О чём мы сегодня будем говорить с вами? Ну, сегодня будет достаточно интересная тема. С одной стороны, будет она очень простая, потому что у вас будет инструмент автоматизации, который мы подготовили и уже расширив нашу команду, э, вам выкатим после сегодняшнего эфира, чтобы не было проблем с теми, что у меня у кого-то появилось меню, у кого-то не появилось меню. Мы очень сильно за эти 3-4 дня усилили работу с нашими скриптами. И вы, соответственно, сегодня получите уже 15 скриптов, а чуть-чуть вперёд по просьбе многих, как люди писали, что, "Антон, мы хотим на январских праздниках уже создавать контент, мы
хотим его собирать, мы хотим его адаптировать". Ну и, соответственно, мы, идя вам навстречу, подготовили уже половину нашего комбайна, и мы его выгрузим, и вы после сегодняшнего эфира получите. И мы с вами сегодня прямо в живом эфире будем учиться, а собирать данные, анализировать данные. Мы будем учиться не просто эти данные собирать, но и находить те темы, которые нам, как модно говорить, вирусные темы, которые нам помогут либо нашим клиентам стать более успешными, стать более популярными. И все инструменты, которые мы сегодня с вами будем изучать - это как раз то, что позволяет с помощью искусственного интеллекта, с помощью
автоматизации работать не в пять раз быстрее, а в 10, в 50 - это то, что я показывал на всех конференциях. Это, по сути, вот сердце или мотор нашего комбайна, который позволит вам делать те вещи, которые делаем мы. Ну и, конечно, для того, чтобы вы смогли научиться, потому что у любого инструмента, эффективность любого инструмента зависит от уровня знания, о том, как вы им будете пользоваться, потому что, ну, есть известная поговорка, что микроскопом тоже можно гвозди забивать. Ну, и это касается нашего инструмента, да, потому что у нас уже десяток человек потестировал разные функции с разной степенью успешности
и удачности. И вот поэтому моя задача сегодня вам на пальцах простым языком показать, как же собираются все данные теперь с помощью этого инструмента, как мы можем анализировать конкурентов, как мы можем вытаскивать оттуда тексты, которые можем перерабатывать. Потом мы из этих текстов будем делать озвучку, потом будем делать из озвучки и фотографии, а из фотографии уже будем делать видеоролики. И все уроки у меня по программе построены таким образом, что первый урок мы начинаем, второй урок - это дополнение первого. То есть по итогам восьми уроков у нас будет, ну, по сути, восемь разных нейронных сетей или кластеров нейронных
сетей, которые одна дополняет другую, в конечном итоге будут производить разные продукты. Это мо могут быть тексты, это могут быть ээ огромное количество фотографий или это может быть в конечном итоге уже там YouTube каналы, Instagramканалы, Facebook каналы, ну и полная автоматизация. Поэтому не зря мы неделю мучились и кто-то быстро освоил, кто-то уже, как Фёдор, свой продукт сделал. А, но мы не будем забегать вперёд. Мы сегодня пойдём по очень простой вещи. Мы соберём данные и помни первый урок, как работает Google Gemini. и уже работает чат GPT, вы тоже доступ к нему получите. Вы сможете вместе с нами
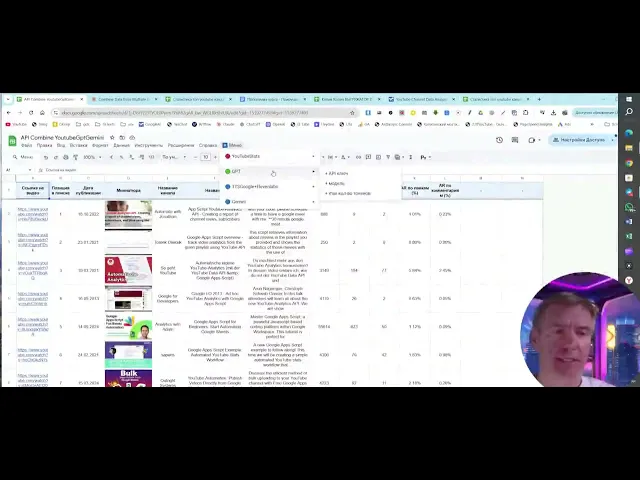
анализировать эти данные, переписывать эти данные и делать, может быть, ещё те вещи, даже о которых я ещё сам не догадываюсь, потому что инструмент абсолютно новый, да, и обладает десятком разных функций. Значит, по итогам сегодняшнего моего обучения, второго урока, это сбор данных с помощью искусственного интеллекта, вы получите таблицу через копирование, куда уже встроено большое количество функционала. Вот я вам буду показывать. То есть YouTubeстатистика - это модуль, который будет собирать все данные с платформы YouTube. А мы уже сделали Telegram, тоже сегодня покажу, но пока не выкатили его в публичный доступ, потому что есть там небольшие шероховатости, но
надеюсь мы их тоже победим и в понедельник уже выкатим вам не только YouTube, но и выкатим Telegram. Instagram у нас тоже на подходе, но мы планируем сбор данных с Инстаграма сделать где-то в начале января. Пока не обещаю, не гарантирую, да, это не заявленная функция, но мы уже приступили к этой работе. Небольшой анонс для любителей. Кто-то писал в чате: "Ребята, хочу чат GPT. Очень хочу. Умею в нём работать. Мне он больше нравится". Да, чат GPT тоже появился. Вот она у нас функция. Всё то же самое. Вводите IP ключик, да? Вот сюда нажимаете. Ничего сложного нет. Для
тех, кто первый раз захочет поработать с чат GPT, вот есть ссылочка здесь. И вы по этой ссылочке переходите, то есть не на самом чате GPT, а именно платформа Openi. То есть ключик будет вот по этой ссылки. А сгенерите ключик, сюда его вставите и, соответственно, то то же самое делаете с выбором модели. Здесь пока мы вам в доступе дали всего две модели. Мы можем подключить все модели, да, но для старта GPT4O Mini - это самая дешёвая модель, которая есть на рынке, и одна из самых быстрых. То есть, если вы хотите поработать за очень дёшево, то вот
вы берёте, ставите цифру два. Если вы хотите модель поумней, она в четыре раза дороже. GPT4O в четыре раза дороже по стоимости работы, чем GPT4O Mini. Но для наших аналитических работ, то есть если мы не претендуем на суперкрасивые тексты, второй модельки вполне достаточно. То есть вот я нажал сохранил, да, и у меня уже внутри и GPT работает, и вот Gemini, с которой вы все познакомились на первом уроке. А Gemini нам именно нужна для аналитики данных, потому что только Gemini позволяет загружать большие массивы данных. То есть Gemini, э, с точки зрения количества символов, которые можем отправить для
аналитики внутрь Гугла, почти в шесть раз больше, чем можем отправить в чат GPT. Поэтому, если удобнее писать и вам нравится больше, как работает чат GPT, пишем в чат GPT тексты. Но для аналитики ничат GPT, никд не подходит, потому что он не может принять вот эти большие массивы данных. Вот. И мы уже подключили сюда пока вот в это меню ТТС. ТТС - это текст to spech, то есть из текста в речь. Ещё один уже модуль, когда мы с вами тексты, которые мы извлечём с Ютуба, потом перепишем чатом GPT или Gemini, начнём озвучивать. То есть у нас
будут голосовые файлы для того, чтобы потом создавать ролики. То есть мы вот сюда уже подключили вам модуль, который будет работать и с 11 Labs, и работать с Гуглом. Но пока сюда не лазим и не пишем, что у нас что-то не работает. Антон, когда подключите? То есть мы просто пока её выкатили. Но чтобы у вас была возможность видеть. И к концу вашего обучения у вас вот здесь будет огромное количество функционала. Почему мы и называем его комбайном? То есть это комбинирование семи нейронных сетей. А на самом деле у нас уже их девять. Мы уже девять нейронных сетей
подключили. И я надеюсь, что так получится. У нас будет как раз урок, как вам самим создавать такие инструменты на базе Google таблиц. Я покажу свой опыт, с которым я работаю. И, наверное, по итогам этого урока, хотя уже у нас есть первые ласточки в лице Фёдора Слюсаренко, который создал уже подключение к Лоду, мы в январе месяце запустим интернет-магазин скриптов, и каждый из вас, кто пройдёт мои уроки, создаст какие-то скрипты, может стать нашим партнёром, и за процент мы предоставим свою платформу, куда вы сможете выгружать свои скрипты, и мы их будем продавать по всему миру. Платформа у нас
будет англоязычная. И мы, как рекламное агентство, умеем делать трафик. И ну скажу без ложной скромности, у меня сейчас огромное количество заказов на разные скрипты, на модернизацию этих скриптов именно для Google таблиц, потому что Google таблицы - это, наверное, самый признанный мировой формат, с которым все умеют работать, будь то китаец, индус, русский, там, не знаю, или белорус. И по итогам нашего обучения, помимо того, что мы будем создавать с вами конечные продукты в виде текстов и видеороликов, мы ещё будем создавать скрипты. И вот есть ребята, которые у меня находятся на частных консультациях. Я ещё дополнительно веду частные
консультации, кто в теме, именно в теме. И вот ребята уже применз разных продуктов, которые, ну, они решают свои задачи, но по сути если вам нужно решить какую-то задачу и вы её решили с помощью моего обучения скрипта, то я вам дам возможность этот скрипт там на равных, например, 50 на50. Вы как автор, создатель скрипта, загружаете его на мою платформу. У нас в штате есть специалист, который из вашего скрипта делает библиотеку. Объясню для всех, почему мы работаем. не просто скрипты вставляем, а именно библиотеки. Ну, например, а, нас на курсе учится 70 человек. И если я даю вам
доступ к библиотеке, то, соответственно, я вношу в эту библиотеку одно изменение, и сразу у семидесяти человек это изменение появляется. То есть мы сейчас подключим, появилась в Google ДМИ ещё одна новая моделька, очень супербыстрая, суперумная, да. И, соответственно, вам не надо будет ничего делать. Мы вносим в библиотеку изменений, и у вас в меню сразу появляется новая моделька. Да, то есть все изменения, которые мы будем вносить на протяжении 2ву месяцев, пока вы учите, у вас автоматически будут появляться. Это мировой стандарт работы через библиотеки. Да. И есть вторая история, что мне многие говорят: "Антон, ну вот я создал
скрипт, он же такой классный, ну его же все увидят, у меня сразу украдут. Какая здесь ценность?" Второе, что библиотека позволяет сделать вам, когда вы создадите свой скрипт и силами на то есть самому сделать из скрипта библиотеку сложно. Вот я вам сказал, что написал 7.000 строчек кода. Это действительно правда. У меня всё работало, но как только я попытался делать библиотеки, тут уже нужно очень глубокие уровни. И у нас в команде, наконец, есть такой человек, который может из любого скрипта сделать профессиональную библиотеку. И тут вы сможете вместе со мной зарабатывать, потому что вот, ну, у меня уже
около 30трицати скриптов, то есть лично, которые я сам написал. То есть вы будете работать с двадцатью, хотя у меня есть скрипты, там всякие сSс-ленты, сократители ссылок, парсинг какого-нибудь Хабра там или ещё чего-нибудь. Возможно, кому-то потребуется, тоже можно будет посотруничать или кто-то из вас сделает такой скрипт, и мы с вами будем вместе работать и зарабатывать. То есть это один из одна из возможностей уже сейчас написав скрипт, выложить его на нашу платформу, как только мы её запустим, и получать деньги в твёрдой валюте со всего мира. Ну, небольшое исследование вам расскажу, наверное, кому-то будет интересно. Например, скрипт подключения
вот такой, как у меня на Ютубе, ну, к примеру, я там могу оценить его в 100 долларов, да? А аналогичные скрипты худшего качества с меньшим функционалом на Ютубе, например, на американском рынке продаются за 500 долларов, да? То есть американский рынок в пять раз платит больше за интеллектуальный ээ труд или за вот эти скрипты, которые позволяют вам работать. Ну это вот такое отвлечение, то есть как мы с вами сможем зарабатывать, но на самих скриптах, но сами скрипты имеют ещё большую ценность. Эти скрипты позволят нам получать огромное количество данных. Как вы понимаете, и на первом занятии об
этом рассказывал, что сейчас среди текстовых нейронных сетей и среди компаний там, которые разрабатывают, это Open AI, это Клод, это Джемини, это Грок и это Лама от Фейсбука, идёт война за данные. Где же эти данные найти? То есть все данные в мире, которые были в интернете опубликованы, они уже загружены в нейронные сети и они закончились. Вот сейчас все ищут, где же найти новые данные. Мы об этом на первом уроке говорили. Если Google берёт данные из поиска из платформы YouTube, когда публикуется ролик, да, появляются тексты. А-а, Грок - это Илона Маска, он берёт данные из Твиттера. А
Facebook - это Лама, это Марк Цукерберг, он с Фейсбука берёт, да? А бедный Open Chat GPT вот договорился с Аплом, да, чтобы оттуда брать эти данные. И эти данные становятся новой валютой. То есть сейчас самое большое количество инвестиций в мире, чтобы вы понимали, почти 60% всех мировых инвестиций идёт именно в искусственный интеллект. И те люди, которые создают такие продукты, те люди, которые научатся работать с этими продуктами, могут вот на этой волне, соответственно, вместе со мной, вместе с нашей командой тоже зарабатывать. Вот поэтому кто-то может поделиться своим скриптом в рамках нашего обучения, просто выложить его в
чат, да, кто-то может его улучшить, но я думаю, что первые ласточки полетели, скриптов будет много, и мы вместе с вами на них будем зарабатывать, да, как же извлекать эти большие данные и, например, почему мы начали первые данные брать именно с платформы YouTube? Это очень всё просто. Первое, у Ютуба есть библиотека. абсолютно прозрачная, которая позволяет в один клик соединить Google таблицу с поиском Ютуба внутри. И мы это, ну, я знаю, как это работает, написал первые скрипты, которые позволят нам собирать такие данные. Ну вот, давайте я вам покажу нашу табличку, да, в которой мы с вами сейчас
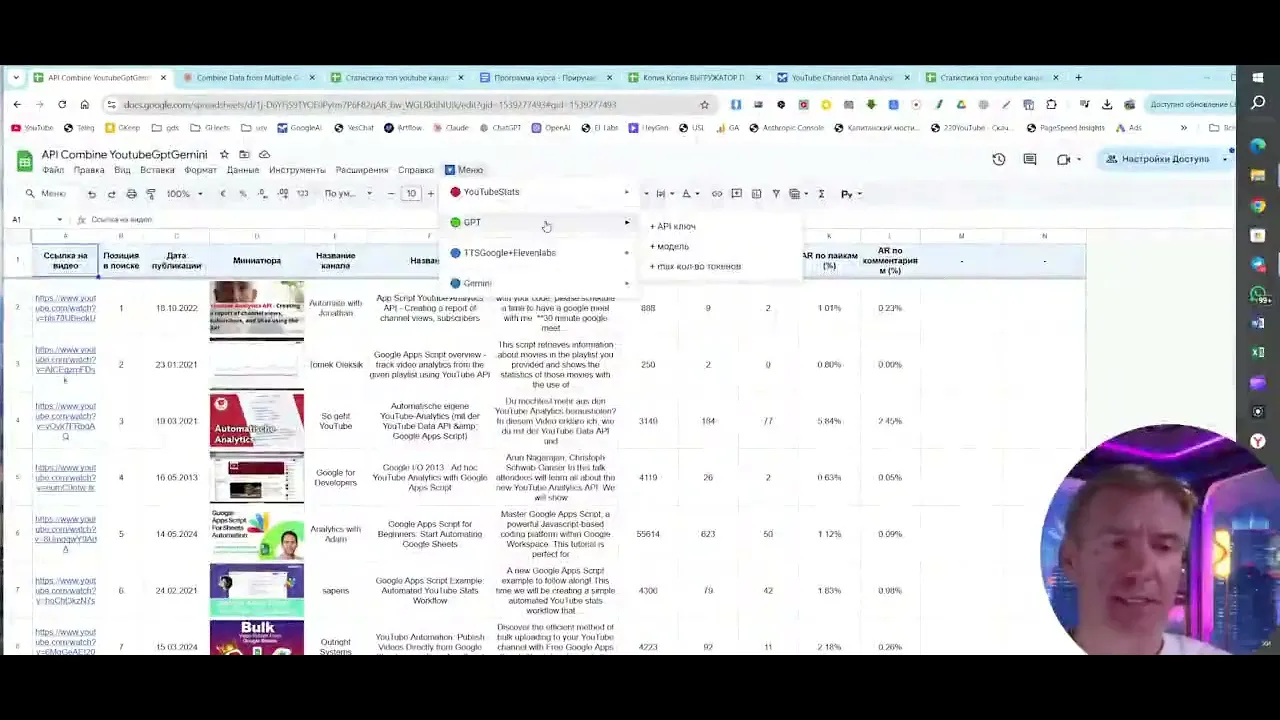
будем работать, наше меню. И первое, что я сделаю, создам чистый листик. Да, начнём с чистого листа, как говорится. Как же всё это дело работает. Ну вот, давайте я вам покажу, как мы, например, анализировали нишу доктора на Ютубе. Кто-то из вас уже скачал небольшой файлик, куда мы половинку скачанных YouTube роликов и YouTube данных, которые мы собрали, выложили, и кто-то уже по нему начал задавать мне разные вопросы, как же это собрать, как получить оттуда данные и вообще, где тут деньги. Ну, смотрите, у нас есть, если начинаем с самого начала, есть менюшка. Мы открываем менюшку и заходим в
YouTube статистику. Первое, что нам нужно сделать - это найти все каналы всех докторов на русском языке. То есть, если мы пишем на русском, мы ищем на русском. Если пишем на испанском, будем искать на испанском. Если мы пишем на английском, будем искать на английском. Но давайте проанализируем нишу докторов. То есть вообще, что есть о здоровье в рунете, э, на Ютубе. И мы первую функцию рассмотрим поиск каналов по ключам. А она работает очень хитро, потому что если вы пойдёте в сам YouTube, то YouTube вам будет, э, выдавать каналы, в которых есть ключевое слово в названии канала. Например,
нам нужно слово доктор. Мы пишем, да, то есть мы ищем все каналы, связанные с медициной, то есть мы начинаем исследовать нишу. Вот YouTube вам покажет только, если есть название. Особенность моего скрипта в том, что он ищет не только по названию, он ещё заходит в описание. И если в описании канала есть слово доктор, то он тоже этот канал вам выдаст. И вот смотрите, я нажимаю слово доктор и даю запрос Ютуба, чтобы он сбегал и принёс мне каналы. Всё, проходит 1 секунда, и мы скачали 100 каналов. Я специально поставил ограничение 100 каналов, потому что, мм, ну, во-первых,
в каждой нише есть предел по каналам, да, и вот если я вниз опущусь, то мы с вами за одну секунду получили 100 каналов, где есть слово доктор. Вот видите, сейчас я в самый низ опущусь, чтобы вы видели. Всё, мы скачали 100 каналов докторов. Это абсолютно легальный способ, то есть мы ничего не воруем. Это YouTube предоставляет такую возможность, когда написан код. И для удобства, ну, я специально так сделал, что у нас в первую очередь выводится по подписчикам, у кого больше всего подписчиков, да, и вниз. Вот на первом месте доктор Ивдакименко, 6 млн подписчиков у него на
Ютубе. И видите, канал зарегистрирован аж в 2013 году. И кликнув на описание, вы можете прочитать, о чём этот канал. Да. И вот я поэтому сказал, что мой скрипт ищет не только по названию, но ищет и по описанию. Вот в данном случае есть доктор, но это про мультики. Вот этот нам не нужен. То есть надо ручками первый раз пройтись и удалить те каналы, где есть слово доктор, но они там о мультфильмах или ещё о чём-то. Таких каналов немного, но вот ещё один о научной о научной фантастике, да, человек рассказывает. Вот мы удаляем, а доктор Боб -
это детская анимация, он тоже нам не нужен. Ну иногда попадаются каналы, где есть слово доктор, но здесь чисто визуальная фильтрация. Хотя я могу поручить искусственному интеллекту прочитать описание, если там нету ничего о здоровье в медицине, мне поставить пометочку. Ну, проще вот в данном случае вот так вот пробежаться. И вот ещё доктор Мистик тоже его удаляем. Да, особенность того, как работает ещё скрипт. Чем удобно и хорошо, что, например, когда я спарсил, видите, внизу он сразу пишет топ- 100 каналов. То есть к - это каналы и слово доктор. То есть вы сразу видите, какая какой лист у
вас он автоматически переименовывается по названию канала. Нужно понимать, что есть только одно ограничение. Оно связано с ограничением самого IP Ютуба. Вы можете в день спарсить либо 10.000 каналов, либо 10.000 роликов, либо, например, там 7.000 роликов и 3.000 каналов. То есть в день ограничения количества запросов, которые вы можете ээ легально отправить Ютубу, оно 10.000. Если вы хотите сделать работать совсем на максималках, например, 100.000, тогда надо просто покупать платную версию аэркспейса. Ну вот платный этот, как он там называется, у Гугла. И там вам будет 100.000 запросов в день. Но, в принципе, ничто не мешает написать мне, я
дам добавлю вам вашу ещё какую-нибудь почту, вы будете 20.000 ся каналов или роликов в день собирать. Мне для аналитики одной ниши хватает 10.000 запросов для того, чтобы собрать за один день. Ну вот вчера наш программист тоже в 4:00 утра написал, что у него закончилась квота. То есть даже программисты наши иногда натыкаются на квот. Ну помимо слова доктор, наверное, есть ещё здоровье, да? логично. То есть мы берём следующее ключевое слово, что может быть связано со здоровьем. здоровье. И вот сейчас мы найдём ещё 100 каналов о здоровье. Пока мы собираем только каналы. Всё, одна секунда. Все 100
каналов, в которых есть слово здоровье, ну, например, вот большой канал про про здоровье, да, вот с известной э нашей русской Делярой, да, у неё тоже большое количество подписчиков. Вот. Или вот один из лидеров, да, нутрициологов, вот я лично знаю Ксения Глинкина про здоровье. Большой канал растёт. У неё уже 1. 600 подписчиков, да и три 34 млн просмотров, хотя канал молодой всего 4 года, да. И таким образом мы можем собирать каналы ниши здоровья, ниши доктора, можем делать более узкие, например, сегодня там у нас присутствуют и в том числе доктора на прямом эфире, да, Николай, вот он
там массажист, кинезиолог, вы можете написать школа массажа, не знаю, кинезиология, и он вам выдаст 100 каналов, где есть о кинезиологии. Ну и ещё в здоровь и в медицине есть важное понятие. Это, например, клиника, да? И мы ещё давайте добавим сюда клиника. Слово клиника. Можно добавить больница, но, как правило, клиник будет достаточно. Вот я нажимаю, и мы сейчас с вами получаем 100 каналов клиник. Да. Да. Клиника доктора Длинна тоже очень большой, 2 млн подписчиков, да? То есть мы собрали здоровье, доктора и клиники и получили 300 каналов на Ютубе, которые работают в этой нише. А есть ещё
одна возможность, ну, например, совсем вам нужна какая-то узкая тема. Ну давайте найдём все ролики, связанные с таким модным направлением, как кинезиология. И тогда мы переходим ко второму меню поиск видео по названию и пишем вот это слово. То есть, если я врач-кинезиолог или вы продюсируете или вы хотите помочь врачу-кинезиологу, то вы пишете слово кине, может и неправильно, кстати, напишу, не помню, как пишется. Кинезеология к своему студу. Кинезио. Кинези. Так, сейчас, может быть, он мне подскажет, как правильно писать. А вот так вот, да, кинезиология, да. И я уже получаю не каналы, а получаю аэ самые топовые ролики.
Видите, здесь позиция в поиске. То есть это самый, если вы напишете слово кинезиология на Ютубе, то вот этот ролик будет первым. Номер один. И вот он у меня автоматически проставляет нумерацию, какую позицию в поиске занимает тот или иной ролик. И, соответственно, мы получаем всю статистику. Плюс ещё дополнительно наша система, видите, рассчитывает engagement rate - это вовлечение. А то есть, что такое вовлечение? Это отношение количества лайков кличеству просмотров. И вовлечение - это количество по комментариям, количество комментариев к просмотрам. Очень важный показатель, для чего нужен. Ну, я как маркетолог, человек, который работает, могу получить статистику там 100
роликов, но мне хочется понять, где же больше всего люди реагируют на контент. То есть я сам ролик не смотрел, ещё не знаю, что там внутри, но видя вот этот engagement по лайкам, понимаю, что самое и фишка-то работы в таблице в чём заключается. Мы можем с вами выделить э название наших всех столбцов, включить фильтр, да, и я хочу отфильтровать все ролики о кинезиологии. Какой же из них имеет самый ээ большой процент лайков? То есть, что больше всего понравилось людям? И я сейчас в один клик. Всё, на первом месте совсем новый ролик, хотя он пока занимает пяти,
видите, он в поиске пятидесятое место, но что-то в этом ролике заставило людей его пролайкать. 60.000 просмотров и 5.000 лайков. То есть это на самом деле заоблачные, то есть средняя статистика просмотров к лайкам - это, ну, от 2 до 5%. 10% - это космос. То есть мы понимаем, что если мы продюсируем какого-нибудь доктора или эээ клинику, а нам надо найти те ролики, которые нравятся людям. И вот благодаря простой простому, ну, совмещению Google таблицы с YouTube поиском, у нас появляется возможности больше, чем на самом Ютубе, потому что а YouTube не может вам выдать и сразу ролик с
большим количеством просмотром, и с с engagementрей по лайкам. То есть он вам выдаст просто по комментариям. Вот в Ютубе нет вот этих коэффициентов в поиске, поэтому мы их специально ввели. И вы понимаете, что мы можем вот эти все взять ролики, посмотреть, что же там произошло, почему они настолько хорошо заходят аудитории. Это вот вторая часть меню, то есть вторая часть поиск видео по ключам. И вы можете, ещё раз повторю, в день собирать 10.000 роликов и анализировать, что же в нише заходит, хорошо или плохо. Дальше давайте теперь вернёмся обратно к нашим врачам. Да, у нас есть вот
такая штуковинка здесь. Видите, у меня сколько здесь разных а-э поисков. То есть один запрос, который вы делаете, неважно, поиск каналов или поиск видео, создаёт вам отдельно страничку, листочек в Google таблице и называет его по названию поиска. То есть, если вы ищете видео, то видите, вот внизу написано топ 50 в. Это значит 50 лучших роликов видео по запросу кинезиология. То есть наша система автоматически переименовывает лист в таблице в названии ключевого слова, по которому вы ищете, чтобы потом не потеряться. Ну и мы сделали одну такую бонусную вещь, потому что когда вы исследуете нишу, у вас будет 50,
может быть 60, может быть 70 листов. Это очень много. Такая бонусная функция, но я для себя её сделал. А называется создать навигацию по вкладкам. Вот вы, когда нишу исследовали, собрали все каналы, все ролики, вы нажимаете вот на эту кнопку создать навигацию по вкладкам. И сейчас наш скрипт создаст вам ещё одну, а, создаст вам страничку. Она называется навигация. Вот она, видите? Я в один клик создал себе навигацию. То есть вот эти все ссылки, это листы, это название листов. Вот сколько я насобирал, видите? То есть я могу нажать на любой ээ канал, да, и перейти э вот
сюда, например, вот топ 50 психологии, да? То есть, по сути, мы создали внутри Google таблиц такую библиотеку, да, оглавление, по которому вы можете потом быстро ориентироваться, чтобы находить те или иные ролики или каналы. Теперь переходим, наверное, к самому крутому и самому интересному. Мы с вами собрали 100 каналов клиник, собрали 100 каналов о здоровье и собрали 100 каналов с докторами. У нас получилось 300 каналов. Это 300 самых топовых каналов, которые собираются от количества подписчиков и вниз. То есть мы, по сути, собрали всё, что есть. Ээ все самые популярные каналы в Нише здоровья на российском Рутюбе, русскоговорящем,
не российском, а русскоговорящем, потому что там иногда из Казахстана ребята из Узбекистана попадают. Вот. Что же делаем мы дальше? А дальше мы приступаем к очень одной классной вещи. Это мало собрать канал. Нам нужно ещё собрать все ролики, что же есть на этом канале, о чём говорит этот доктор и почему он так популярен. Вот раньше это называлось насмотренность. Мы сами открывали эти YouTubeканалы и начинали читать, что он пишет, открывать ролики, смотреть. Уходило на аналитику ниши 2-3 дня. Ну, то есть 2-3 дня я, мои помощники изучали эту нишу, смотрели, что заходит, как-то это копировали. Ну, то есть
был этот ад. Ну, реально ад. 3 дня на на аналитику ниши, это где-то 10 тире15 часов уходило, чтобы составить какой-то текст, просмотреть нишу. И то это было кусочками и урывками. Очень было сложно. То теперь мы можем э найти, вот ещё раз пока покажу. Заходим в навигацию, да, находим, например, самые топовые каналы, которые нам э-э понравились. Ну давайте вот 100 100 каналов докторов. Вот я кликаю на 100 каналов докторов, перехожу на вкладочку, где мы собрали докторов. И вот давайте возьмём, например, клиника доктора Длина. Вот он топовый. 2 млн у него подписчиков, 347 млн просмотров. Представляете, доктор
Длин, а канал молодой, двадцать первого года. То есть, видите, я в один практически клик собрал все каналы и вижу всех лидеров. Доктор Мазбегутов, двадцать второй год, 73 млн. Ну, давайте возьмём топового самого. Доктор Длин, 347 млн руб. Смотрите, я копирую ссылочку отсюда. То есть я вам рассказываю логику, как вы должны работать и как вы будете выполнять домашнее задания. То есть у каждого из вас будет своя ниша. Ну, если у нас сегодня есть доктора, они есть на прямом эфире, они получат уже готовое исследование ниши, то каждый выберет и напишет себе: "Я хочу нишу психологии, я хочу
ниже нишу автоматизации бизнеса. Я хочу, не знаю, ниши подбор автомашин, ну, я хочу нишу, там, не знаю, искусственного интеллекта или ещё какого-то". То есть по итогам нашего занятия вы каждый из вас выбирает себе нишу. Даже если кто-то захочет одну и ту же самую нишу, ничего страшного. Потом мы посмотрим, как отличаются у вас результаты, когда будем смотреть ваши домашние задания. И по итогам сегодняшнего занятия у нас будет там 70 таблиц. И в каждой таблице будет огромное количество роликов и огромное количество YouTube каналов, которые мы будем анализировать. У нас будет база на миллион, может быть, 2 млн,
может быть, полмиллиона, как постараемся. Вот у меня в базе уже загружено несколько миллионов разных таблиц. В разных таблиц несколько миллионов данных о всех роликах. Значит, как работает дальнейшая статистика? Мы нашли лидера, который у нас на Ютубе набрал больше всего количества просмотров. Ну вот Комаровского я не хочу смотреть, а я хочу доктора Длина. Вот я копирую просто эту ссылку и что делаю? открываю нашу YouTube меню и хочу найти все ссылки на видео с этого канала. То есть нажимаю, открывается опять окошко, и мы вставляем вот сюда название канала. Причём, наш скрипт поддерживает любое название канала. На Ютубе
возможно три варианта названия одного и того же канала, да, как это странно не кажется. Ну вот последнее вот то, что ввели - это usрнейм, да? Вот появилась третье, и мы вы можете вводить ссылку любой, он вам найдёт. Это более сложный процесс, потому что роликов очень много. И сейчас вот смотрите, я нажал, ввёл канал, и мой скрипт побежит на YouTube канал Доктора Длина и соберёт, внимание, 500 последних роликов. Ну почему 500? Ну, например, на канале может быть 1.000, может быть 2.000, может быть 3.000 роликов, которые снимались 10 лет назад. Всё, смотрите, я 500 роликов собрал за
10 секунд. Я собрал пока только ссылки на ролики и собрал превьюшки. Ну, чтобы понять, то ли это не то. И ссылки нам ещё нужны. Мы сейчас работаем над тем, что если нам нужно, мы можем выкачивать эти ролики. То есть сделали первый этап. Всё, ролики собраны, у меня появились ссылки. Когда у меня есть ссылки, я открываю опять меню и говорю: "А теперь моему роботу, который написал искусственный интеллект, сходи и собери всю статистику всех видео". Вот она, видите? Обновить статистику всех видео по ссылкам. Ссылки у меня автоматически собраны в столбце А. Я нажимаю, и теперь наш парсер
принесёт нам 500 видеороликов, где будет название, описание, теги, хэштеги, всё, что есть, лайки, комментарии и прочее. А мы уже с командой посовещались. Наверное, мы сделаем просто единую кнопку. Вы вставляете ссылку с канала и получаете 500 последних роликов. Ещё раз объясню, почему 500. Ну, первое, а, есть ограничение у Ютуба. За один запрос можно получить только 500 роликов. Его не сложно обойти. Мы можем и все 10.000 роликов собрать. Вот. Но фишка в чём? Что если мы собираем 10.000 роликов с канала, которым 10 лет, то тогда наша аналитика, она растянется очень во времени и она будет не свежей.
Поэтому я принял такое решение, ну, исходя из своего опыта как маркетолога, что мне достаточно 500 последних роликов с канала. Вот мы взяли доктора длинно, да, и я могу вам сказать вот эти 500 роликов когда же, видите, один клик, 10 секунд и 500 роликов у нас в таблице со всеми данными. И вот ролик, который имеет номер 500, а ролики собираются самый свежий, первый и самый, который был выпущен несколько лет назад. Вот он, двадцать первый год. То есть я за один клик собрал, а всё, что доктор Длин делал 4 года на Ютубе. 4 года? Даже четыре, мне
кажется, многовато. То есть мы обычно оцениваем ролики за последний год, ну, может быть, два, да, чтобы понять вообще свежесть, потому что медицина всё-таки такая инерционная вещь. У неё нету, как в искусственном интеллекте, каждую неделю что-то новое появляется, да, она всё-таки классическая штуковина такая, за исключением всяких наших вот этих экспериментов на планете Земля под названием ковид, да, участниками которого мы все с вами были. Вот. И видите, я в один клик получил название, видите, ссылки на видео клиники доктора Длина. Автоматически название листа идёт по названию канала. Всё. То есть наша система, чтобы вы потом не потерялись, всё
делает автоматически. И я понимаю, что у меня есть название роликов, у меня есть описание роликов всех, у меня есть теги, у меня есть длина видео, у меня есть просмотры, лайки и комментарии. То есть я собрал всё за 4 года на канале доктора Длина. Ну или я хочу, ну давайте для примера ещё покажу. Возьмём не не доктора Длина, а давайте возьмём какой-нибудь другой канал. Так, чтобы найти каналы, вот для чего нужно наша штуковина, да, её лучше делать в самый верх, навигацию именно когда вы листаете, чтобы вот как я сейчас не искал, потому что здесь, видите, сколько
у меня всяких разных в тестовом моём файлике а вкладок, то есть больше псяти вкладок. Причём Google таблицы год назад повысили квоту количества символов, которые вы можете ээ содержать внутри в два раза, да? То есть вы можете 5 млн символов загрузить в Google таблицу, и она будет совершенно спокойно работать. Ну, 5 млн символов - это, ну, большое количество. Вот. Да. И поэтому мы с вами находим сейчас, э, файлик, который, ой, страничку, которая называется навигация. Ну или, не знаю, берём какой-нибудь наш топ-50. Сейчас я найду какой-нибудь топ-50. Сейчас какой-нибудь поинтереснее найдём канал. Ну давайте там возьмём, к
примеру, ну вот у меня есть 100 каналов о красоте, да? То есть у меня уже здесь не красота уже кого-то, кого-то я спарсил в в этот файлик. Так, сейчас я найду какого-нибудь поинтересней поинтересней канал. Ну вот давайте доктор Мазгутов, да? То есть я также вставляю ссылочку, нажимаю, да, и получаю. А это, кстати, превьюшки у меня уже делается. Видите, написано внизу превью. Это мы сейчас к этому придём. Это специальная функция для дизайнеров, чтобы вы в один клик получали, собирали превьюшки самых популярных роликов на YouTube канале с канала, который вы исследуете. И дальше вы эту ссылочку можете
либо сохранить в PDF, отправляете дизайнеру, чтобы у дизайнера была называется насмотренность, что в ниши самое популярное, что самое кликабельное. Так, давайте всё-таки я вернусь к навигации, чтобы можно было легко искать, да? И, соответственно, вот в нашей навигации файлик, который у нас автоматически создаётся, мы ищем, э, значит, топ- 10000 каналов доктора, да? Вот он. Открываем топ 100 канала доктора. Ну и давайте. Доктор Мазгутов- это один из сейчас самых таких известных на Ютубе людей, который набирает много. Или, например, давайте посмотрим, э, может быть, у кого побольше просмотров. Ну, какой-нибудь можно вот, чтобы понять, у кого больше просмотров,
ещё раз мы ставим фильтр, да, и по количеству просмотров фильтруем от я до А. Ну, понятно, что доктор Комаровский на первом. Доктор Длин клиника доктора Шурова. Не знаю, кто такой старый канал тринадцатого года. Давайте что-нибудь посвежее найдём. Что-нибудь посвежее. Вот Доктор Боб - это мультики. Сейчас удалим, чтобы нам не не мешался. Ну давайте всё-таки доктора Мозгуто возьмём. Почти 100 млн просмотров. Молодой канал. Да, мы также заходим в меню, нажимаем все. Первое делаем. Нам нужно собрать все ссылки на видео с канала. Открываем все ссылки на видео с канала и в нише собираем э ссылочки. То есть
наш Парсерсбегает, соберёт сейчас ссылочки с канала доктора Мазгутова. И дальше же в этом э листочке мы можно не дожидаясь. Вот 180, видите, 184 ролика у него 3 секунды и мы собрали за 3 секунды 184 ссылки на ролики. Но нас интересуют не ссылки, а нас интересует статистика всех его. Вот она. Обновить статистику всех видео. То есть вы, когда собрали топ- 100 каналов докторов, топ- 100 каналов клиник, топ- 100 каналов о здоровье, высматриваете каналы, которые помоложе, ну, это моя рекомендация, и на которых больше всего просмотров. И потом каждый этот канал, ссылку на канал вставляете и получаете вот
такой листочек. Видите, он пишет ссылки внизу на видео канала доктора Мазгутова. Я получил все ссылки. И вот эти, кстати, картинки здесь есть. Ещё я покажу вам одну вещь очень классную. А есть у Google таблиц великолепная возможность. Мы вставляем ссылки на канал, это называется embossм. То есть я могу запускать видеоролики прямо в Googleтаблицах, то есть мне не нужно ходить на YouTube. >> Постараюсь объяснить, почему наша жёлная является одним из самых важных и одним из самых недооценённых органов в современной медици, >> да? То есть фишка в том, что в нашей таблице мы работаем не уходя. То есть
мы можем кликнуть, перейти на YouTube, конечно, но ещё прелесть в чём? Что ролики в Google таблице запускаются без ВPNна. Я не знаю, как это работает, честно скажу. Вот у меня, видите, VPN отключен сейчас наверху. Вот нету VPN, не включен. То есть, если я нажму вот VPN, видите, он выключен, да? Таблицы в Google таблицах YouTube работает без випенны. Как это происходит, не знаю, но очень удобно. То есть вы не уходите из таблицы, надо посмотреть вам какой-то ролик, о чём он. Наводите на ссылочку, ждёте секунду, видите, открывается OTS - это пле нажимаете на посмотреть. Все ролики показываются
внутри. Сегодня хочу показать очень интересное упражнение. >> Да, ну это просто, чтобы вы понимали, что есть такая возможность. Вот таким образом вы на первом шаге собрали каналы, на втором шаге вы можете, если вам надо углубиться, собрать видеоролики. И после того, как вы собрали видеоролики и каналы, вы собираете всю статистику всех топовых докторов или в нише, там, не знаю, автообзоры или психология, или коучинг. Кому что интересно, собираете всю статистику. Вот. И у вас получается огромное количество таблиц с полностью собранной нишей того, что есть на Рутюбе. То есть ещё раз каналы, видеоролики, а потом видеоролики с каналов.
Но этого тоже мало. Мы же хотим проанализировать, о чём говорят эти специалисты, о чём говорят эти доктора или там, не знаю, автообзоры. И вот здесь наступает очень классная вещь, достаточно сложная. то, что YouTube не даёт, потому что YouTube, когда ролик загружается внутрь Ютуба, он автоматически расшифровывает аудиодорожку в субтитры. И так как субтитры - это данные, это тексты, это самое ценное, то на чём Google обучает, в том числе Gemini. И по IP апи забрать субтитры нельзя. Но у нас написан на этих же Google чудесных таблицах парсер, который сможет собирать эти субтитры. Единственное ограничение этих субтитров -
это ограничение Google таблиц, что в одну ячейку Google таблицы можно поместить всего 50.000 символов. Это ограничение Google таблиц. Мы с ним ничего сделать не можем. Поэтому, если ролик, например, и средняя скорость, когда человек говорит- это максимум 1.000 символов в минуту. То есть, если ролик 50 минут, соответственно, вы можете 50.000 символов собрать. Если ролик 2 часа, мы соберём вам, но всё равно отрежем 50.000 символов, потому что больше в ячейку не влазит. Но мы сейчас как раз посвящались и, наверное, сделаем, что у нас будет несколько ячеек. То есть, если вы захотите получить текст из трёхчасового ролика, статью,
мы тоже её сделаем. Просто это будет две-три четыре ячейки, да, с которыми придётся работать. Вот единственное ограничение. Ну давайте попробуем. Возьмём, например, доктора Длина. Да, мы можем, например, я хочу отфильтровать не знаю, ролики по длине. Вот всем интересно шарцы, да, какие же шарцы залетели, например, у этого доктора. И я делаю одну простую вещь. Я беру фильтр, добавляю и фильтрую ролики по количеству просмотров. Шорцы, как правило, могут набирать существенно больше, чем чем а квадратные ролики. Такое часто бывает. Ну, к примеру, смотрите, я выделяю, давайте возьмём там, ну, вот сколько тут, чтобы не было супербольших, возьмём 15
роликов. Здесь очень важно. Вот я их просто выделил и копировал. Ctrl C нажал, запомнил. 15 роликов. У нас субтитры создаются. на специальной вкладке, которая будет называться субтитры. Видите, тут внизу написано субтитры. И если я сейчас, а, перехожу на какую-нибудь вкладку, да, давайте, вот сейчас я вкладку удалю и сюда вставляю, очень важно, вставляем, начиная со второй ячейки. Именно со второй, не с первой. Почему со второй? Потому что у нас, ээ, первая ячейка - это оглавление, название, описание и длина. Вот я взял, ну, для примера 11 ссылок и иду в меню. У нас в меню есть супер,
самая крутая, самая сложная функция, потому что YouTube защищается от скачивания спа от сбора своих субтитров. Это получить расшифровку роликов, который мы взяли. Вы можете вставить и 100 ссылок, но как опыт показывает это ещё одно ограничение Google таблиц, а он вам пришлёт эти все расшифровку 100 роликов. Если ролики короткие, успеет до 6 минут, вы получите. Если нет, то Google таблица обрезает, э, соединение с Ютубом, не даёт. Поэтому сильно не злоупотребляйте. Ну, ставьте 15, 20, 30, сколько на нам нужно. Вот я набираю субтитры видео по ссылке из столбца. А, всё. И сейчас мы получим самое ценное, самое
дорогое, что есть. Мы получим расшифровку этих роликов. По сути, это тексты, уникальные тексты, которые мы можем переписывать, которые мы можем анализировать, которые мы можем из них делать посты, да? Это то, с чего мы начинали, тренировались. И здесь как раз нам понадобятся функции Gemini для переписки или функции GPT. Субтитры нужно иметь терпение, так как это не AP. То есть я, например, когда работаю по IP, у меня сразу 50 роликов приходит. Максимальный запрос. Всё, успех. 10 из десяти. Видите, я, ну, буквально за 20 секунд получил, по сути, расшифровку вот этих роликов, которые выбрал. Видите, у них у
всех разные. И у меня ещё автоматически сделана такая штука. Я считаю количество символов. Видите? То есть, когда прилетают к вам ролики внутрь Google таблицы, моя система, ну, это обычная формула, сразу считает, сколько символов содержится в какой статье. И я понимаю, да, вот видите, 4 минуты 3.500 символов. Ну, значит, он не быстро говорит, качественно и хорошо. Всё, я получил самое ценное. Я получил то, за что бьются все корпорации с Ютуба. Ну, скажем так, абсолютно быстро и легко. И дальше я могу в этой нише, например, доктора Длина писать из этого статьи то, что мы с вами говорили.
Ну, первое, что нужно делать, да, вот тут мы ещё не доделали. Мне нужно добавить столбец, да, вставить столбец справа. Вот. На самом деле у нас столбцы будут. Мы можем писать любые промты. И вот здесь начинается уже вот эта прелесть мультимодальности. Это соединение одной нейронки с другой. То есть одна нейронка написала партер. Вторая нейронка с помощью кода, который написан, собрала нам тексты, собрала нам все YouTube каналы, все ролики с этих каналов. И мы можем сюда написать первый промт. Ну, например, а напиши мне кратко, о чём эти 10 роликов. Ну вот, не хочу я читать. кратко. То
есть, чтобы я понял, напиши мне кратко, о чём эти 10 роликов, буквально по 3 тиреп предложений о каждом. То есть я пишу запрос промт в Google таблице, да? И дальше что я делаю? Я кликаю на ячейку, нажимаю равно. То есть нам надо активировать формулу, да? Ну давайте возьмём, например, барт. Пишу слово барт. Барт - это чтобы у нас запустилось э Gemini. Открываю скобку, нажимаю запрос, ставлю точку с запятой. А теперь смотрите, этому я вас не учил, но это тоже нужно делать. Чтобы, например, проанализировать все эти тексты, я могу задать диапазон. То есть я ставлю вот
сюда ячейку, да, держу клавишу Shift, зажал клавишу Shift. Ну или вы просто ставите двоеточие и вот начинаю накликивать, какие тексты мне нужно проанализировать. Видите? То есть я вот кликаю, и он в формуле пишет. Или просто ставите двоеточие и давайте до F9. То есть вот проанализирую мне все эти семь текстов. То есть я задал диапазон всех роликов. Закрываю и поехали. Получаю первый короткий анализ на небольшом объёме данных. Как к большому мы перейдём, там немножко посложнее, но я сейчас попросил э его проанализировать вот эти ролики доктора Длина, чтобы он мне написал. Всё готово. Видите, и он мне
пишет пункт один. Замена сахара. Видеорассказы о вреде избытка сахара. 2-три. Всё, я научился, ну или показываю вам, как, например, я могу быстро, не читая все эти тексты, сделать коротенькие, ну, как выдержка, да, короткое содержание этого ролика. Как пример. Здесь же я могу попросить переписать эту статью, этот текст, который мы получили. Например, сделаем мне пост для Телеграма о замене сахара. А в чём прелесть такой работы? У Чата GPT и у Джемени и у Клода всё равно есть некая шаблонность. То есть когда вы будете писать, например, тыся, а я уже это делал, тыся текстов о здоровье, есть
одни и те же вводные фразы, всё равно клише он повторяется. А когда вы берёте расшифровку реальной речи, понятно, что у этой расшифровки есть автор, да, и у автора, ну, не хорошо брать как бы в оригинале, то мы можем переписать суть того, что он сказал, и дальше я могу сделать следующий промт. То есть я могу здесь, да, сделать, могу сделать соседнюю ячейку. А, ну давайте просто будем не забывать, что вот если я нажму, видите, у нас формула, то есть это не текст, это формула. Вот она, я выделил. Поэтому мы делаем то, что у меня неделю все
в группах спрашивали. Ctrl C я копировал на выделенной ячейке и Ctrl Shift V вставил вставил значение. Ctrl Shift V вставить значение. Видите, я кликаю на ячейку. Теперь это не формула, теперь это текст. Понятно, да? Чтобы ещё раз у меня не активировалось, да? И чем удобна таблица? Она всё равно все ваши последовательно запоминает работы. Мы делаем следующую вещь, которая тоже очень важна. Вот я вставил ещё один столбец. Я пишу ещё один промт, например, а, прочитай текст, что я тебе дам, и основываясь на мнении автора, да, по итогам обучения всё, что я делаю в этой таблице, вы
получите себе в изучение. То есть эти данные, которые есть у меня в таблице, я вам дам. Вы можете их, когда вы копируете таблицу, вы можете их удалить, можете оставить, можете в новую таблицу. Может быть, я вам дам ссылку на таблицу. Вы можете 10 раз всё копировать, если нужно, чтобы вы видели примеры, как это работает. Да, я пишу, значит, основываясь на мнение автора, напиши мне, не знаю, пост о здоровье для Telegram на 500 символов. То есть я попрошу сейчас Нейронную сеть, чтобы она не придумывала что-то сама на эту тему, а взяла то, что говорит лидер рынка,
у которого огромное количество просмотров, много лайков, взяла его мнение, переписала, немножко она что-то от себя добавит, и мы получим абсолютно оригинальный текст, абсолютно уникальный, без всяких клише, которые делают нейронные сети. И вот здесь я вам, кстати, покажу вторую функцию. Например, в этой же таблице я хочу поработать с чатом GPT, не с бардом. Но чтобы включить чат GPT, у меня написана функция такая очень скромная, называется AI. Это Антон Игоревич, то есть я AI Бог. Антон Игоревич Богатушин, да? Иа Бог - это такая функция, чтобы у вас запустился чат GPT. Вы открываете также скобочку. Логика вся та
же самая. Первое - это у вас запрос, что нужно сделать. Дальше точка запятой. И вы кликаете на этот текст, который я хочу переписать. И уже в таблице у меня работает не Gemini, а работает Chat GPT. Нажимаю всё. И я в одной таблице могу и Gmini, и Chat GPT, идт, и без VPN. В этом кайф. Единственное, что если GMI работает бесплатно, то вот за такой запрос чат GPT с меня возьмёт там 01 цента. Ну, копейки. Я в день целый день работал на чате GPT на модельке mini потратил 28 центов. Ну, чтобы вы понимали, я упоролся 5
часов у меня вот нон-стоп шла работа, я даже доллары не потратил. Правда, я не делал 1.000 статей сразу, но очень сложно потратить большие деньги. Всё. И я получил из ролика, если мне он понравился, то, что говорит доктор Длин из текста, а, а, получил текст, который говорит о здоровье и о том, что может быть заменителем сахара. Да, здесь он пишет: "Здравствуйте, я Сергей Длин". Да, если вы хотите адаптировать текст под себя, тогда вы в пром пишите, а, перепишу этот текст от меня, зовут меня там Николай Лапин, да, и вот я хочу получить такой текст. Просто пишите
себя, и он меняет этого доктора на себя. И вы можете даже руками, если хотите, что-то поменять. Не забываем, когда получили ответ, копируем Ctrl C, Ctrl, Shift V, чтобы это была не формула. Бывает такой, вот вы поработали, составили 100 текстов, потом заходите в таблицу и что-то где-то какой-то символ поменяли, и оно начинает все тексты переново отправлять на переработку. Чтобы такого не было, отправлять в Google или в чат GPT и потом вам ответы слать. Поэтому всё копируйте. Это моя личная вам рекомендация. Я так попал на большое количество денег, когда работал с большим количеством символов. Вот ещё одна
модель такая, да. Ну и, соответственно, вы можете расшифровать все ролики, вы можете вставлять сколько угодно их сюда, но надо только понимать, что вот вы вставили, да, если вы ставите вниз ещё ссылки, он всё равно эти первые ссылки будет делать. Вот. Э, но мы получили вот такие текстовые статьи, например, давайте вам покажу вообще, ну, о возможностях. Иногда, э, если вы очень много, а, захотите, ээ, собрать данных, например, длинных роликов, ну, давайте что-нибудь такое подлиннее возьмём, он тоже это сделает. Но ещё раз, чтобы внимание, чтобы ролики были недлиннее. Давайте вот побольше возьму. Не для чтобы ролики были
не длиннее часа желательно, потому что час он долго будет собирать данные расшифровывать. Ну давайте возьму 30. Иногда может так случиться, так как это не AP, здесь нет гарантии. Очень долго он собирает или YouTube их не отдаёт, он вам принесёт, напишет ноль. Ну типа не получилось. Извините, ничего страшного. Вы тогда уменьшите количество, да? Вот я сейчас ещё раз иду сюда, уменьшаю количество. То есть сейчас я увеличу, вернее, количество ссылок. Вот я беру 30. Давайте поэкспериментируем и прошу его ещё раз собрать мне все субтитры всех тридцати роликов. Умоляю вас, только 500 не пихайте. Вот есть такие у
меня умельцы. 500 spрcл, на тебе 500 ссылок. Принеси мне 500 текстов. Не получится сразу. Мы сделаем потом для больших каналов. называется медленный партинг, когда он нам будет по одному тексту бегать, переносить. Сделаем просто пакетно быстрее работает. И пока мы анализируем там 30, 50, 100 роликов, всё удачно. Но 500 надо по одному. Сбегал, принёс. Сбегал, принёс. Мы это тоже выпустим. И прелесть нашей библиотеки в том, что вам не надо ничего будет переподключать. У вас просто появится ещё одно меню- это получать по одному тексту в таблицу. Всё. И тогда вы будете собирать вообще все тексты, которые захотите,
без ограничений. Пока такое не сделали, но запрос на это уже есть. Соответственно, у нас в разработке в плане стоит, чтобы мы собирали вообще со всех 500 роликов и не думали. Вот единственный минус, что когда вы начнёте в одной таблице, у вас 300 каналов, да? А у вас 300 каналов, э, там 10.000 роликов. Каждый ролик вы начинаете расшифровывать, у вас таблица начинает пухнуть, большая становится, да, и в один прекрасный момент начнёт тормозить. То есть вы достигнете 5 млн символов. Вот видите, я запустил 30 роликов. Не так это быстро, как собирать статистику с канала, но он нам
сейчас притащит ээ либо часть, либо какую-то напишет ошибку. Но мы понимаем, что, ну, как бы до идеала далеко. Нет, смотрите, всё, все все 29 ээ, значит, роликов он успешненько съел. Вот они. И сейчас он нам вставит эти ссылочки, ставит расшифровку и статистику этих роликов. Вот надо немножко подождать, да? Вот он их соседнюю нам вкладочку. То есть он вставляет не сюда, а он вставляет вот сюда соседнюю вкладочку. Давайте я сейчас сделаю вот так, чтобы было видно. Ну вот так хотя бы. Yeah.