hi folks welcome back to data Brooks I'm Eric Peter the PM for agent evaluation and framework we are excited to announce agent evaluations new synthetic data capabilities available today we've designed this capability to help developers improve the quality of their AI agents specifically this product addresses a key challenge that we've heard from many customers it's a difficult and timeconsuming process to have subject matter experts label high quality evaluation data however without this data it's difficult to evaluate and improve agent quality to reach production quality targets our synthetic data API allows developers to overcome these challenges
by generating a highquality evaluation data set in minutes customers who tested this capability were able to achieve 60% improvements in quality using this data before they engaged with their subject matter experts let's do a quick demo to show how the product works first I'll install data bre agents and ml flow next I'll load my parse document Corpus from a Delta table in this case I'll use the datab BR documentation next I'll use the API to generate synthetic evaluation data let me quickly walk through how the API Works we've designed the API to be simple and
easy to use you pass your documents how many evaluation questions you want and optionally you can pass a description of your agent and question guidelines to help tune the questions that that pipeline generates in this case we'll tell it that it's a chat that anwers questions about data brecks and the user personas and a few example questions let me take this off now that it's finished you can see it's taken about 2 minutes to generate 100 questions let's go ahead and take a look at the data you can think of each row as a single
fully formed test case that allows you to assess the quality of your agent in this case we generated a question following the guidelines that you provided and we identified a set of facts that must be present in the agent's response in order to accurately answer this question these expected facts make it easier for subject matter experts to review this data down the line and it improves the accuracy of the llm judges that assess the quality of your agent's response you could think of this as kind of having a digital subject matter expert at your side
who can quickly give you high quality agent questions and the criteria to judge the agent's responses now that we have the data let's go ahead and use it to evaluate and improve our agents quality next I'll write my agents code here I've written a function calling agent that uses a vector search retriever tool in this case I've used open ISD but I could have used any of the popular agent authoring Frameworks that data rck supports like Lane graph llama index autogen and more let's run the agent so we can quickly understand what's happening behind the
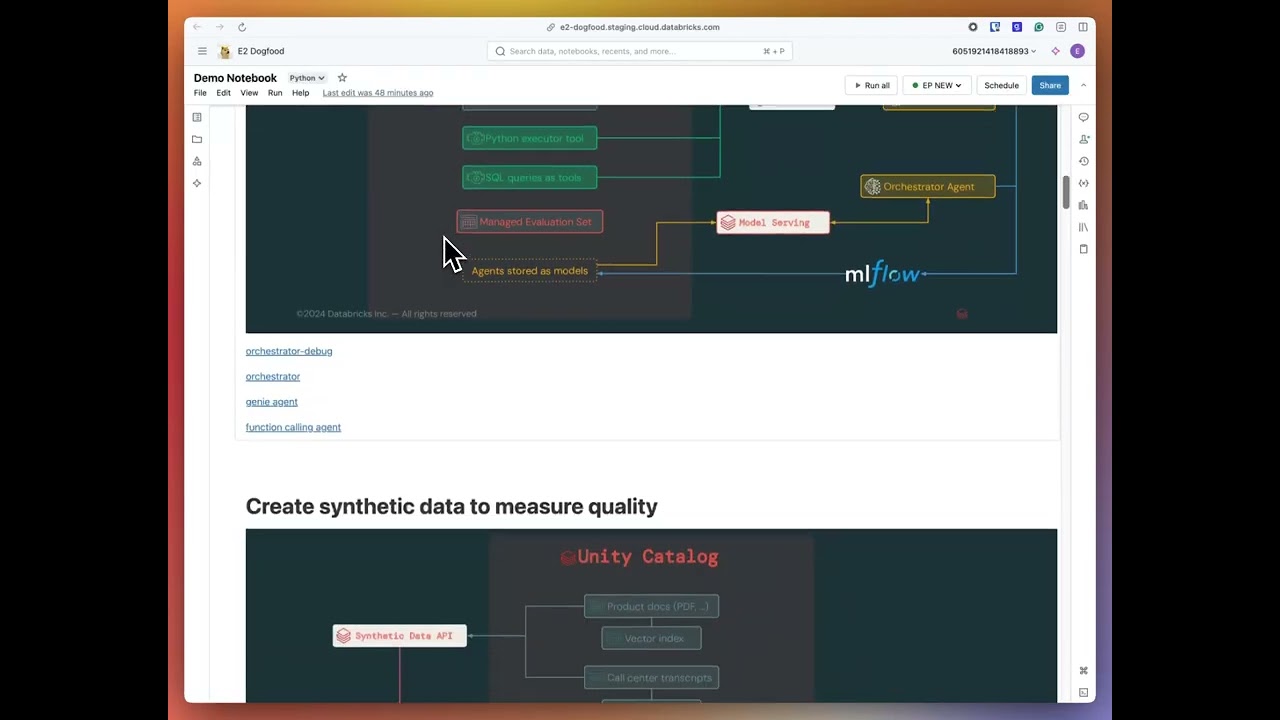
scenes here we can see the ml flow Trace which provides observability in development and production we can see the vector search retriever tool was called as well as several calls to an all them now let's evaluate the agent first I'll log the agent's code and config the ml flow so I have a copy and I know exactly what agent has been evaluated next I'll call ml flow. evaluate to run the evaluation I'll in the data that I generated above the model that I just logged and I'll activate databit Mosaic AI agent evaluation proprietary LM judges
let's kick this off now that evaluation is finished let me open the ml flow UI to look at the results mlflow and agent evaluation assess the quality of each record in the evaluation data set and provide you an overall score of quality in this case we can see that 54 are passing and 46 are not high quality agent evaluation identifies the root cause of the quality issues in this case we could see that 42% of the incorrect responses are due to an issue with retrieval let's open up a record to see what's happening agent evaluations
judges give you a written rationale for why your answer is correct or incorrect In this case it's identified that the ground truth the facts that we saw earlier required three things but these are not present in the retrieved context you can look through the assessments from the other judges as well and inspect each input and output in this case I notice that I'm only retrieving one document from my retriever maybe if I increase the number of documents that are coming back I can improve quality let's go ahead and try that out I'll come down here
and I'll change the configuration of my agent to return Five results rather than one let's go ahead and kick this off now that evaluation is finished let's go ahead back to the ml UI to compare the results I'll choose the previous experiment and I can see that changing the value of K from 1 to 5 LED to a 17% increase in quality and the root cause of retrieval has gone down I can inspect each individual record and see a side by-side comparison to help me figure out what quality issue I need to fix next since
I'm only at 70% quality I still have a bit of a way to go but for the purpos of this demo I'll wrap it up here from here you can continue to iterate on the quality of your agent eventually deploying it to a production ready highly scalable API as well as our web-based chat UI to collect stakeholder feedback using agent Frameworks single line of code to deploy in summary agent evaluation synthetic data capabilities allow you to accelerate your time to Market by reducing the amount of time that spent labeling data it enables you to deliver
higher Roi with less cost due to this synthetic data being able to help you increase quality at a faster Pace these capabilities are available today in public preview as well a link to this demo notebook if you want to try it yourself in the video comments we're excited to see what you build thanks for watching