O gravando segunda-feira Dezesseis de agosto de 2020 e um Universidade Federal de Uberlândia curso de gestão da informação disciplina análise dados quatro conteúdo análise fatorial exploratória Afe E hoje nós iremos tratar da análise fatorial exploratória utilizando o parto nas últimas aulas nós utilizamos o o spss e quem for reproduzir né então eu vou aqui abrir o carregar o anaconda tá Como compartilhar tela que com vocês também eu estou aqui carregando Anaconda e eu vou para ficar legal aqui para ficar menos pior eu vou maximizar a minha tela e a partir de agora eu não os
vejo mais então quem quiser se manifestar Abra o microfone por favor e faça um comentário tá bom eu estou carregando ainda aqui eu deveria ter reino ser usada a minha máquina mas tá bom E é alguém tinha me perguntado do do conversor de imagens lá parece que voltou tá eu dei uma olhada hoje mas tem outros também conversores de imagem gratuito também tá então Cruzes tem esse aqui ó que é o é gold Beauty Fire Crew esse aqui ó então Could Be With. Org também um converter é um conversor de imagem funciona mais ou menos
da mesma forma E quem quiser usar também funciona direitinho tá bom E aí e [Música] aqui ela tava até tentando reproduzir aqui alguma coisa usando la biblioteca que você tinha falado mas acabei não tendo tempo também mas ficou por isso mesmo então vamos lá e E aí E o que que a gente tem olha só o esse esse notebook né ele tá disponibilizado por vocês lá no no Moodle conteúdo dele em boa medida é exatamente o mesmo conteúdo que tá no slide do powerpoint tá só que o PowerPoint tá dele tá né preparado os exemplos
que tem lá a Telas a saídas as análises elas foram feitas desenvolvidas em spss e Aqui nós temos a saídas o conteúdo todo em em em Python né em jupter notebook Aqui em paz é um comentário do do exercício que vocês fizeram tá de ir um comentário extremamente positivo é que vários de vocês tem trazido coisas além do vocês estão pesquisando a respeito do que é a e do que são as bibliotecas é então estão trazendo isso e colocando isso nos comentários nas leituras nas introduções Então você é muito legal tá então parabenizo aos que
estão fazendo isso de Novo né reforçando que eu havia dia estão indo além do que do que do que é esperado que é proposto isso é muito legal é muito bom é muito salutar é bom para vocês eu acho isso ótimo é de vocês irem fazendo enairim buscando tá ganhando e apresentando devolvendo mais coisas do que exatamente eu estou apresentando por você está então o que que nós temos aqui na nada só tutorial então né O que que nós já comentamos né então é é o que Quase quando a gente está aplicando análise fatorial Qual
que é o que que a gente precisa de pensar o que que a gente precisa de preocupar O que que a gente se tratar Então quais são as circunstâncias né a partir das quais uma análise fatorial pode ser aplicada então e a gente tem por exemplo no trabalho do Lucas aí que eu passei o olho rapidamente eu vi que nós temos muitas variáveis binárias eu ia algumas variáveis categóricas tá então para a Gente tem técnicas de análise fatorial com esse tipo de variável não é a coisa mais não é a coisa mais normal não é
o que a gente vê tem até algumas técnicas que ele né não é o que a gente vai usar nessa disciplina tá então para essa disciplina nós precisamos de variáveis métricas então se a nossa base idade não tiver algumas variáveis métricas então a gente não consegue aplicar análise fatorial então nós falamos de premissas Já sentes a utilização da análise fatorial nós recomendamos lá na nas aulas anteriores né que é necessário ter correlação entre as variáveis uma coisa que a gente não comentou ainda a gente vai comentar hoje uma das premissas da análise Como é que
os dados fica uma distribuição normal da normalidade dos dados outra questão e do tamanho da amostra então né é análise fatorial ela tem um pré-requisito ela tem um pressuposto que a mostra tem que ter um Tamanho mínimo e esse tamanho mínimo ele varia em função da quantidade de itens ou da quantidade de variáveis que nós iremos utilizar para gerar a nossa análise então se eu for utilizar por exemplo é 10 variáveis se eu tiver dessas variáveis uma recomendação de tamanho da amostra ideal é que eu tenho pelo menos dez casos 10 registros para cada Pelo
menos é né o de um tamanho ideal é que eu tenho 20 casos para cada variável 20 registros para cada variável Então se eu tivesse utilizando dessas variáveis para fazer análise fatorial né Para eu explorar para eu fazer a nossa tutorial o ideal é que eu tivesse uma amostra de tamanho Oi tá de forma geral não se recomenda menos do que 100 casos que sem PC em rede isso tá uma base dados menor que esse aí não se recomenda e que Na pior das hipóteses que eu tenho pelo menos cinco casos para cada variável que
eu tiver utilizando na análise fatorial Então essas são recomendações Gerais para tamanho da amostra na análise fatorial então duas coisas que eu não havia dito ainda não é um é o tamanho da amostra para gente fazer análise fatorial Qual que é o tamanho da amostra desejada recomendado e outra é do pressuposto do pré-requisito da premissa de que as variáveis utilizadas se uma distribuição normal e hoje a gente escolhe isso aqui bastante tá então a gente tem né comentei já sobre a as Técnicas de extração de fatores os métodos de rotação Nós recomendamos também o número
de fatores a gente já comentou alguma coisa aí hoje e mais ainda conceito de carga score fatorial esse conceito de alto valor aí é inverno e comunalidades nós já discutimos bastantes também e é a partir da dos fatores que nós gerarmos nós podemos gerar extrato se certificar né de segmentar que o próximo conteúdo que a Gente vai ver na nossa disciplina que análise de clã será na análise de estratificação na análise de segmentação de que você tá então análise fatorial o método genérico dado a uma classe de métodos estatísticos multivariados cujo propósito principal e definir
uma estrutura de uma matriz de dados né então já comentei com vocês né da estrutura gente já viu lá no spss Gente analisou esse bastante nesse Material eu passo para vocês também então sempre que possível vou fazendo isso né então tem o link para o material da internet a introdução à análise fatorial em Python Então esse material esse data quente é bem é um site legal tá um site bem confiável que tem um punhado de material que tem um punhado de coisas obviamente tem um punhado de coisas pagas de cursos pagos mas tem um tanto
de coisas gratuitas também então é um site que eu uso bastante que eu Procuro bastante tá tá um tal link lá para esse para essa fonte para essa outra fonte de dados eu trago aqui né as principais bibliotecas utilizadas então pandas né é meio Universal toda vez que a gente for utilizar arquivos base de dados no Python a biblioteca pandas é é a biblioteca recomendada o matplotlib para gráficos principalmente né mas tem outros bibliotecas como Lucas a Pâmela e não me lembro quem outro tá o Felipe Neto está no grupo então Eles trouxeram já outra
B o ponto tipo de gráfico a biblioteca para análise fatorial mesmo que nós utilizamos é a Factor analyzer Então essa biblioteca e dentro dela tá a gente tem algumas outras coisas por exemplo né a gente tem a função para calcular calcular a esfericidade de bartlett E tem também a função para calcular o km OMS Ah tá então tem esse teste de shapiro-wilk aqui esse teste tá normalidade de dados o s Paio num pai o Quê que é plot a para gente analisar normalidade dos dados então tem algumas outras bibliotecas que a gente é que a
gente já traz aqui algumas delas né você já conhecem que fazem parte daquele primeiro é já do do primeiro escrito que já foi disponibilizado para vocês e algumas delas a gente vai trazendo né são bibliotecas novas e uma grande né uma grande virtude para quê e para quem trabalha com R para quem trabalha com o Palito e a gente procurar bibliotecas né A gente tem referências das bibliotecas porque quase tudo que a gente vai fazer quase tudo não tudo já tem bibliotecas prontas né Alguém já preparou o tanto de coisas nesse sentido Então o que
a gente vai fazer é usar essas bibliotecas prontas gente precisa de saber procurar Pesquisar e achar as bibliotecas então de novo né reforçando a gente está utilizando a festa lá na laser mas tem outras bibliotecas e também é tem os algoritmos de análise fatorial Implementado tá uma muito utilizada é essa aqui né talvez a mais utilizada mas tem outras também tem outras bibliotecas que geram análise fatorial no pai também tá quem quiser saber um pouquinho dela né então século arma laser bom então tem a biblioteca tem como que ela funciona tem a descrição tem as
características tem os parâmetros que ela que ela roda tem né Tem dá para ler para entender dá para pesquisar sobre uma série de coisas aqui né a gente Seguindo o link da certo análise tá então os tipos de rotação que ela tem lembra que a gente que a gente fez que eu mostrei aquele lá no spss eu mostrei essas saídas para vocês tá aqui tem mais inclusive que não spss tá então já tem implementado né mais rotações do que no próprio spss aqui no pai tá então você bem legal tá aí como funciona tá tudo
direitinho aí e os dados né o mesmo conjunto de dados aqui outra coisa que né que vocês já Perceberam e lá nos escritos de vocês se vocês mandaram na em vários deles têm depois que você instala biblioteca uma vez tá então uma vez instalada a biblioteca Eu deixei nesse nesse notebook lá eu deixei o comando do pai e o install para para vocês instalar essas bibliotecas Então na hora que você instalar isso uma vez depois não vai precisar instalar mais tá mas tá aí os scripts Então a hora que vocês antes de começarem antes de
fazerem a carga aqui Tá então precisa para quem não instalou ainda Precisa de instalar os ser pai e aspectos análise Então os comandos para instalar estão aí a nossa base da 0h bate lá do do livro do reta aquela mesma base da Dica nós trabalhamos lá no spss Lembrando que da variável X6 o x 18 São avaliações que os clientes fizeram acerca da empresa acabaste que eles deram uma nota de 0 a 10 10 eles avaliam que ele atributo aquela característica como sendo muito ruim e 10 eles avaliam Que ela característica como sendo muito boa
tá então estamos lendo né é a que eu vou executando para evento está funcionando para ver essas coisas estão acontecendo tá então estamos importando aqui as bibliotecas eu não preciso de instalar Porque eu já tenho elas instaladas né então e aqui eu vou carregar o agarbatti. Xlsx eu não sei se é o agarbatti que tá lá para vocês eu acho que não e se não Tiver tem umas coisas aqui e vocês não precisam fazer Tá o que que acontece tá olha só vou então lê o lê o arquivo aqui tá o cabeçalho do arquivo então
trouxe as três as minhas é um comentário alguns de vocês lá no primeiro exercício Às vezes você se disseram de S Red e colocaram aqui por exemplo sem Então traz várias linhas o seu arquivo tá então Normalmente quando a gente usa esse comando Red a gente quer só ver a cara Geraldo do arquivo Dos nossos dados não é como que é a cara geral desses dados nós normalmente nós não queremos trazer muitas linhas não tá mas não há problema nenhum em trazer muitas linhas também não E aí aqui né Eu quero saber né então já
algumas algumas informações gerais do arquivo né então ruim ele traz para a gente tá sem registro sem entradas do zero 99 num total de 24 variáveis então é o shape também né o DF. Shape não sei se eu coloquei aqui tá acho que não mas Lá no outro inscrito tem então DF. Cheio ele traz também para gente essa informação aqui né ele traz o número de o número de linhas e o número de colunas que nosso arquivo tem então tem mais uma forma de fazer isso aqui eu quero chamar atenção pelo seguinte né a as
nossas variáveis pra gente fazer análise fatorial e eu não tenho certeza tá então é vocês vão verificar no arquivo de vocês se precisa fazer isso mal mas a variável x 7 até a variável x 18 Observe Aqui olha só já X7 até ax18 o tipo de dados é flor a flor de 64 só que a minha variável X6 Olha o que que acontece com o X6 ela tá do tipo objeto ela deveria estar cedo tipo front também tá ela deveria ter uma nota há entre zero e dez tá Só que essa variável X6 esse arquivo
que eu gerei aí eu não sei qual que eu disponibilizei lá no mudou para vocês e essa versão ser outra versão então a gente precisa de olhar essa variável X6 Eu acho que eu já Disponibilizei certo para vocês eu acho que o que tá lá não tem esse problema mas o que que a gente tem nessa variável X6 porque que ela é do tipo Object e não é do tipo flor tá porque ela tem valor Olha só eu mandei contar quantos valores ela tem oito. 79. 39.9 mas ela tem aqui olha um excelente Então esse
valor é excelente aqui na verdade é um rótulo que tinha lá no spss que quando eu exportei para o Excel ao invés de exportar como conteúdo eu Exportei como rótulo e nesse caso aqui daí essa variável tá então né eu mandei contar aqui olha e esse corte eu tenho que ter cuidado com ele né porque ele pega cada um dos valores distintos e ver quanto que tem na minha base tá aqui essa base é pequena tudo bem tem sem registros né mas para variável X6 então tem seis clientes que deram nota 8,7 tem seis clientes
que deram nota 9.3 e esse é excelente aqui é o excelente é nota 10 então tem dois clientes que deram nota 10 mas eu não quero esse tipo de dado então o que que eu fiz aqui olha só esse comando que eu estou fazendo aqui olha tem o Data Frame lá do pandas né Tem um pandas. Replace então eu tô fazendo une Place na variável x 6 onde for tiver o conteúdo excelente eu estou trocando para o valor 10 e agora eu estou fazendo o que eu estou mudando o tipo de dado da variável X6
então eu tô passando essa variável agora para flores e ela não tem mais um texto tá então se tivesse o Texto ia dar problema ela tem um valor 10 e eu estou agora essa variável Olha só Então a hora que eu fizer isso aqui de novo olha só a variável X6 que estava do tipo objeto agora a hora que eu faço isso aqui olha a variável X6 agora ela está do tipo que eu mudei o tipo de dado da variável X6 tá então se eu fizer isso aqui agora também olha só então eu não tenho
mais aqui o excelente né eu tenho a nota 10 eu tenho dois casos com a nota 10 então eu fiz aqui uma né até agora Que eu tava fazendo aqui era só fazendo esse tratamento Eu acho que o agarbatti que eu coloquei para vocês o X6 já no médico eu acho que não tem problema não mas se tiver problema é assim que a gente modifica e eu preferi deixar isso aqui também para ter mais um exemplo por mostrar para vocês não é demais mais uma coisa que é possível a gente fazer aí Ah tá é
alguns de vocês no Exercício é vocês excluiram variáveis ou casos que tinha um valor nulo a gente tem que Fazer isso com muita parcimônia com muito cuidado ver se é isso mesmo que a gente quer tá esse esse valor nulo eu posso trocar ele por zero eu posso atribuir algum valor para ele ou eu posso realmente excluir então a gente tem que ter bastante gelo bastante cuidado quando na nossa base de dados possui tem variáveis tem casos com valores nulos tá então a gente precisa ter bastante gelo bastante cuidado para lidar com isso e às
vezes para gente não Excluir ou para gente não fazer alguma intervenção não adequada a nossa base de dados e isso pode trazer alguns problemas tá então tem que ter cuidado isso e é aqui né então agora a gente tá trazendo tá todo escrevendo né isso aqui vocês já viram também lá nos outros lugares até agora a gente não tá fazendo nada já nasceu tutorial tá então né algumas estatísticas escrevendo os dados é isso Aqui você já fizeram lá na primeira etapa na no primeiro exercício então a contagem valor médio desse padrão mínimo é o primeiro
partiu a mediana o terceiro partiu o valor máximo aí é que legal que tem essa função quando Caio e essa função ela né então é ela por exemplo eu tô pegando né o valor que o contrário 0.05 ou seja já né É aquele valor que até ele eu tenho cinco porcento dos dados e para cima dele eu tenho 95 dos dados ordenados tá então Tem né cinco porcento dos clientes que deram nota o pé 5.59 tá então cinco porcento dos clientes deram nota para variável X6 até 5:59 aí os outros 95 eles deram notas maiores
que 5.59 então essa função cantar eu aqui a outra né a mesma é da mesma turma aqui tá só que eu posso pegar um percentil específico né um plantio específico aí que eu quiser da minha base de dados aí o que que Acontece aqui a gente já começa a brincar agora num dos pressupostos da análise fatorial os nossos dados precisam seguir uma distribuição normal né então é como que a gente avalia a normalidade uma distribuição normal dos dados tá a gente avalia isso né de forma gráfica é a gente tem o primeiro Impacto visual então
é analisando o gráfico a gente não consegue afirmar que os dados seguem uma distribuição normal mas a gente consegue afirmar e segue uma Distribuição normal então né se nós olharmos o box-plot o histograma e esse qq-plot por isso então que eu importei aqui a biblioteca olha só a biblioteca qq-plot tá então desse status models porque ele faz esse gráfico para a gente o que que pros que é um gráfico para gente observar normalidade dos dados ou não então aqui a gente começa já falar de de analisar os pressupostos da análise tá então o que que
nós estamos analisando Olha só Eu estou analisando né aqui para variável X6 então o que que eu estou gerando aqui olha só eu estou gerando três gráficos tá então é né Estou criando esse parâmetro que esse Figure size de tamanho 25 e eu estou falando que tem três subir gráficos 35 lotes aqui olha só então é o suprote um não é que no o pai também a numeração Inter começa com 01 e o dois então a hora que que a gente tem aqui olha o zero o gráfico Zero eu estou fazendo um box plot aqui
esse gráfico box plot da variável X6 o gráfico um Ok olha só Axis um é o histograma e o gráfico 3 é o que que pote tá então estou fazendo aqui o quê que pilote olha só então esses três grafos Eles são muito complementares tá então quando a gente observa a variável X6 né ela está deslocada para a direita a gente vê então né os valores são altos lembram que só cinco porcento é dos valores são menores do que 5 pontos Trabalha lá há uma coisa tá eu acho que no script que tá no e
é no mudou tá se vocês forem visitar o meu aqui vai dar certo eu espero mas o script que tá no mudou o que que acontece eles é eu acho que ele tá com um errinho tá Então nesse DF aqui olha só nesse DF falta essa palavrinha caem igual e o sinal de igual falta esse pedacinho aqui do em vários deles Aqui para baixo que a gente faça eu acho que tá faltando em todos é a versão anterior Né Depois que atualizou essa biblioteca na versão anterior para histograma eu não precisava passar o Card era
por de for era o histograma tá eu não precisava passar essa essa definição para o gráfico prótese e se mudou aí de um tempo para cá e eu acho que eu não alterei atualizei o escrito tá lá no mudo Então se der problema nesses gráficos que vocês estão gerando é porque lá tá só assim olha só e eu acho que tá assim inscrito de vocês está Só o plot né sem o tipo de gráfico está est mas eu tenho que ter aqui antes do isso eu tenho que ter um em caindo igual aí este né
então tipo é igual histograma E aí então o que que a gente tem aqui né eu tô falando para o box-plot é os valores de entre uma ideias é para o gráfico box plot aí para o histograma eu tô pedindo para gerar oito caixas né oito faixas é e também aqui né a barra o x entre 10 e 11 o título desse gráfico aqui né qualidade do produto X6 e eu Y Variando entre 0 35 aqui que é que é esse eixo Y poderia mudar por exemplo a inveja 035 coloca entre 0 e 20 025
tá 0 e 20 eu gerei o gráfico de novo então Eu só mudei o que eu mudei o eixo é o eixo Y e esse gráfico qq-plot né Então como que nós analisamos esse gráfico qq-plot a gente tem essa linha vermelha aqui na diagonal e a linha azul né são digamos assim os tecidos os quentes Então se essa linha azul fugir muito da linha Vermelha dessa linha diagonal significa que essa variável está fugindo de uma distribuição normal então quanto mais alinhada essa diagonal essa linha azul estiver então é mais próximo da normalidade esses dados estão
então a gente olha aqui né quando a gente olha a distribuição visual desses braços então Lembrando que a distribuição normal é se o gráfico né seus nossos se essa e se nosso histograma por exemplo na esse gráfico aqui se ele né ele é Parece né se traçasse uma curva normal isso parece ensino aqui então a gente vai olhar depois né a assimetria né então se eu dobrasse esse gráfico aqui tá em relação à Média a gente teria figuras perfeitamente sobrepostas ou não então quando a gente está falando de uma inspeção visual a gente tá olhando
assim mais ou menos o nosso histograma se parece com sino ou não né então a gente olha que esses graus três gráficos né as leituras deles são similares Observe o Histograma né o histograma Olha aqui que eu copiar aqui de novo O que que a gente tem olha só a gente tem um histograma é o nosso histograma olha os dados eles estão né concentrados e no extremo no do lado direito tá vendo Então os nossos dados estão concentrados do lado direito quando a gente observa isso no nosso o box-plot esse Box plot ele está no
lado superior tá vendo Então lá de superior lado direito Então essas coisas Esses gráficos né embora sejam gráfico diferentes com estatísticas com medidas diferentes mas eles equivale tá então eles têm equivalências né se o nosso é histograma tivesse do lado esquerdo né se ele tivesse do lado esquerdo o nosso box-plot estaria no lado inferior aqui tá e se tivesse né no meio né Se fosse no meio o box-plot obviamente estaria no meio assim que a gente vai ver então quando a gente olha nossa variável X6 ela visualmente né ela sugere que tem Algum ligeiro desvio
da normalidade mas nossa daqui a pouco nós vamos continuar a nossa análise para ver né exatamente se tem ou não tá bom então aqui a gente fez para variável X6 aí fizemos aqui também para variados X7 a mesma coisa X7 né Então olha aqui os nossos dados da atividade de comercialização notas bem mais baixas estão vendo Então é o histograma né ele tá entre praticamente entre 2 e 6 e olha o que que acontece com o box-plot ele já tá bem na parte Inferior porque nesses gráficos são equivalentes Sim nesse primeiro gráfico aí de do
box plot essas bolinhas aí que está no canto superior e inferior São saltilar outline exatamente tá aí como que eu defino out lá naquele material lá em produção análise dados eu falei para vocês que tem até a forma lá de né eu posso variar aquela aquelas formas da Qual que é o limite para eu considerar out lá ir ou não mas naquele script que que vocês têm na de todos são a raiz Manipulação de dados né Inclusive tem lá o cálculo Qual que é o limite o que que não é porque que tá esse traço
aqui nesse ponto aqui tá sei se vocês lembram que eu achar aqui onde que tá a introdução [Música] é esse aqui a sessão manipulação de dados e E aí E aí E aí E deixe-me ver se esse aqui e esse aqui não é E aí e esse aqui ó E aí o substantivo que eu já te mostra Filipe é esse aqui um chá E olha como você calcula aqueles Limites Tá vendo e consegue ver olha só então o que é que a gente tem olha a fronteira interna Fronteira externa essa aqui é que parecer meio
complexo né Né Não olha só o que que você tem tá você tem o a Barrinha do meio é a mediana é o segundo quadrante a Barrinha inferior é o primeiro quadrante a Barrinha superior é o terceiro quadrante tá vendo Então o terceiro quadrante acontece aqui G1 É isso aqui é lá de análise de dados Onde está realizando mas eu acho legal que aqui a gente tenta dar contexto para isso tá bom Então olha o que que a gente tem olha só a a nossa caixinha tá o box-plot que a gente está fazendo essa é
a Caixa tá vendo ele aqui tá na horizontal quando poderia tá na vertical é a mesma coisa então a gente tem aquela linha do meio é o segundo quadrante a linha de baixo é o primeiro quadrante a linha de Cima é o terceiro quadrante quando a gente faz esse valor o terceiro quadrante tá o valor do terceiro quadrante lá nos nossos dados por exemplo olha só se eu te mostrar o que olha só Oi gente gerou isso aqui em cima Então eu tenho aqui olha só para variável X6 então para variável X6 O que que
a gente tem aqui olha só o valor do primeiro quadrante é 6.57 o valor do terceiro quadrante do que três é 9.10 então a Diferença interquartil é o valor do terceiro quadrante do percentil 75 - 25 é 9.10 - 6.57 então é essa diferença 9,10 - 5.57 é esse valor nosso aqui olha só é esse intervalo e QR é o intervalo interquartil tá vendo um OK aí como que o cálculo Olha só aquele bigode lá de cima tá como que o cálculo o bigode aqui de cima e o de baixo ou de cima Então olha
só é 1,5 X o intervalo interquartil interquartil nós acabamos de calcular que 3 nem ser um e o outro superior né é 1,5 vezes o intervalo interquartil Então a gente tem aquele bigode lá tá E aí a gente tem aqui o que a gente chama né o spss inclusive ele coloca esse outline era aqui tá esse áudio lá até 3 vezes no intervalo interquartil ele coloca esses valores aqui como bolinha aqui ó aí Se tiver altos lá extremo tá acima de três vezes o intervalo interquartil esses Valores aqui o por exemplo spss Coloca eles como
asteriscos são valores muitos temos muito alto tá mas é viu que é fácil de fazer a conta me conta qual que é então 1,5 e QR três e QR tá então aí eu tenho a ideia desses desses limites aqui tá bom e ficou planetinha o ITA aproveitando também o script aqui né Depois eu sugiro vocês dar uma olhada também olha só nessa Questão eu acho aqui em de normalidade dos dados Olha só de assimetria de curtose para vocês entenderem né isso aqui tá vocês dominarem isso aqui tá Então nesse material nesse primeiro material assimetria a
esquerda simetria menor do que zero né É normal a simetria direita maior do que zero então onde vocês entenderem saberem olharem para as figuras olharem para o histograma e já saber do que se trata já veio Distribuição dos dados Isso aqui precisa fazer parte do repertório de vocês tá então esse material de seus são analisados que eu coloquei para vocês eu sugiro vocês exploraram entender isso bem que é bem útil é muito útil tá então aqui olha a relação entre box-plot histograma tá vendo Então tem até a figurinha aí para ilustrar para ajudar para vocês
olha só beleza bom então continuando no nosso caso aqui sim alguém quer falar não falei beleza Show de bola gigante de leizinho então eu fiz isso olha só eu gerei as figuras aqui para todas as variáveis que nós vamos utilizar a análise fatorial X6 X7 X8 x 9 10 11 12 13 14 15 16 17 18 tá então para aquelas 13 variáveis eu gerei aqui o gráfico das três variáveis tá então é com gráfico a gente consegue fazer só uma inspeção visual Então olha que análise analisando as figuras é possível Observar em relação a variável
X6 qualidade do produto e os valores são altos sendo atributos bem avaliado pelos clientes e não se observa a presença de auxiliar em relação a variável x 7 atividade como esse as notas são baixas em a avaliar pelos clientes é possível observar que a presença de Alt Liars e nos dois casos pontos plotados no qq-plot se distanciou um pouco da linha indicando possível desvio da normalidade porque a gente Analisa lá o X6 X7 é a Gente vê que em alguns lugares do X6 e do X7 e olha só X6 então lá no na na parte
superior tá então tem aqui olha as os pontinhos azuis vão se distanciando da Linha Vermelha em alguns outros lugares também a mesma coisa para o X7 tá vendo então lá no na no finalzinho lá da avaliação né então alguns pontos vão se distanciando mas isso aqui é só uma análise visual que a gente está fazendo né a gente não consegue travar se esses Essas variáveis elas realmente fogem durante transmissão normal ou não a gente consegue ver que a possibilidade para gente olhar mesmo aí a gente começa a discutir agora normalidade dos dados Então a partir
da análise gráfica é possível observar possíveis violações Mas a gente não trava que tem uma violação contudo o teste devem ser conduzidos para certificar essa possibilidade Existem muitos teste que pode ser utilizado para Avaliar o quão a função de uma determinada amostra se parece com distribuição gaussiana normal escova normal cada um dos essa abordam diferentes pressupostos e aspectos nos dados então né a gente tem né Cada teste retorna ao menos dois parâmetros A tá a estatística para gente testar e o valor é E aí a gente vai né considerar un Peu né então se o
perfil menor que um Alpha que a gente estabeleceu nós rejeitamos a zero ou seja nós já estamos que ela que A distribuição da variada a segunda exibição normal esse o nosso perfil o maior que eu não tem um determinado Alpha é nós falhamos em rejeitar h0 ou seja Nós aceitamos que a distribuição Segue uma distribuição normal Então a gente tem testes mais brandos até testes mais robustos mais severos tá então é e para um indício já de normalidade dos dados é curtose e assimetria então o que que eu estou fazendo aqui com esse comando olha
só a curtose e Assimetria elas vão nos dão indícios de que se os nossos dados seguem distribuição normal ou não então tem aqui né O que que eu criei eu criei um Data Frame aí eu creio que um Data Frame esse Data Frame Nossa ele tem o que ele tem o na o nome das variáveis então tem seis sete oito para cada uma dessas variáveis eu mando contar então né todas elas Aqui tem 100 casos e eu gerei a curtose Então olha só eu peguei para cada uma e dei o nome para coluna Então Essas
três primeiros parâmetros aqui olha só eles são os nomes das colunas que eu estou criando eu estou criando uma coluna kone o outro Economy curtose e outra Economy assimetria Economy n eu mandei contar quantos casos em cada uma dessas variáveis a curtose eu pedi a estatística kurtosis tá então para cada uma das variáveis EA simetria eu pedi a estatística simetria Esquilos está então tem curtose e assimetria kurtosis skinnys então kurtosis curtose E skinnys esquinas assimetria então eu gerei aqui olha só a curtose e assimetria para cada uma das nossas variáveis tá então a analisando a
assimetria e curtose a gente já começa a ter um indício de possíveis problemas nos nossos dados tá em relação à distribuição normal então o que que a gente pode observar tá olha só quando a gente observa os nossos dados a variável X6 tá então ela tem a curtose - 1.13 é uma das maiores kurtosis tem outra variável com valor grande e sete oito nove dez 11 12 13 14 15 16 17 18 é a maior curtose que nós temos é da variável é e da variável X6 ida e na simetria a maior assimetria é da
nossa variável o X7 então o que que a gente tem de regra empírica tá se a gente tiver curtose se a gente olhar para curtose e nós Encontramos valor depende da do tamanho da amostra Depende de outras coisas tá mas se a gente achar curtose aqui maior do que 8 e assimetria maior do que 3 tá então se olhar para curtose e achar curtose maior do que 8 e acharam a simetria maior do que 3 certamente essas variáveis elas fogem da distribuição normal elas não seguir a distribuição normal a nossa hipótese nula sempre é h0
né a variável por exemplo X6 Segue uma distribuição normal E a hipótese alternativa para cada uma delas acho que seis não Sega diferente de uma distribuição normal tá então o primeiro indício aqui tá Quando a gente olha é de assimetria e curtose né maiores que mais ou menos tá então em valores absolutos aqui tá tanto positivo quanto negativo aqui tá então se os valores são acima de mais ou menos oito e mais ou menos três mais ou menos oito para curtose mais ou menos que 10 para simetria e de cara a gente já ou para
Esses dados estão tão bugado mas é a forma mais Branda mais amena de nós observar mos assimetria e curtose se não passar nessa não passe mais nenhum outro teste que a gente vai fazer tá Então essa é a forma mais Branda mais amena mais é digamos assim mais maleável que existe para a gente analisar assimetria E curtose então quando a gente olha em princípio não tem nada muito gritante não tá mais uma forma da gente olhar isso é a gente Fazer esse Z de assimetria um de nós analisarmos esse usei né de assimetria E usei
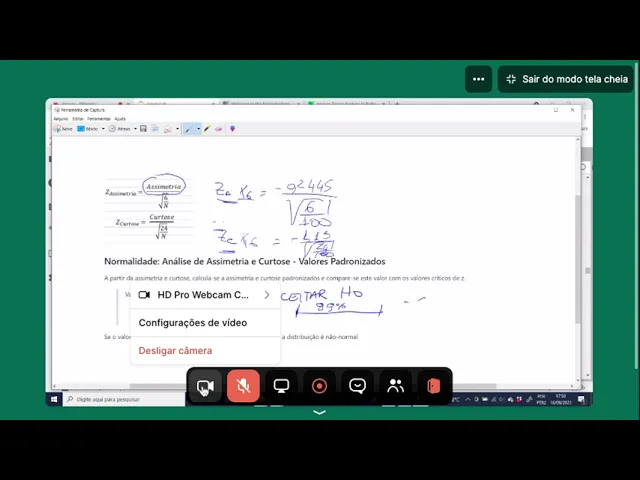
de curtose já é um pouco mais é digamos assim né já é um pouco mais hard pelo que não multi mas é um pouco mais hard tá então o que que nós temos com esse teste olha só a gente pega o valor da simetria e a gente pega o valor da simetria por exemplo né lá no nosso no nosso é X6 Então valor da simetria por exemplo é menos 0,24 então o que que a gente faz olha só eu pego aqui o menos 0,24 menos 10 então Z da simetria da variável x 6 = -
0,4 10, 2445 0,24 45 dividido por raiz de 6 sobre NN é o tamanho da amostra sobre no nosso Caso aqui sobre sem então para curtose a mesma coisa né seria o z e curtose da variável X6 seria o que é igual a custose lá o valor da curtose o que é quanto menos 1,13 e é = -1 - 1,13 é dividido por raiz de 24 sobre sem então nós iríamos achar né o Z para cada uma das variáveis para ti seres para Este 7000x Oi e para cada uma delas nós iremos observar aí nós
comparamos por exemplo se esse valor dizer que nós achamos aqui olha só tá tantos vezes a simetria quantos eles curtose se algum deles for maior do que 2.58 e considerando o intervalo de confiança de 99 ou seja uma Alfa = 0,01 tá se isso acontecer se isso ocorrer nós podemos afirmar que a nossa variável não segue uma distribuição normal que ela foge da normalidade tá isso né Nesse caso o que que nós gostaríamos que acontecesse tá nós gostaríamos de aceitar e nós gostaríamos de aceitar h0 tá então o nosso desejo é aceitar h0 tá então
para a gente aceitar h0 né eu aumentar o o alfa o intervalo de confiança interessante né A minha região de aceitação ela fica maior ela fica com 99 por cento da área tá então porque eu quero aceitar h0 Então nesse caso né como eu quero aceitar h0 a Desse intervalo de confiança mais liberal mas é o é esse né o alfa = 0 um intervalo de confiança 99% só um instantinho só E aí então a gente tem né considerando a outra situação que que nós temos nós temos então né o alfa igual a 0,05 o
intervalo de confiança nesse caso seria de noventa e cinco porcento né então aqui eu estou sendo mais rígido Olha só porque se eu Z e nós calculamos Lá ele foi maior do que mais ou menos 1,96 Então nesse caso nós já rejeitar íamos a normalidade dos dados tá então a gente faz isso para cada uma das variáveis né que a gente tiver utilizando e a gente tem outras espécies aqui que eu trago então tem esse teste o K2 D'Agostino então a gente eu tô colocando aqui numa hierarquia tá então eu tenho Primeiro só simétricos those
depois assimetria e curtose padronizado depois o teste K2 D'Agostino depois o KS Itaperiu tá eu KS está peru e o que eles são mais ou menos aqui Vale e quando eu tenho uma mostra menor uma amostra pequena o shapiro-wilk é mais indicado quando eu tenho amostras maiores o KS é mais indicado Tá mas é esses dois testes são testes de a bem mais robustos e rigorosos então para variável ela seguir uma distribuição normal ela tem se parecer muito ela tem que ir né respeitar muitas características da normalidade Aqui para baixo então né a Gente fez
esses testes e o que que eu tô fazendo aqui olha só então estou calculando né É aqui olha só eu estou calculando uma variável que se chama Z de curtose tá vendo Então eu estou utilizando aquela forma olha só é a curtose do Data Set normal que eu criei um data 7:00 né que é esse Data Set aqui eu criei esse Data Set Olha só E eu chamei ele de normal ele tem as variáveis tenho.na curtose e assimetria e agora estou calculando mais Duas variáveis Olha só o z e curtose e o z de assimetria
para cada uma dessas variáveis nós acabamos de criar aqui tá ansioso rodasse isso de novo Olha só se eu fizer agora eu vou rodar de novo vou até copiar isso aqui Para não misturar tá eu vou copiar aqui eu vou colar aqui ó e vou rodar de novo então agora olha só eu já tenho o z de curtose e o z de assimetria Olha o que Que acontece agora né com a variável X6 Olha só usei menos 2.31 com qual o valor que a gente está comparando com mais ou menos 2.58 ou 1,96 então com
intervalo de confiança de noventa e cinco porcento Esse valor já tá superior ao envio 96 mas ele tá ainda inferior ao 2.58 tá e a variável x 7 agora olha só 2.69 então 2.69 inclusive está acima do 2.58 então avaliar as variáveis X6 ex7 né então sugerem uma Considerando o z de assimetria E usei de curtose ou seja curtose e assimetria um drone zados as variáveis de 6 x 7 elas fogem da normalidade uma pela cortozi outra pela simetria As outras todas estão dentro de valores aceitáveis Ok então a gente vai fazer mais os testes
nós fizemos aqui olha a gente vai fazer o teste É tá dois D'Agostino o ks e o shapiro-wilk tá então agora eu estou criando né sim te rompendo aqui quando você tá Procurando o intervalo na coluna você procura visualmente certo se fosse uma tabela muito grande não tem nem como aplicar o wi-fi que o fora quer dizer que ele vai em cada linha para ver se vai dar você pode por exemplo esse normal aqui ele é um ele é um Data Frame então você poderia lembra daquele Lopes que a gente falou aqui na eu poderia
selecionar só que Ah entendeu eu poderia fazer um forma mas eu poderia Também olha só tem esse comando aqui ó eu acho que eu tenho aqui deixa eu ver o que eu coloquei aqui tem E aí a Vitória poderia fazer isso aqui ó e esse comando aqui por exemplo nesse nessa base Nossa aqui e o mais não Oi Espera aí ó E aí a Preguiça de escrever ó ó é só que o meu Data Set agora ele chama normal então ao invés de DF é normal aquilo ao invés de F normal aí e aqui os
e curtose e eu teria que colocar um hora aqui também tá que pode ser maior ou menor então eu vou pegar maior do que é por exemplo nesse caso que eu já sei mas vou pegar teria que pegar você é maior do que 1,96 Ou menor do que menos 1,96 tá então aqui por exemplo né eu poderia pegar aqui olha que é menor é o que menos 1.96 Oi beleza e deixar que vamos lá casas decimais aí aqui ó e ele já trouxe só o que é menor tá vendo é mas boa sua ideia da
dá para você fazer e dá para você fazer essa análise Já Gerais já é já é porque aqui a gente não entendo muitas variáveis da trabalho e a corre o risco de errar a gente colocar algum alguma condição aqui de cara a gente já consegue fazer garantir que que a gente é cercou todas as possibilidades tá aqui eu só testei o menor mas eu poderia colocar uma uma outra condição aqui né o War e testar também o maior que mais 1,96 por exemplo lá Para simetria e para curiosas fazer uma condição maior a beleza certo
obrigado e aqui olha só então eu calculei né esse valor aqui tá Então ela é o normal que é o D'Agostino então eu tô utilizando a função normal teste eu estou calculando P valor para esse teste que tá aqui eu estou criando o a estatística dks estou chamando a função a rotina cá STS estou calculando P valor para o KS estou calculando A estatística w shapiro Wilk estou calculando o p-valor para ela que então esse conjunto de código aqui tá eu estou fazendo isso para cada uma das variadas tá então é para cada uma das
colunas Olha só eu criei uma variável que eu dei o nome de colunas aqui em cima tá então para cada uma dessas colunas que sente 78 eu estou e esse bloquinho de código aqui para eu calcular né é o K2 D'Agostino ksw e os respectivos P valores para cada Uma dessas variáveis tá então é isso que eu tô fazendo aqui calculei e agora eu tenho aqui então olha eu calculei né e o meu Data Frame que eu salvei isso esse dataframe é que eu chamei de normal então eu tenho cada uma das variáveis eu tenho
n Eu tenho curtose eu tenho simetria aí tem o z de curtose Used a simetria eu tenho tá doido Agostinho no que esse normal aqui e o p-valor não é p valor menor do que 0,01 ou menor que 0,05 eu estou rejeitando a hipótese nula que é de normalidade estou aceitando a hipótese alternativa quednau normal Então olha para X6 né não Normal parte 7 não normal X8 X9 não o X10 X8 X10 Não normal x13 não normal e é a 95 ax17 também fugiria da normalidade dos dados então nós teríamos uma duas três variadas quatro
variáveis que surgiriam a distribuição normal as duas Que nós já havíamos visto e mais mais três que apareceram que quando a gente olha o KS Olha o que que acontece com KS nenhuma das variáveis seguiu uma exibição normal Então esse KS é um teste bem mais rigoroso bem mais rígido tá então nenhuma delas iria a utilizando o w né ele se aproxima mais aqui do Cardoso D'Agostino tá então algumas seguiram exibição normal outras não mas enfim né considerando todas a os testes há 6 dias 7 são aqui em princípio né Elas mais forte na distribuição
normal Então o que nós testamos aqui olha só eu testei transformação para variável x 7 então eu criei uma log dessa variável x 7 aí eu fiz uma transformação nessa variados para ver se a variada transformada seguir uma distribuição normal aí eu te fiz o teste para ela então depois dela transformada né agora OK então ela é com essa transformação log tá ela é essa transformação foi adequada essa variável transformada ela Passou se uma distribuição normal então né eu tenho várias transformações que eu posso fazer inversa raiz raiz cúbica é log aí depende fala assim
ah no R tem um pacote que eu que que ele ele faz vários testes e e e qual que seria melhor transformação para cada uma das variáveis aqui no pai que eu ainda não encontrei até comecei a implementar mas falta-me tempo para implementar a rotininha que eu em forma variável né e eu faço uma série de transformações e Apresentaria qual que seria melhor distribuição no pacote estatístico stata Tem uma função Zinha também é bem legal que testa todas as variáveis e todas as possíveis transformações e já me sugere qual que seria melhor transformação para fazer
aqui no nosso caso a gente pode fazer isso meio Na tentativa e erro mesmo ou se algum de vocês aí descobrir em uma forma de fazer isso também é muito bem-vindo tá então a variável x 7 nós estamos trabalhando com ela né eu Criei uma nova variável e a partir de agora estou trabalhando não mais parte 7 mas com haste 7 transformada tá então Essa é uma das coisas não é um outro pressuposto que a gente explorou muito lá na no spss é que os dados tem que vários pares variáveis Tem que apresentar correlação então
aqui o que eu estou fazendo é calcular a com relação tem essa né é essa função aqui do pandas né então eu tenho data Freire E eu estou fazendo há correlação entre essas variáveis tá então eu tenho aquela Matriz de correlação que nós geramos lá no spss diagonal principal vale um valores fora da Diagonal é que a gente avalia com relação aqui a gente tem só os valores da correlação mas eu não tenho se são estatisticamente significantes ou não né então tem na diagonal que tenha com relação e valores fora da Diagonal são é a
diagonal valor um com relação a variável com ela mesmo Valores fórum diagonal a correlação entre as variáveis mas com esta é e essa função aqui do pandas né Eu não tenho aqui a o p-valor para eu saber se essas relações são estatisticamente significantes ou não mas eu tenho outras formas de fazer isso olha só então aqui eu tenho qualquer desvantagem tá eu tenho essa URSS lembro que que é o RS a biblioteca foi importei como RS a gente importar a biblioteca aqui que chamei de ir RS que é o que for search pai então o
Wi-fi pai tem uma função que é com relação só que como que é a saída desta função como que ele que ela já era para gente olha só ela gera saída É nesse formato aqui olha só não é em forma de exatamente de Matriz ela gera para cada parzinho de variável ax6 AX7 para X8 X9 geram o r a correlação e gera o p-valor então aqui a gente consegue ver quase que serão seria estatisticamente significante ou não então é uma outra forma né dê a gente Olhar a correlação é essa função aqui ela já era
o par aos pares de Formação tá não na forma matricial mas a correlação é a mesmo é outra forma Então a gente tem esse né O ST Qual que é a biblioteca ST que nós importamos a biblioteca spa o s se pai então nós importamos né dessa biblioteca nós importamos táxi é ST então tomar cena que tem várias formas e não se limitam a essas aqui tá tem outras bibliotecas tem outras funções Que calculam com relação ao calculou as estatísticas também então tô mostrando aqui algumas formas fazer isso essa outra como que ela faz olha
só ela já era para gente eu tenho que falar os pares zinhos que eu quero então entre estes este série então eu pego o valor da com relação então o valor da coração e menos 0,15 tá já com hastes é transformada aí eu tenho como gerar também esse o p-valor que foi gerado né então eu tenho que tar com relação e o P-valor Então tem que o p-valor foi gerado tá então o essa né o essa função piercing e ela gera um vetor cuja primeira posição é a correlação eu erre e a segunda posição do
vetor olha no sol posição zero e a posição um e a posição é o p-valor eu poderia até gerar isso aqui na mesma gerando a saída em duas em duas variáveis ao mesmo tempo então o que que nós temos então observando as relações Entre os pais variar mas é possível constatar a existência que nós já fizemos lá no spss em variante vários pares variados mas para gente ter certeza a gente faz o teste de infelicidade Marcos eu já falei muito lá no spss também né quando a gente tava fazendo lá então aqui olha só né
naquela biblioteca Zinha lá que nós importamos então né estou chamando Assunção bartz essa função barca né eu analiso né eu pego as variáveis que eu estou Analisando e observo se a matriz de correlação não é isso que o teste de esfericidade de bartlett é só se a matriz de correlação é igual a uma matriz identidade né então se for igual a matriz identidade os nossos dados não tem correlação e portanto não são adequados não são úteis A análise fatorial então rodamos aqui o Teste este dá esse felicidade barkley hipótese zero hipótese hipótese nula h0 que
a matriz que dá corações pode ser a Matriz identidade e a hipótese alternativa que não é então aqui o p-valor igual a zero que nós encontramos nós estamos aceita rejeitando a hipótese nula e aceitando a hipótese alternativa ou seja nós estamos aceitando que a matriz de correlação seja igual a matriz identidade estamos aceitando a hipótese alternativa estamos afirmando que existe vários pares de variáveis com correlações estatisticamente significantes com correlações diferente Quiser então tá aqui a leitura disso é o próximo passo então né é a gente analisar o km o MS a Então olha o que
o que que a gente tá e função eu estou eu estou enfocando tá eu estou invocando a função km ó e essa função km ou ela retorna dois paramos né ela retorna ao vetor MS a e ela retorna O valor km ó lembra que o km ó eu tenho uma estatística geral e o MS a Eu tenho um MS a para cada uma das variáveis as formas estão aqui bonitinho tá igual tá Lá nos slides então quando a gente já era né o MS a e o km ó aí a gente tem que o km
ó Deserve vocês tal qual como era lá no spss aí o cá é melhor igual a 0,6 de 05 a 06 é né é um ajuste mal mas aceitável menor do que 05 inaceitável de 06 e 07 razoável é mais o é isso aqui o nosso ajuste nós carioca e ele tem então vetor MS a quando eu fiz essa função né eu Gero esse diretor aqui olha eu tirei esse vetor aqui ó esse a rei tá só que o que que acontece né É do Jeito que tá aqui é difícil da gente ver então eu
fiz esse esse outro bloco aqui olha de comando esse outro bloco foi só para atribuir né para variável X6 Qual que é o MS a parte 7 Plus x 8 e lembrando né que aqui no nosso caso olha só é igual né os valores equivalentes ao que nós encontramos lá no spss E lá nós não tínhamos transformada variado o sucesso por exemplo tá a variável 15 o MS a dela lá né Vocês lembram era de zero. 30 e Pouquinhas tá então é valores de MS abaixo de zero cinco pode sugerir a necessidade e não incluir
essa variável na nossa análise fatorial tá então tá aqui é leitura tá aqui como que a gente interpreta não tô falando né entrando demais em detalhe porque foi exatamente o que a gente já fez lá no spss aqui eu estou mostrando como que a gente calcula tá E aí ok nós passamos então pelos pressupostos nós vimos a nós vimos algumas coisas já né Nós vimos Normalidade dos dados nós já comentamos o tamanho da mostra nós já falamos com relação nós já falamos o km ó e nós já falamos do MS a agora a gente vai
rodar análise fatorial exploratória tá é fator é exploratória análise Então desse espera né então eu estou chamando a função f a lembra da biblioteca lá que nós importamos olha só é UEFI a é a o factor análise Então eu estou chamando esse Factor analyzer dfa é a função né a Biblioteca para gente fazer análise só uma das bibliotecas tem outros tá mas é uma das bibliotecas para gente fazer análise fatorial aqui no Python Então eu estou invocando aquela biblioteca tá e o que que a gente tem aqui olha só o que que ela retorna para
gente tá Ah então né eu estou executando a análise fatorial eu estou fazendo a rotação varimax tá então eu já estou falando que a Rotação que estou fazendo the varimax aqui tem um detalhe que eu já falo a priori quantos fatores eu quero reter eu quero gerar então eu já estou falando que aqui eu vou reter cinco fatores e o método é por componente principal igual extração dos fatores igual nós fizemos lá no no no spss tá estamos utilizando os mesmos parâmetros a nossa questão aqui né quantos fatores eu vou utilizar daqui a pouco eu
mostro pra vocês que a gente Pode voltar a gente né eu poderia colocar aqui por exemplo dez fatores e rodar com os 10 fatores e analisar a saída com os 10 fatores tá aqui eu coloquei 5 porque a priori né Eu já sei que cinco é o indicado mas aqui para baixo eu mostro para vocês aonde que a gente poderia e quantos fatores nós precisaríamos geraram não então aqui eu gerei consinco e eu Gero aqui olha só né eu gerei criei essa variável é feia e essa minha variável feia ela tem o Resultado da análise
fatorial que eu gerei e uma das coisas que essa análise gera são as comunalidades né então eu estou atribuindo para esta variável comunalidade os valores da comunidade cada uma das variáveis só que da mesma forma mais difícil da gente visualizar tá vendo Então eu gerei aqui tá da X6 X7 X8 o que eu estou fazendo com esse bloquinho aqui é só gerar uma saída mais amigável para o que a gente gerou tá vendo e não é Exatamente igual spss mas eu tenho cada uma das variáveis e tenho a comunalidade cada uma das variáveis aqui mas
as pessoas em cima sim desculpa te não tem problema fica essa comunidade comunalidade como nós falamos lá na aula passada né ela quantidade de variância de variabilidade que cada uma das variáveis compartilha comunga com as outras variáveis na análise fatorial a comunalidade ela varia entre 0 e 1 dá um ponto de análise de medida é meio quanto Mais baixo pior quanto mais alto melhor tá então é a comunalidade é o que ela Compartilha o que ela comunga de variância de variabilidade com as outras variáveis e a parte que ela não compartilha que ela não comunga
é especificidade EA específico dela então comunalidade mais especidade igual a um foi o Felipe que perguntou não foi infinito e não não é o Pedro a Pedro é Pedro é não aula passada eu explorei isso Bastante e eu agora eu falei mais rápido mas eu sugiro você dá uma olhadinha lá na aula passada e aí lá eu detalhe lei bastante com a forma desenhei expliquei tem vai ficar mais caro eu não vou repetir tudo agora mas assim eu falei geral então do nada aí acho que ela é vale a pena você dar uma olhadinha lá
beleza valeu show de bola é até falaria agora Pedro mas para gente conseguir terminar o conteúdo e não ficar no meio aí se pairar em dúvida se você tiver Dúvida após vê-la aí você pode me perguntar de novo que eu terei maior prazer em falar de novo tá tá certo mas essa breve explicação que você deu já deu uma esclarecida beleza meu amigo então a gente viu aqui tem explicação tem como é né então a gente tem aqui os altos valores os o que a gente quer analisar o bloco aqui debaixo também olha todo esse
bloco que eu fiz aqui é só para gerar uma saída mais amigável tá É só um instantinho E aí e é aí pessoal é essa esse bloco inteiro aqui olha só é só para gerar essa essa essa saída mais amigável aqui tá então né É só para dar o print para coisa ficar bonitinha para ter uma saída parecida com aquela que nós temos lá no spss tá então o que que nós temos aqui olha só nós temos 13 componentes né Cada vaso nós temos 13 variáveis de entrada Cada variável de entrada já eram os componentes
tá então isso aqui também eu explorei bastante na aula passada e vale a pena vocês darem uma olhada na aula passada Ok A ideia é exatamente a mesmo só que lá nós geramos uma saída no spss aqui eu sou gerando a saída no pai então tá mas então olha só eu falei né eu já passei um parâmetro aqui em cima falando que ia gerar cinco fatores tá vendo Então assim a priori eu não sabia agora eu sei e entre 11 e 13 porque né é 13 e A quantidade máxima de variáveis que a gente tem
Tá mas como cheguei a esse cinco né esse cinco Se eu não soubesse a priori eu poderia ter gerado aqui por exemplo olha só vou gerar aqui ao invés de cinco eu vou gerar ideias tá tem três variáveis vou gerar 10 fatores tá Vou pedir para gerar 10 então executando de novo alguma coisa não vai mudar a única coisa que vai mudar é essa saída aqui que a gente vai gerar agora olha só Bom então o que que a gente tem aqui agora olha só Então observa em que agora olha só eu tenho 10 10
linhas 10 componentes que eu tenho aquelas variáveis adicionais depois da votação só o que que eu pedi sim olha só eu tinha pedido cinco porque um dos critérios uma das regras de uma das possibilidades retenção é nosso e termos os componentes os fatores cujo alto valor alto valor seja maior do que um então maior do que um é o quinto olha só É o quinto componente tá porque eu sexto já é 0 0 0 54 0/44 mas porque um porque nós estamos né análise fatorial é uma técnica de redução de dimensionalidade dos dados nós temos
13 variáveis nós queremos agrupar essas variáveis em Componentes em fatores Então o que nós estamos fazendo reduzindo de 13 para um número menor e O que significa o quê que esse fator que eu estou metendo este componente ele não mínimo ele explica a variância ou a variabilidade a variância De uma variável que vale um então se ele não explicar nenhuma variável para quê que eu vou retendo então uma das possibilidades retenção né reter valores alto valores ou reter os componentes os fatores cujo alto valor seja maior que um então aqui nesse caso né é o
componente cinco então por isso que eu voltei aqui em cima e eu passei o parâmetro ao invés de ideias eu passei um parâmetro cinco eu estou gerando cinco componentes porque eu estou Utilizando o critério do alto valor maior ou igual a 1 então executei de novo a e agora a minha saída ali embaixo ao invés de ter aquelas 10 linhas completas eu tenho agora e a cinco linhas nós geramos Olha só então o que que nós temos né nossa e tivemos cinco componentes das 13 variáveis de entrada nós estamos retendo cinco componentes Esse cinco componentes
em conjunto eles explicam 81 por cento Da variabilidade dos dados então com as 13 variáveis com os 13 componentes nós clicamos sem por cento nós estamos e tendo cinco e esses cinco componentes eles explicam uma alta é um percentual Alto da Mariana eles ficam 81 por cento então é bem significativo tá então o primeiro componente Ele explica 27 por cento da variância o segundo 23 1397 aí essa outra parte aqui é aquela parte lá do spss também que é a matriz rotacionada então a variância Total Explicada é a mesma tá vendo 81 pontos 5881 por
oi oi o que muda que o primeiro componente ele explicava 27 por 27 agora ele explica 24 explicava 23 agora explica 17 explicava 13 agora 17 explicava 9 agora 14 explicava 78 76 agora sete pontos 95 Então lembre-se essa rotação né nós é nós rotacionamos o eixo dos fatores né porque que nós fazemos isso para facilitar o entendimento é de em qual fator as variáveis irá ser grupar também Para quem não tiver lembrando para quem tiver dúvidas Eu recomendo voltar e dá uma olhadinha na aula da quarta-feira que a gente explorou e mostrou esse bastante
também o que que essa rotação dos componentes tá bom bom então uma outra possibilidade pessoal aqui eu estou gerando o script lote lá no spss a gente tem como gerar esse também tá então estou gerando aqui scree plot o que que esses triplot era só o o gráfico do cotovelo alguma coisa do tipo Tá então eu tenho o primeiro componente o segundo terceiro quarto quinto e o sexto Então olha o que que acontece tá segundo esse gráfico scree plot uma possibilidade de parada é onde o nosso gráfico então aqui eu tenho alto valor olha só
a gente tem um alto valor Olha só o do Uno é 3.54 do uma que horas 3.54 o 2 é 3 do dois e três ó 3.0 24 então é cada um dos componentes no eixo X eu tenho os componentes e no eixo Y eu Tenho alto valor então segundo esse o triplot uma possibilidade de retenção é onde o nosso gráfico faz esse cotovelo onde ele inverte tá vendo que ele vem caindo e de repente daqui em diante ele dá uma suavizada então segundo o gráfico scree plot é reter seis componentes tudo bem seria uma
possibilidade um dois três quatro cinco seis porque aqui olha só o gráfico dá uma suavizada né ele dá uma aliviada ele faz literalmente a ideia do cotovelo Né do cotovelo do braço então por esse critério pelo stripplot essa seria uma possibilidade tá aqui tá o comandinho é os comandos aqui para gente gerar esse gráfico scree plot tá e ai chegando ao final a gente tem então o que né a gente tem que ver o resultado que nós geramos né então nós vamos olhar agora a carga fatorial vamos analisar a carga fatorial do que nós geramos
então executei aqui esse bloco inteirinho aqui também olha só é só para dar uma Aparência melhor a matriz que nós estamos gerando Mateus componente expectativas lembrando então quê né Nós temos aqui nessa na primeira coluna aqui as variáveis depois nós temos o componente 1 o 2 o 3 o 4 eo 5 foram cinco componentes Retiro tá então o valor a primeira coluna numérica é do componente um segundo dois terceiro do 3 quartos no quarto e quinto 500 sim eu acho que travou sua compartilhação seis pessoal Comigo eu não realmente tá chovendo aqui a minha outra
tela tu tá grávida também tá achou vou tá aqui Oi obrigado por ter usado separar aquilo compartilhamento e voltar a E aí E aí E aí G1 Que beleza né E aí galera é então aqui olha aquela última saída Nossa lá depois né tinha parado aqui no gráfico escrito lote aí agora a gente tem aqui a carga fatorial como que interpreta Qual que é o valor tem tudo aqui também então o que que nós observamos a variável X6 o maior valor dela é no componente dois AX7 o maior valor é no componente 3 X 8
o maior valor do componente 4 x 9 no 1 Isso em valor absoluto tá aí mais ou menos né o maior positivo o maior negativo ax10 no terceiro componente ax11 no segundo ax12 no terceiro ax13 no segundo a x14 e no quarto ax15 no quinto ax16 no primeiro ax17 no segundo e a x18 no primeiro também então as variáveis são agrupadas em fatores a partir da carga fatorial ao Analisar a linha a variado acervo para o fator cuja carga fatorial seja maior valor absoluto então nós temos o fator 1 é composto pelas variáveis x-9 dezesseis
dezoito x do fator dois 1611 13176 1113 17 3 x 7 10 e 12 A4 o X8 X 14 e 15 x15 tá então aqui né a gente tem aqui eu gerei olha só então lembrem-se cla no spss eu tenho a opção de marcar um um salvar lá no sempre ele já gera para mim o os fatores no no banco de dados já automaticamente né Cria uma variável para cada um dos indivíduos nós exploramos bastante no final da aula também então aqui que eu estou fazendo aí só estou criando um Data Frame né que se
chama fatores Olha só então né eu estou criando uma variada um vetor e chama fatores aqui tá estou transformando isso não Data Frame com o nome de S eu estou mostrando aqui então esse data frente que eu criei tem a coluna Sat 1 parte 2 3 e 4 e 5 e aquilo Que eu estou fazendo né e jogando no meu arquivo DS eu estou concatenando o meu Data Frame que é esse que tem lá sem observações com todas as variáveis que eu tenho estou acrescentando agora essas variáveis nesse arquivo tá então eu estou fazendo aqui
um e criando esse aqui vou estou acrescentando as variáveis né eu coloquei uma coluna aqui para cada um deles Olha só então para cada um dos indivíduos eu tenho agora qual que é o Valor dele para o fator 1 é qual que é o score dele o fator um fator 2 3 4 e 5 e então a gente tem agora e essas variáveis podem ser usados em diferentes contextos também na aula passada nós exploramos bastante né a leitura dessas variáveis da interpretação delas que elas significam por quê que elas são elas são padronizadas não é
com cada uma dessas variáveis tem média zero de padrão igual a um valores maiores que zero significa Que esse cliente para que ele fator ele tem uma nota maior do que a média é quando é negativo é menor que a média quando mais próximo de zero né mais próximo da média quanto maior mais longe de zero mais próximo dos extremos né Mas diferente da Média esse indivíduo está no final das contas né esse arquivo nosso ele não tá salvo tá então a gente não é esse Data Frame nosso ele esse tempo inteiro eu tô trabalhando
com ele ele está só em memória não está salvo Aqui eu posso salvar e isso para Excel Eu posso salvar para para csv Eu posso salvar esse arquivo do jeito que eu quiser tá então esse comando aqui por exemplo eu salvo ele né é eu salvar esse arquivo csv tá então tá chamando ele csv eu estou fazendo esse encoding utf-8 aqui para respeitar caracteres especiais casos vista tá e o meu separador decimal é, tá então no final das contas eu salvo fiz todas as transformações fiz todas a na direito Que eu precisava e salvei novamente
um arquivo que poderia ser que céu poderia ser qualquer coisa aqui no final tá o ok pessoal Zé Esse foi essa forma de salvar e online que você fez serve para HTML também olha só que você esse to csv aqui olha é uma Esse é o esse que eu tô salvando olha só é um comando do panda então eu tô fazendo Data Frame to então eu tenho to csv hdf SQL tô te perguntando porque eu Tive problema com encoding principalmente na hora de exportar Eu acho que tenho que o encoding do super leve e do
colégio e não são poder forte o o teste oito né Não não é e aí foi por isso porque isso aí é foi merge aos trabalhos dos meus colegas e tudo e tava com acentuação toda errada com caracter é estranho Sabe igual fica por padrão E aí eu a gente ia até te perguntar para ver até agora que e o disse se tem alguma linha de comando para para Consertar isso ou eu tenho que arrumar tudo na mão mesmo na verdade a hora que você tiver trabalhando com seus dados uma possibilidade deixa eu me Sentei
nesse aqui eu já posso em princípio é definir qual que é o conjunto de caracteres entendeu quando eu estou trabalhando com a isso no no parto normal eu já coloco lá na primeira linha do meu arquivo do meu programa que eu tiver Fazendo eu tenho um comandinho lá para escrever hahaha mostrar aqui imaginei que tivesse Mas fica a gente fica na dúvida carro Júpiter e o colégio foi isso é uma ferramenta muito diferente da gente fazer coisa na mão no e no vs code né dá um mas tem eu tenho outro código aqui também eu
ver se eu acho que algum outro que eu vou te mostrar tirar Shake onde que tem nesse aqui não eu tenho algum código aqui que eu já fiz Isso já eu já coloco o comando e eu tenho 7 options tem alguma coisa assim que eu já já faço já logo no começo entendeu se quiser mandar faz o seguinte manda depois no grupo para a gente por gentileza que vocês até pressa para achar não quer ir eu pego contigo e aí eu uso aqui ao invés de aqui mas por que acaba aqui mediando o trabalho de
todo mundo fica um trabalho muito grande e eu tava olhando Molhei muita documentação para achar você acha que o problema era no Júpiter leves tá entendi foi briga com o conjunto de caracteres E aí eu posso rodar isso aí em qualquer ponto do documento e ele vai atualizar o documento todo é pode pode sim a beleza que eu vou salvar né aí ele vai entender o código de caracteres que você você tiver fazendo sim ah não Depois eu pego contigo eu te marquei lá no grupo se for o caso não precisa não e aqui eu
te Passo tem algum tem algum lugar aqui que com certeza tem isso tranquilo Muito obrigado dispões ok pessoal mais perguntas comentários dúvidas sugestões feito então todas essas análises feitas no cartão é e obtém lá no spss apenas com aquela com aquela opção lá né A única coisa que não tem lá que eu não gosto modelo né o gráfico lá tem isso também na tem eu tenho cover rock a única coisa que eu não fiz lá foi análise de normalidade dos dados que eu Não fiz no spss e não tá exatamente dentro da opção de Melo
da nossa fatorial eu teria que fazer isso fora tem a outra opção e o outro lugar no spss que eu faço análise da normalidade dos dados mas o resto tá assim convergência Total entre as duas ferramentas tá beleza o ok pessoal Vou ver se eu acho que é só isso que você falou da pergunta Boa pergunta só cantinho aqui quem tinha Perguntado é do do código lá é quem foi eu fui eu fui eu do DF na história só aqui olha só é num código normal é Python eu coloco esse comandinho aqui na primeira linha
Olha só Professor parou de transmitir a tela pu eu prefiro E aí e pegue muita coisa está pesado coitado é E aí E aí E aí um código normal é que ele comando Lita pequeno né Deixa eu ver seu aumento e [Música] o sono Oi vai ter frases ou pode sair vai ter frases aguenta aí que eu vou falar beleza por favor Ah deixa eu falar a frase aqui que eu volto lá já a pergunta é qual que foi a no nosso na nossa análise fatorial que nós Executamos hoje qual que foi a variância Total
explicada pelos cinco fatores retidos após a rotação a variação a variância Total explicada a é pelo cinco fatores retidos após a rotação e E aí E aí é essa aí me perdeu sair de alguma outra certo há 81 E aí Ah beleza então olha só voltando aqui num código normal basta eu fazer isso tá vendo basta colocar o joguinho da velha espaço menos* menos em colden E aí o código que eu quero então isso meu documento inteiro ele reconhece acentuação caracter especial reconhece tudo não código normal é quando estiver programando desenvolvendo em parque Agora no
no notebook eu tenho algum desses desses bagulho aqui que eu tenho sabe só não sei em qual aí eu vou achar eu vou te passar falar joia beleza beleza que eu tava fazendo pelo Júpiter joia aí desse problema não Beleza então beleza pessoal beleza grande abraço e nos vemos na próxima quarta se Deus assim permitir agora vocês o tanto de coisa já para continuar fazendo tá já tem visto de exercício tem uma outra base de dados dá para fazer análise Fatorial tem correr atrás do prejuízo tem muita coisa agora para fazer a ideia ainda né
demais agora uma ou duas aulas eu ficar disposição para tirar dúvida para gente saturar e análise fatorial exploratória e depois a gente já vai passar pelo conteúdo que análise Plus então a gente no próximo a gente vai fazer do mesmo formado é primeiro vou fazer em spss que é mais fácil de entender de ver e depois a gente vai para aí que absolutamente tudo no meu Pai então de novo tá








![Visual Calculations in Power BI - DAX Made Easy! [Full Course]](https://img.youtube.com/vi/JITM2iW2uLQ/maxresdefault.jpg)