hello there look at these objects right here what if i told you that i'm going to give you a bunch of pictures of these objects from different sides and what you have to do is you have to come up with a system that generates me the picture as if the object was viewed from any direction so something like this right any direction you can get me a picture of that object from just a few input pictures this is a pretty daunting task specifically look at the ship for example right here you can see in the
water there's specularities that only appear if you view it from a very particular angle right also the drum kit you see that the microphone on the left it has very specific uh structure to it so this is not at all like a trivial task um there there's very there's very uh very intricate things here and this not only with toy data but here you can see uh real world scenes so this isn't some kind of abstract thing you can actually use this in the real world now don't look at these things too long they tend
to make me dizzy but that's ultimately the goal input a few pictures and then being able to synthesize any kind of view so the paper we're going to look at it's a bit of an older paper but i think it's pretty cool and it's relevant and there is a bunch of follow-up work to this this is very popular right now this is the paper introducing nerf representing scenes as neural radiance fields for view synthesis and it's by ben mil sorry ben mildenhall pratul p srinivasan matthew tanchik jonathan t baron ravi rama murthy and ren eng
this as you can see the task is called view synthesis and what you can do with with view synthesis or with this paper specifically is you can it can also it takes into account your viewing direction which gives a much more realistic impression we've already seen this with kind of the the lighting here but in order to really show you this on the left you're going to see this novel view that is rendered and on the right it's sort of like a fake thing that you couldn't do in reality but what we're going to do
is we're going to keep the camera at the same position but we're going to tell the scene that the camera is at a like switching around and that makes you able to see just how different a pic like a room can look like if viewed from different directions so the right one is really kind of physically impossible it's just meant to show you how different things look differently if they think they are viewed from a different direction right so the same thing here and it just looks amazing what you get automatically out of the systems
are depth maps um these are notoriously hard to get especially for complex scenes such as this one uh also this one right here it's it's very complex and it handles it fairly well sorry you can even do something like ar um right here since you now have a representation that tells you how far everything is away and you have it from different views you can see uh yeah and you can even get meshes so i should be able to move that around here this is now a mesh it's not only view synthesis but you can
actually fill out the voxels which is a slightly different task and if you have pictures from all around you can synthesize kind of any view in between as you can see right here uh we're gonna switch away from the fancy videos to the paper now the special thing about this paper and this is it's in the spirit of something like sirens so sirens we've i've made a video about it and the special thing right here is it uses deep learning in a little bit of a different way than we would normally use it so first
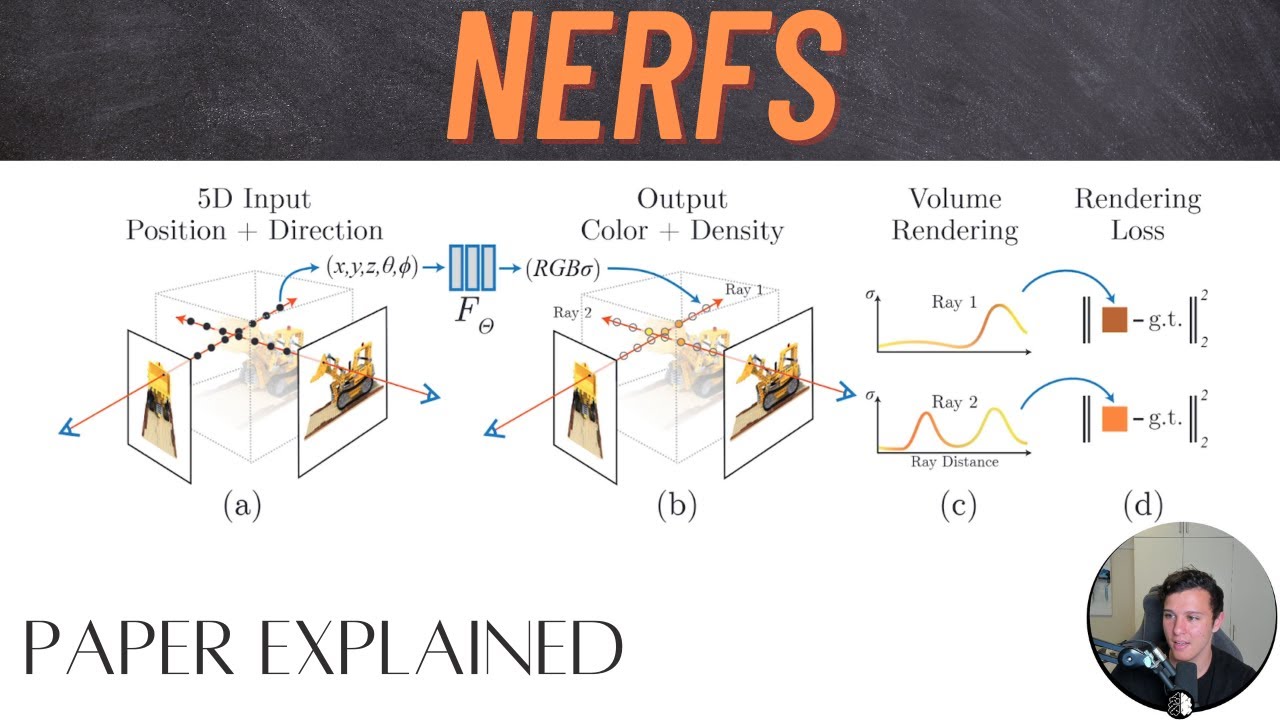
of all what does the abstract say we present a novel sorry a method but it is novel that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views so the task description is the view synthesis right synthesizing novel views also you're given a sparse set of input views so you're given you have a scene let's say you have a tree or something like this so here's a tree i know beautiful and you're given a bunch of images so maybe someone you
know stood here and took a picture so the picture kind of views in in this direction it pictures depicts the tree and someone stood here and took a picture of the same tree maybe the same person someone flew up here took a picture of that tree so you get a bunch of those maybe you get 20 or something around the tree maybe more maybe less so from these pictures you want to build a thing that can generate any view from anywhere okay and the way they do it is by optimizing an underlying continuous volumetric scene
function this is a cryptic um way but it goes along the direction of the sirens and kind of a bigger trend in i think in the ei in these in these neural rendering papers and so on which is that we want to over fit a neural network to a single data point this is really different from classic deep learning if you know if you ask someone how would you go about this problem with deep learning what they would tell you is okay i need a data set i need a data set of these you know
different scenes and the input and i have my x and my y so the input x is going to be always like you know 30 images of a scene and y is going to be the scene itself or what not like the tree or the mesh of the tree or something like this and i need this many many times so i need a data set with 30 images of i don't know a a house and the the why is the house and so on so that's my training data set then in my test data set
it can be something else right so it can be things that i now uh want to test however in this particular case this is not the case here the it is one neural network that is fit to one scene so what we have is a neural network that has a bunch of layers and all the neural network cares about is this particular scene right if we want to render a new scene we take a new neural network that's what i mean we over fit a single neural network to this particular scene we use the 30
images or so we got to train to completely over fit this neural network and the goal is going to be that the tree itself like the scene itself is going to be in the weights of this neural network so the weights of the neural network now represent the scene and this has various advantages right if the we already saw this with the sirens that very often this is a much much better representation more compact representation of the entire mesh than a any other way like if you store it in voxels or something but i hope
this is a bit clear now of course the question is what's the input and what's the output of this neural network so the input is the following imagine you have a coordinate system here so you get you get a coordinate system x y and z okay and the neural network gets two things as an input it gets as an input a position in that coordinate system which we call we call x and x is a it's actually x y z is a three dimensional vector right for example right here this is our x now and
also we get an d which is a viewing direction okay so the for example if my camera is the top camera right here the viewing direction would be um this ray here well everything's orange i'm gonna make that blue so the viewing direction d would be that okay so the the angle here we care about the angle um it's actually two angles you need to describe this viewing direction so a position and the viewing direction and the output of the neural network what does it output the output of the neural network is going to be
a color c like what color is at that particular location and the density is there even something at that particular location right so the density tells you whether there is something or not and if there is something the color tells you what color it is all right this is a really different way i want to stress that again of using neural networks there's no longer images going in and you know something coming out what goes in is a position and a direction so you ask the neural network hey neural network you in your entirety you
represent this scene you represent if you're trained well if you're over fit well you're you're over fit on the tree now i want to know at the particular location in this scene viewed from a particular angle what am i going to see so on this picture right here i'm wondering for this pixel if i send array to this location what am i going to see and the network will tell you you're probably not going to see anything because there's nothing there or if there is something there you're going to see the color i don't know
red okay so how from this you can pretty easily get a picture namely if i have my frame of the picture for each pixel i need to send a ray through the scene so i send array through the scene and what i need to do is i need simply need to query this model at each location so here here here here here here here and so on at each location i will ask the neural network is there something there and if there is what kind of color am i gonna what am i gonna see and
what you'll get is a bit of a curve thank you is a bit of a curve um so if here is your your 0 and you send the ray out into the scene and this is the density going up they have these graphs in the paper by the way i'm not i'm i'm not smart enough to come up with them by myself but they say well maybe at the beginning you're not going to see anything because there's nothing there but then you know at some point you're going to see something there is something there you
get you hit the tree right and you're inside the tree and then you're out of the tree again okay at the same time at every point it gives you color now here uh it actually doesn't matter what the color is it will still output a color but it doesn't matter and here it's going to say green right it's going to say at every point here is going to say green green green green and here i guess it doesn't matter it's probably going to say green as well but in any case what you can now do
is you can simply look at where do i hit the first time the object which is here right when the density goes up and what color is there and now i know what i need to render at that particular pixel now you can simply do this for all pixels and you got yourself an image and the neural network is powerful enough that for the same location you can see this right here it can give you different results depending on the different viewing directions so that makes it such that it can kind of depend on where
you view it from it can capture these lighting effects these these reflections and also it can capture uh transparency because imagine you have a curve that is not as clear as this one but you have a curve that is something like here so here is a one wall of a glass and here is another wall of the glass and they go up in density but they're not fully dense right and the front of the glass is maybe blue and the back of the glass is red and now if you integrate your ray along this uh
and you you integrate weighted by the density you're going to get a mixture of you know preferably blue because that's in the front but also a little bit of red right you can see that like if a ray goes through here you can handle transparency and so this is a really powerful model um right here and again there's no need for a data set other than the date the scene that is right in front of you so the goal is going to be that if in the future we want to you know we want to
make augmented reality applications we want to make games and so on you are not actually going to store a mesh or kind of a voxel grid of some scene what you're going to store is a neural network that can be queried from anywhere you want to look at the scene and the neural network will tell you what you're going to see it just happens that these things work extraordinarily well here's the process again the task you get a set of input images right here you want to find out where they're taken from so for each
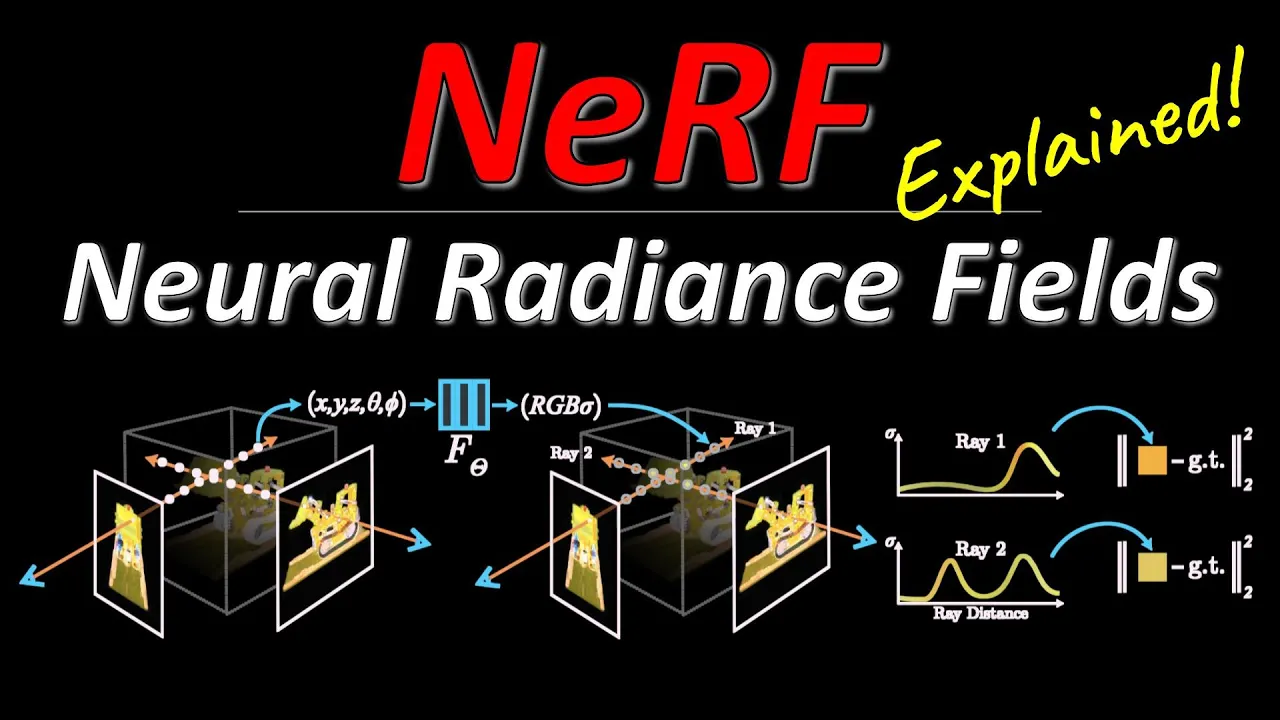
input image you need to determine where was the camera and in which direction did it look this is this is a known problem you can so all these kind of classic also structure from motion slam and so on they need to determine the camera positions uh from the pictures and so that that's a that's a thing you can take from existing research and then you want to render the new views and yeah here is i think where they get into it where oh this is yeah we represent they say a continuous scene as a 5d
vector valued function and this the vector function is going to be a neural network it has a five-dimensional input and it has a the output is going to be a color which is three dimensions and a density which is one dimension okay so the input is a 3d location and a 2d viewing direction and the output is a color and a volume density so in practice we express direction as a 3d cartesian unit vector and they say we approximate this continuous 5d scene representation with an mlp network so the network as we said this is
the input this is the output and we optimize its weights to map from each input 5d coordinate to its corresponding volume density and directional immediate color now the the only question is of course we have these images we don't actually we don't actually have we don't actually have the as a training set kind of the the the densities at that place so everything needs to be sort of grounded into the images that we have now luckily the whole process that i've described here which you see again here so if you want to render an image
you take an image you pick a pixel you shoot a ray and you sample along the ray and you ask your network what's there the network will tell you if there's something there and if so what color you're going to see the density over time and then you can render an image now you if if you already have an image right which is we are given a set of these images um if you already have one you can now calculate a loss namely what do i see and what does the network tell me i should
see right if the network is not trained yet that's going to be a pretty big loss and if you make the loss as something differentiable then this whole process is in fact differentiable that's the next cool thing about this the whole process of sending the array um sampling that position integrating over it and at the end coming up with a pixel color that is a differentiable process if of course if you do it correctly but that means we can use those 30 images or 50 or whatever we have in order to construct a big loss
right every ray so every pixel in every picture that we have defines array so every ray essentially is a data point that we can fit to so at the end we get a pretty sizable data set for the network which is going to be number of pixels times number of pictures however again it is a different problem than having a data set of many of these scenes so the whole process is differentiable and that means you can just fit the neural network to this scene you overfit it to these 30 images that you have and
that's going to be your network and this network then is going to represent the scene in its weights so the weights are the scene at the end uh there is a bit of a so there are lots of engineering tricks here uh so for example we encourage the representation to be multi-view consistent by restricting the network to predict the volume density as a function of only the location x while allowing the rgb color to be predicted as a function of both location and viewing direction so the reasoning here is that the the volume density is
not dependent on the direction like either even if something is kind of transparent it's going to be transparent it's going to be the same transparency in from different direction there's only very limited amount of materials where that is not the case right so as a simplifying concept we're going to see the transparency of the object is always the same which is kind of where stuff is is independent of where you look from it's only how stuff looks uh that is dependent so the rgb color is going to be a function of both location and viewing
direction and what they do is essentially so they input x um right here they so the the location they yank this through a network they get out two things so they first get out this density and they also get out a hidden representation that hidden representation they then concatenate with the viewing direction and that goes through another stack of layers in order to give them the color okay i think it's also you know you could do something with a transformer here and some causal masking though i'm pretty sure someone has already done this given that
the paper is almost ancient at one year of age in the machine learning world that's really old so exactly so this is the formula for new for rendering this is a technique called volume rendering with radiance fields so if you have a radiance field a radiance field is a function that tells you exactly what we train a neural network to do namely you know if i look from here and i look at that point what do i see what you want to do is you want to send a ray through the scene and you want
to integrate along that race you have kind of a forebound and a near bound and you want to integrate from the near bound to the far bound so that means you send the ray through the thing you want to integrate um this thing this t thing right here that tells you you can see the density is in here along the ray from the beginning to the point where you are that is the probability that the ray doesn't hit anything right it's the probability that the ray goes on through that room basically it's the probability of
empty space um so or you know the inverse of that like this distinguishes whether there is something or not whether the array continues up until the point t or not so you have whether or not the ray is actually at that particular point how dense that particular point is so how much stuff there is in terms of um occludence for your ray so if this is high your ray is going to stop and you're going to adopt the color that is there you can see it's this is multiplied by the color at that particular place
so you send the array and as soon as your system determine you know there's something here you're going to since this is multiplied the density is multiplied by the color your your ray is going to adopt the color of whatever is there and then after that this quantity here is going to be small because this quantity is again an inner integral that tells you whether or not the ray even reaches that location so the ray reaches the first location at which point it's going to adopt the color and after that the it even though there
is stuff right even though the density is high the ray is not reaching it so the whole formula captures all of this and as we said with a bit of nuance it like if this is not always 0 1 it can handle transparency as well and here they demonstrate again from the scene so you have two different points in the same scene but viewed from different locations and on the right they show you this is all the same point in the scene but the circle represents kind of different angles at which you can view it
from and you can see that the color is really different depending on the angle where you look from there are what do we have here there are a lot of tricks oh yeah so they they approximate the integral with like quadrature um which also has existed and they have a bunch of tricks so the first trick to really get this to work is a novel like not a novel but kind of the employment of a positional encoding now the positional coding is not the same as you might know it from transformers or something the positional
encoding here it simply means that you send the input data point which is this thing right here xyz theta five greek letter um you send that to a higher dimensional space right in a very deterministic way so if you have these low dimensional input and especially if you want to represent this this is really fine structure right here you can see that um that this this stuff right here it's it's quite fine-grained okay and so you need a way to handle fine differences between things but you also need a way to handle you know course
differences and just a single floating point number probably isn't going to do it for a continuous function like this so what you do is you send this to a higher dimensionality with these positional encodings that we know from transformers so these encodings right here they will send so what you do and so in my video on attention is all you need i explain those in detail but you construct a hierarchy of sine waves or like sine and cosine waves but we can we can just do it with with sine waves so the the lowest hierarchy
is like this and then the next thing in the hierarchy would be like double as fast and then the next thing well this is four times as fast isn't it well you get the point right it's uh so i need up down wow and then up down up down up this is not even a sine wave but but you i hope you get the point and then um you want to take a look for example your x you take your x you put it here like okay x is so this is like uh negative i
think they go from negative one to one the coordinates they have and your high dimensional output is going to be um you know this point this point this point and this point in the in their respective coordinate systems right so that's you can what this does is you can still clearly identify every point here in fact yeah you can you can identify every single point in your input space by you know looking at looking at the combination of where it is in these sine waves but it gives the network a better chance to focus for
example on details if it wants to focus on details is going to look at this scale right here because tiny changes in the underlying x is going to result in a large change in this feature if you want to focus on coarse grain stuff then you look at this where you can you know you have to move pretty far to have a change whereas if you look at this scale for coarse grained things it means almost nothing because you know if you you want to make little difference between these two things if you look at
coarse grained structure but they have as you can see like there's a lot of difference between those like this maybe zero and this is maybe negative one however um if you look at the two data points right here oh sorry about that so the same let's say the orange distance and the blue distance you can see that the two aren't so different in this representation so it gives the network the choice at which scale it wants to look at for particular positions so ultimately you're going to map this five-dimensional vector into a higher dimensional vector
and they consider like 10 10 layers or four layers of these how many of these different sine way and cosine waves they construct so again they call it positional cutting they say this is referred to as a positional encoding however transformers use it for a different goal of providing discrete representations as input to an architecture yada yada in contrast we use these functions to map continuous input coordinates into a higher dimensional space to enable enable our n mlp to more easily approximate a higher frequency functions the second thing they do is they do hierarchical volume
sampling so when we said i send a ray through the scene and then i sample along this either would take a lot of time or um it would not be accurate enough so what they do is they have actually two layers of neural network one they call a course and one they call a fine and as i understand it here is array they first sample with the coarse one at rather coarse locations and then they use that to evaluate where they should sample more let's say this thing right here has a real high density in
the course network they then sample around that a lot more maybe one here too but a lot more you know sampling around where the course network things the important stuff is they optimize both networks at the same time and that actually works out well so here you see the loss the loss is a combination now of the course network and the fine grain network and you need to optimize both even though the final view is only going to come from the fine grain network right you need to optimize both because the core screen network can
tell you where the important stuff is so the results you have already seen there are a bunch of metrics that prove that this one is really good and it can as you can see like you can handle fine grain structure right here in the microphone that others can't and it also so they say it fits into a few so one neural network of one scene fits into like a few megabytes and this is so it fits into five megabytes and this is a lot better than things that use like voxel grid representations which um i
think this other thing they compare to uses over 15 gigabytes for the same scene which and this is interesting which is even less memory than the input images alone for a single scene from any of our data sets so this is really like it's it's really it's even smaller than the the pictures right so so even if you maybe want to show this to another human it'd be better you send the train nerf than the pictures if space is a consideration though i don't know how they measure the pictures like you can probably compress if
it's different pictures from the same scene i guess there's some compression potential if you want to transmit them as opposed never mind so they'd also do ablations and the only downside here is that it does take a long time to fit one of these neural networks i don't exactly remember where they say it but they say they calculate like oh here so it's not too bad but the optimization for a single scene typically take around 100 to 300k iterations to converge on a single nvidia v100 gpu which is about one to two days so it's
a single gpu so it is you know you don't need a data center for it uh but you're gonna wait a while until you train one though you only need to train it once and then you can render new views as you please right so the idea i think is going to be that let's say you make a video game or so you're going to render this you know at your servers then you transmit the neural network to the clients and the clients can just render it out right there and yeah there's a bunch of
results and a bunch of ablations where they kind of leave away different parts and they show that especially kind of the positional encodings i think this is the positional encodings are really important as you can see on the right there is no positional encodings the view dependence is also quite important you see if there's no view dependence as you can see here you do get the fine grain structure since you do have position encodings but you don't get these kind of light effects right this is this thing here is not a different color it's simply
the fact that the line light shines on it and it's just not there here because you know all the network can do is output the same color for all directions and most directions simply don't have that reflection all right so that is it the code is available on this website that i've showed you i'm certainly going to link it tell me what you think i think this is pretty cool i know this has given rise to a lot of work following up on this i have very little overview over what's going on in the nerf
space but i think it's cool and i want to dive deeper into it thanks for being here bye-bye










![[ECCV 2020] NeRF: Neural Radiance Fields (10 min talk)](https://img.youtube.com/vi/LRAqeM8EjOo/maxresdefault.jpg)