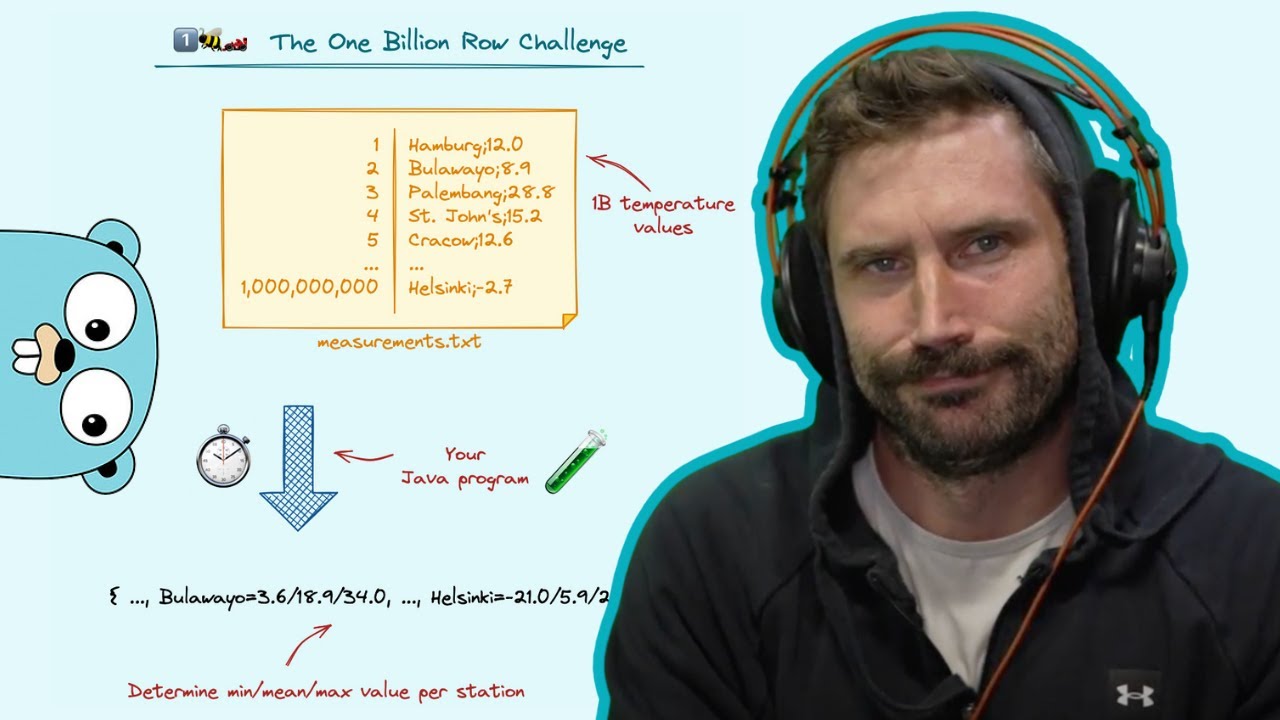
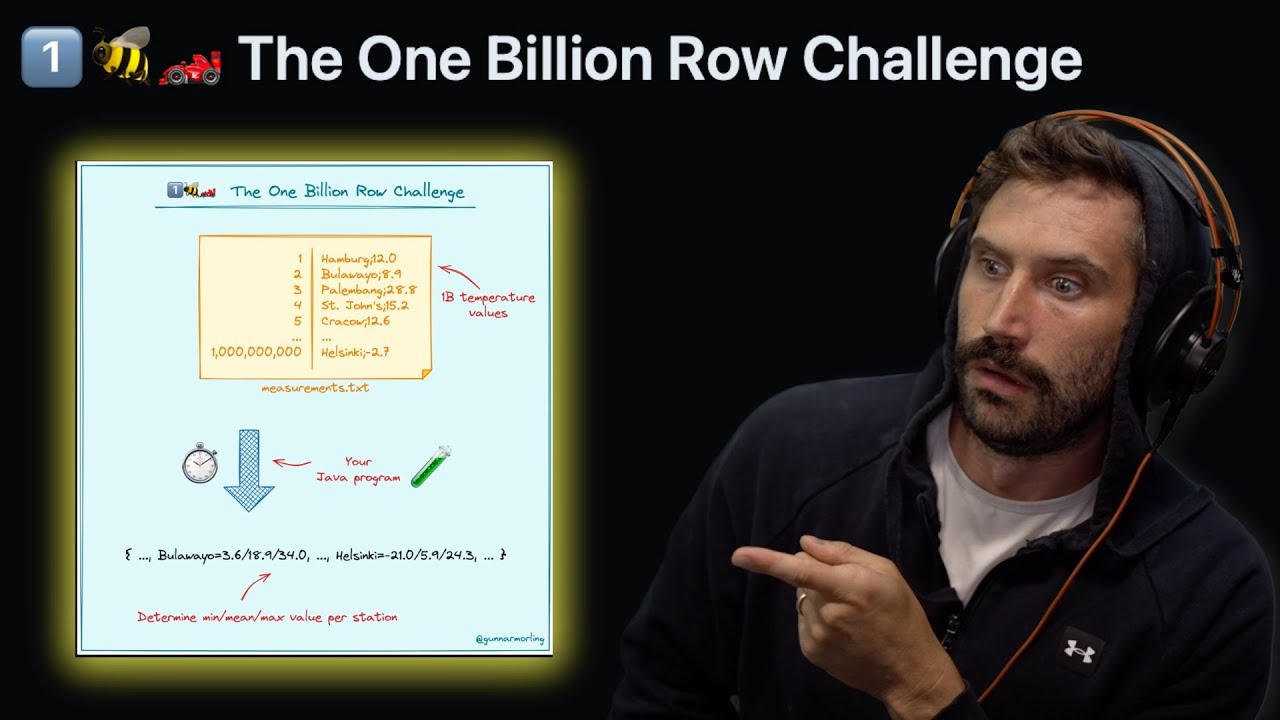
so uh the story that I'm going to tell started uh at the end of last year um it was New Year's Eve um and I had been competing in the Advent of code anybody else here competed in the Advent of code some people who finished with all stars nobody oh come on okay so I woke up 1 of January and I was a little bit of a hangover but um other than that perfect um I've been programming every day uh up to Christmas uh for the Advent of coat obviously I usually try to do it in the morning from 6:00 to 7: or from 7 to 8 before work finish everything and uh start the day um so on the on the 1 of January New Year I was like okay um it's going to be I have I have to to to kick off um I'm now used to doing this programming um but there's nothing so I'm I'm falling in a hole here um but then gunar posted this and he said um I challenge you to the 1 billion row challenge how fast can you aggregate a billion rows using modern Java and this is Vanilla Java Jaa you get a single class file that's what you what you get no libraries whatsoever uh so flexure scds um kickoff 2022 true coder style but joining this friendly little competition submission until the end of the month so what what is this challenge um you get a file with a billion rows you need to parse this you need to print out the results and like I said we are using Vanilla Java here so so everything just plain Java language no Frameworks no libraries nothing what is the format of this file well this file has um all new lines um and every time you get uh a city name and then you get a temperature and this temperature um is between minus 99. 9 and 99. 9 just one decimal prision um and uh there's a small separator between the name and the temperature so you get a billion rows and your task to in the end uh process everything print out the minimum the maximum and the average temperature for each City and you need to print it out in this specific format and non Java developers will say why this format but this is basically if you have a map and you call two string you get this and that's it that sounds relatively easy but there are some problems if you want to process this as fast as possible so there was a baseline implementation by gunar and it takes about five minutes to parse this entire file the the file itself is like I don't know 14 15 16 gigabytes or something um even opening this going through it uh um um storing the Min The Mex Etc takes a while so he uses files.
lines to read everything in in a single thread actually here here's here's most of the code um so what you can see in the top one that's uh Java record Java now is records where you can just say this is a data class which has a Min a mean and a Max you can add stuff to it but um so in this case uh We've created a custom to string uh method because we need to round it at one decimal position um there's also an aggregator which we use to aggregate all results together and and this is the entire code might look a bit daunting if you're not a Java developer uh anybody here never done Java before or are you all Java developers that's cool so um we start relatively low on the bottom we do file. lines this gives you a stream of every new line um those get split up using uh string. spit and you get an array with two parts the the station name and the temperature and this all gets collected into a hash map so how does this work well you can use an aggregator for this um and what you do is uh you start with temperatures um these temperatures uh the first one says uh create a new aggregator so if there's nothing yet it creates an empty new aggregator the second one says if we've got this new aggregator and a temperature we need to update it with this temperature and the second one is if we have two aggregators we need to aggregate to add those together as well to be able to fold everything um so the Min and Min still mix still Min still Max but the sum gets added together and the count get added together and if you have the sum and the count you can calculate the average obviously and the results print out um which is a good thing because the format that it requires is actually a map.
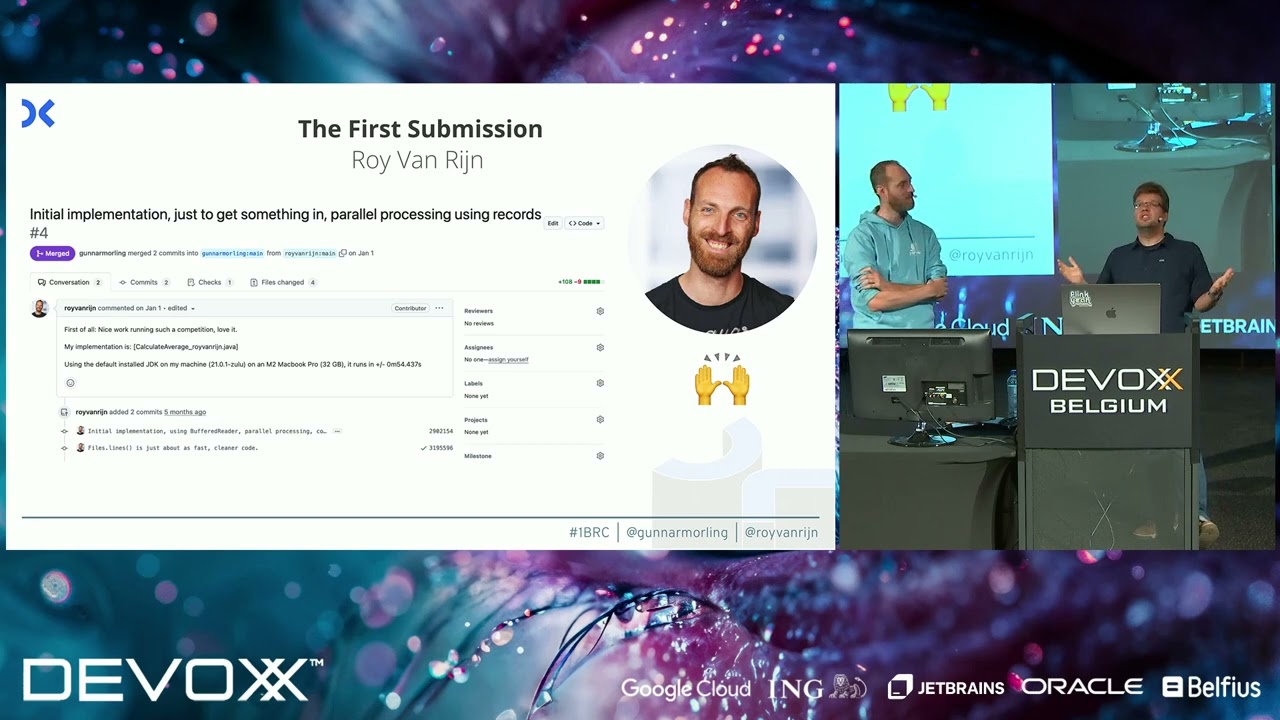
two string so this easy so I said sure gunar first of January I'll take you up on this challenge um let me quickly try to make something I'll I'll submit the first pool request because uh why not I can wait until uh the end of January um and and hide all my tricks but let's just get this ball rolling maybe people will join and it will be fun so I I submitted an initial pool request and I already slashed the run time down to 2 minutes I was so pleased I was like nobody can beat this um um but boy was out wrong so this entire contest was done uh open source all the pool requests could be viewed U so I gave all my tricks away on the first day um but that's a good thing yeah you can watch you can learn you can adopt you can experiment and everybody was getting inspired by other people's code we were just blatantly stealing each other's Cod um but that that's fun I learned a lot of new things during this contest so what did I do to slash the this runtime from almost 5 minutes to two minutes um couple of small changes so the first one um why use just a single thread you can parse file using multiple threads um if you uh do do parallel so that's what I did um why would I take this string and make a new string array where I split it up then you start making a billion new arrays which is not fun you can just look in the string find the separator break it into two parts that way that's just way faster we do need a different map here because we are now using parallel and we are writing in the same map so we need a concurrent map to not have collisions there and in the end we just uh take this entire set we sort it um and we collect everything and we print it out easy finished and I got a bit obsessed with this contest and after after two more days you can I kept the change lck you can already see uh the changes I did and the run time in milliseconds on my machine uh but on the target machine which is a different machine obviously uh which is a machine in the cloud somewhere uh I got the run time down to 23 seconds so what happened in the meantime um one of the things um so on topic uh um this is Sir Jackie Stewart F1 racing driver and he always said well you don't have to be an engineer to be a racing driver but you do have to have mechanical sympathy so you shouldn't be um uh you shouldn't have to take the entire car apart but you have to know how a suspension kind of works to be able to be communicate to the mechanics how to set it up properly and the same thing is true for programming as well so if you have a CPU this is just some sample CPU you can see it has four cores so older model and all these cores have their own little dedicated memory the L1 memory it's really tiny but every core uh um has super fast access they also have a bit larger memory but this is slower memory this the L2 cache and this is also per core in on this CPU and they have a shared L3 cache and if you look at the times this is again obviously for every CPU this will be different but the the orders of magnitude will kind of stay the same you can see there are huge differences between L1 L2 and L3 caches and if you go to main memory or the solid state drive or a disc drive things will take ages so it's very important to put the right things into the right caches so one of the first things we did was um why if there's one just one decimal position why are we working with double values um we can just multiply every by 10 and then we're done we can just work with integers which is way faster integer ma is just way faster than um double ma double Precision so when reading we multiply by 10 so we we we talk about uh 100 which is 10 degrees another thing is that uh we um instead of just reading a file sequentially we break it into segments and each processor will be uh um responsible for reading their own part of the file which is really interesting so what we do is we look at the amount of processors we have available in my machine it's eight and then we just break the file up and we need to find like the correct spot because you can't just start in the middle of segment you need to find the end of line and from there you can pause on the programming uh processing to the next uh part and instead of using just regular IO um I'm using memory mapped files who here is familiar with the term memory map files okay what you can do in a memory map file is that uh basically you tell the operating system I want this file to be memory mapped and from there on you can just reference uh the file as it is memory so you can just say go to memory address start a file and it will be there your operating system is heavily optimized and it can do this memory mapping for you and this is something Java also supports um so if you say uh files new by Channel and then you can have uh the standard option read uh and then you say file channel. map which is the memory map stuff uh and in this case I get back a bite buffer bite buffers are Java's best way to to access uh these roll bites although I am going to break this in a couple of slides I'm still using do parallel so every uh segment now is being parallel processed they all point to their own specific part in memory which is again the file works perfectly and this is already way way faster and like I said um bite buffers are perfect if you have production code and you want to do this kind of stuff use bite buffers but bite buffers still do some boundary checks which is very good we want boundary checks but not if you want break neck speed so I decided to use unsafe I had never used unsafe before but it is amazing I I I programmed c a long time ago um you can do all the dirty tricks you used to do uh but but now in Java but let me stress again yafa wants you to move away from unsafe don't do this this is cool for contests but don't do it in production code the alternatives are really good just used bite buffers so how does this work and how do we get this unsafe object um there's uh a static final field uh which in its the unsafe class uh we need to get the unsafe uh we make it accessible and then we get the field and now we have this magical unsafe object and using this unsafe object we can do a lot of cool stuff so for example uh if we do the memory mapping we can call do address um which gives us like the address in memory just along a pointer in memory to the start of the file which the operating system mapped our file in memory and then I can just say get bite and I can read a bite from there or get long and read a long value from there really cool who is familiar with the term swore I had never heard of this uh but I was very lucky that somebody on Twitter told me you should look into swar because up to this point I was processing each bite individually which kind of makes sense because we're talking about characters and characters have bites um why not do eight at a time so swar stands for simed as a register and Sim stands for single instruction multiple data so how does this work suppose we have this part of the file which is Tokyo minus 18. 3 new line Amsterdam etc etc we can read 8 bytes at a time using a single instruction if we just call um where is it if we call unsafe get long we read eight bytes at a time as a long value and if we do that it actually gets flipped around and it's a one minus in a um this is the hexadecimal value that you end up with when we we've read these eight byes and it's in a single long value second step is that we make a separator because what we want to do now is that we want to find the separator between the name where we need to make a cut and the temperature the separator itself is uh is this 3B 3B 3B thing um we make one long value that has that and then we go into this seemingly magical method so what would what do we do um so first we exor the pattern that we want so we are looking for the separator with the input and you can already see that um exor basically shows you the difference in binary and in this case there's no difference uh at that specific bite that's the answer we want but there's still a lot of junk there so there's this little trick you can do um so we have the significant bit and we subtract it from the thing we just created and then we um yeah then you get like where we had all zeros we now get all ones and we change the the bit in front what we do now is that we um end it together with the opposite of the thing that we started with and as you can see this is what we end up with which basically counts the number of zeros that it had so if you had a lot of zeros it becomes all ones and if you had just a couple of zeros you get a couple of ones and then a zero and now we can look at the most significant bit because the only way to get all once where the most significant bit is one is the case where the thing that we were looking for was exactly the same bits as before so using just uh one two three four five five uh Sy instructions on a long value we've checked where the separator is in an 8 byte um uh piece of data this is extremely fast so there's one thing left to do um so we check and we get this number back this number still doesn't say anything because ideally we we would want the number five right because there are five bytes we want the number five out of it um so what we do is we count the number of zeros we divide it by eight but dividing by eight is so slow you can just shift three times which is the same thing it's dividing by two dividing by two is four dividing by two is eight so if you do this you divide by eight and you get five and five is exactly what we want so using just a couple of instructions you can get um the separator this is extremely fast my code was still creating a lot of strings because um even if I found the separator I I would sub extract the string value from this I would extract the temperature value as a string and then I would create uh double uh integer values from that Etc but you shouldn't be allocating all these strings we can just we have access to the thing in memory so we can just uh read these long values and we can check if the first eight characters of the thing that we have is the same as the first eight characters by using a a single long comparator which is again eight times faster than than checking a bite by bite so I I stopped creating any strings until the final printing at the end then we actually need to create strings to actually output it but that's just one time not a billion another key thing that you uh need to be familiar with is branchless programming so CPUs have big pipelines of instructions they are very good in following these instructions and that's almost never the problem uh uh if you want to have FAST program it's almost never executing the instructions it's filling this Pipeline with the correct instructions and being able to predict which instructions will come next so it's your code's job to fill this pipeline as fast as possible but what instruction comes next after an if statement could be either could be this one or this one uh modern C views will just uh do both and discard the result but branches are always slow so we want to avoid that as much as possible how can we do that this is a very simple absolute value function if you go in if x is smaller than zero return Negative X otherwise return X if the CPU Encounters this a branch it will need to I don't know or either take a guess or wait until it knows the result and then can continue but if you do it like this where you say I've got this x value and there's one bit at the end which says is if negative or positive if I just shift this entire bit 31 times I got this entire thing filled with either zeros or ones which turns it into negative one and if x +0 xor zero is just X we don't do anything but if we do X+ minus one and then exor with minus one you get a negative number of X and you can always do this so you can just fill this Pipeline and it can continue on in a branchless way this is faster um you don't need to do this actually with the absolute value in Java the Java compiler is way smarter than than we we give take for granted so it does this automatically I'm not using this uh but this actual piece of code will come back later so um IA wipe my own absolute value function I just Ed the standard uh functions there so I wanted to take the things that I learned about branches programming and put this into my parser as well so I decided I want to write like a branchless um uh uh um parer to get this string value and and get the the integer of the temperature and this is what I ended up with you can see there's no no uh no if statements there so it is completely branchless but I'm still using a bite array here uh so this is from an earlier version of my code uh where I was using bite arrays and bite buffers um so I'm not using any swart tricks here I'm still looking at it bite by bite but there are some some some things that are really interesting so the temperature part that's either minus or just 12.
5 or something like that so these are the characters that we uh that we are de with and you can see that the 1 2 3 4 fifth bite is different for the minus and the dot uh opposed to all the digits so that's an important fact we can use that so if we want to see if a number is negative uh we look at the the first bite uh we just shift it four places so that that single unique bit is in front we mask it out and we flip it uh so it's one if it's negative zero if it's a positive number and I do similar tricks for looking where the dot position is and seeing if a number is actually uh oh actually this just looks at the length and the fact if it's negative or positive um so it could be 9. 9 or it could be 99. 9 so the sometimes you have three digits sometimes you have two digits you need to take care of this as well usually this is a branch but we want to have this Branch list so I'm doing this and then um these are still characters but we want actual values so if you can see uh digit one we get the bite and we subtract the character Zero to get zero and if you do that uh the character one will become one the character nine will become nine I'm actually not doing that for digits two and three because um that's two subtractions but we can actually do that if we subtract 528 because that's the same thing as 10 times the zero digit and the zero character as well so we saved another subtraction times a billion every time you see one of these optimizations it sounds silly but it's times a billion and it's good to remember that and what we can do is just the first digit times 100 uh times if it actually has a this this digit sometimes it doesn't which makes it zero and we're not using it the 10's digit and the other digit and we everything together gives us an integer value of this temperature perfect and I was so pleased I was so pleased with this code it was a little bit faster not really like incredibly faster but it was something unique and then his user Mary Kitty uh posted an update of of his code and he came up with this uh it took me a while to actually understand what was happening and I'm going to try to convince you uh uh what it does so the first thing it's not using bite arrays it's just reading this entire thing as a long value again so it's using swore kind of tricks so if we have this temperature minus 18.
3 and then there's always some junk at the end so there's a new line etc etc we don't need that but we get it anyway if we get this get long uh function and again it will be flipped in memory if you um look at a heod decimal heximal things so I'm going to keep it as this so the first line actually looks at the dot position so he has this uh dotbits um mask which is uh just three different bits and it's using again the fact that these two characters um these two bits are different in these characters than it is in the digits so it can easily in a single line check where the dot position actually is and it's either at the 12th the 20th or the 28th bit so that's that's what we store in dot position we're going to use that later so in this case um the dot position is uh as far as we can because we have n a negative sign and we have two digits for the temperature and then we have the dot position so in this case it's 28 perfect for the sign we do actually the same thing um we take this number it's in the fifth bit position that are zero or one if it's negative or a digit we shift it all the way to the end so that the the this the the the bit that we're looking for is in the negative or positive position and then we shift it all the way back so the number we end up with is either zero or minus one if it's minus one if it's NE Z if it's positive number we keep that as well this is actually uh a silly method that takes this do dot position which is either 12 20 or 28 and turns it into 08 or 16 and this is the MK so we're going to use this to shift accordingly we either need to shift the number Z8 or 16 bits now if there's a minus sign we don't want to use the values that are in the minus sign so we need to uh mask this out so this creates a little mask if there's no negative sign there's no mask if there is a negative sign we mask out this first negative character perfect and now we combine this all together we just take these final bits uh we do that for all the three spots that we possibly have uh characters that might be digits and uh we're left with uh a number that is in this form so it's a single number it has uh one digit in the hundreds one digit in the T and one digit in the in the in the units uh but we're still not there yet so in the case of minus 18.