[Música] Então a partir dessa eh estrutura né das tpus eh mencionada pelo hilder a gente eh utilizou né a eh a petição inicial o assunto principal e estruturou esse assunto principal conforme essa hierarquia né que o hilder mencionou a priori uma uma hierarquia de três níveis né o hilder falou da motivação né dessa dessas escolhas e como chegamos né nessa nessa hierarquia e elaboramos alguns modelos de classificação eh eu destaco aqui que ao longo do projeto nós fizemos uma série de experimentos e esses experimentos variando quanto à entrada quanto ao modelo quanto à representação dos
dados e nós chegamos ao final do projeto com dois modelos de classificação um modelo que nós chamamos aqui de abordagem de grupo e um outro modelo que nós chamamos de abordagem hierárquica então nós temos dois modelos de classificação em que ambos o objetivo é classificar o assunto né recebe a petição inicial e classifica no assunto mas seguem estratégias diferentes tá para ambas as abordagens nós passamos por algumas etapas iniciais eh antes de chegar no no modo tá então vou falar dessas etapas iniciais para posteriormente detalhar um pouco mais esses modelos a primeira etapa que nós
utilizamos foi realizar o pré-processamento dos dados esse pré-processamento dos dados e Mais especificamente faz uso de uma função chamada trata texto desenvolvida no âmbito do projeto do do penu CNJ que tem como objetivo padronizar o texto conforme alguns termos jurídicos tais como as ações que são citadas no documento Então o texto da petição inicial inicialmente ele passa por essa etapa de pré-processamento ou seja ele é submetido a essa função trata texto para poder fazer a padronização dos termos jurídicos a função trata texto especificamente eh nós teremos capacitações eh ao longo da semana né que vai
explicar em mais detalhes o funcionamento dela mas a priori ela contempla algumas das dessas funções né como tratar a formatação do texto tratar a abreviatura tratar as siglas tratar os caracteres especiais aqui a gente tem uma limitação não é nenhuma limitação é que o vocabulário que a gente utiliza ele tem umas restrições em relação a alguns caracteres especiais então esses caracteres especiais Eles foram tratados eh faz o tratamento do termo da legislação e da jurisprudência Então essas são as funções dentro do trat texto que são utilizadas para essa padronização do texto da petição inicial daí
aqui do ladinho a a gente tem uma tabela contemplando alguns exemplos tá eh o exemplo de entrada e o exemplo de saída por exemplo se a gente tiver um trecho dentro da petição inicial que tem item 02 do artigo 473 da CLT Então esse trechinho da petição inicial pela função trata texto vai ser convertido para esse outro exemplo aqui de saída né que vai se transformar em item 02 do artigo 473 da validação das leis do trabalho então aqui teve uma modificação na palavra artigo e uma modificação na palavra CLT Aí uma outra um outro
exemplo se a gente tiver arte ponto três quebras de linha primeiro da lei 3819 de 2019 Então esse trechinho da petição inicial seria transformado nesse outro artigo um da política nacional de prevenção da automutilação e do suicídio então aqui a gente tem alguns exemplos né ou seja do que é que a a função trata texto ela vai fazer em relação ao texto da petição inicial eh de todo modo o objetivo é padronizar esses termos jurídicos eh cabe aqui falar que eh a gente fez alguns experimentos Mas como Eu mencionei para vocês ao longo do projeto
nós fizemos uma série de experimentos e fizemos experimentos utilizando a função trata texto e não utilizando nessa etapa de pré-processamento daí a escolha da utilização dessa função trata texto foi porque nós obtivemos melhor resultados quando utilizamos a função trat texto portanto a gente a partir desses resultados né isso nos influenciou ao utilizar essa função trat texto para o pré-processamento dos dados Então a primeira etapa que nós temos para o classificador independentemente da abordagem se de grupo ou hierárquica é utilizar esse pré-processamento por meio da função trat texto tá então após isso após esse pré-processamento eh
o textinho já pré-processada ele é eh representado por meio de embeds né E esses embeds Eles foram gerados utilizando um modelo de linguagem prét treinado chamado de Lig Albert PT a estrutura dos classificadores eh está pautada na na arquitetura do Bert então a gente faz uso dos modelos de linguagem conforme essa arquitetura e especificamente a unió treinou um modelo de linguagem com documentos jurídicos para que pudesse melhor compreender o contexto dos documentos jurídicos né portanto nós prét treinamos o modelo de linguagem chamado Lig Albert PT e foi esse modelo de linguagem que nós utilizamos para
gerar os embeds dos textos da petição inicial que foram pré-processados utilizando a função trat texto tá então inicialmente a gente tem o texto da petição inicial pre-process aplicando a função trata texto e depois gera os embeds utilizando o modelo de linguagem prét treinado libert Ok essas etapas elas são similares tanto para abordagem de grupo como para a abordagem hierárquica Ok dando sequência né eh essas etapas iniciais que nós mencionamos aí da do pré-processamento e da geração do embed para a entrada a gente agora eh vai falar um pouco sobre os modelos de classificação Como eu
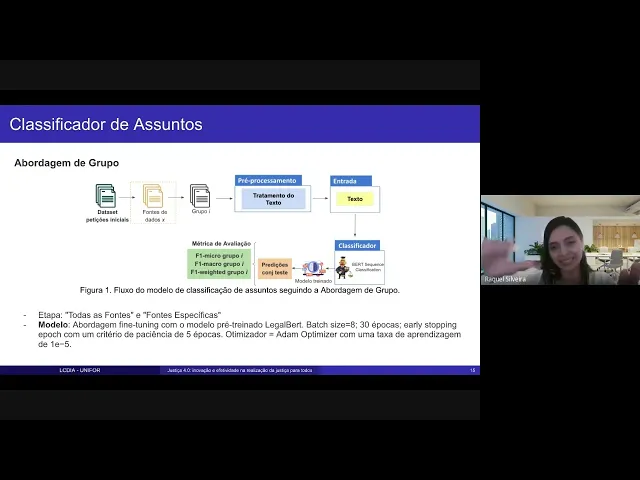
havia mencionado anteriormente Nós temos duas ab de classificação de assuntos uma abordagem que nós chamamos de abordagem de grupo tá nessa abordagem de grupo eh o objetivo tal como a a abordagem hierárquica é fazer a classificação de uma petição inicial no assunto folha né conforme o hild explicou lá os níveis da hierarquia tá eh sendo que nessa abordagem de grupo eh se assume que a pessoa já sabe que o usuário já sabe qual é o assunto raiz então o grupo aqui tratado se refere ao assunto raiz então Eh se considera que o usuário conhece esse
assunto raiz ele vai enviar a petição inicial conforme esse assunto Raiz e o classificador ele vai fazer a classificação dessa petição inicial de assunto folha correspondente a esse assunto raiz para exemplificar nós temos aqui por exemplo um assunto raiz é o direito do consumidor Então esse direito do consumidor é que a gente considera lá como grupo e o o usuário ele vai enviar uma petição do Direito do Consumidor e o classificador ele vai fazer a predição de algum dos assuntos dentro do Direito do Consumidor que é esse assunto aqui denominado nível três que é o
assunto folha tá então para esse processo acontecer o treino se deu pegando o dataset das petições iniciais eu vou saltar aqui essa fonte de dados para falar posteriormente eh separando esse dataset em grupos onde cada grupo corresponde a um assunto raiz né E nessa divisão hierárquica nós temos nove assuntos raiz então nós vamos ter nove grupos cada um desses grupos separadamente vai seguir aqui no processo de treino do classificador eh passando pela etapa de pré-processamento como já mencionado aqui utiliza o trat texto depois pela entrada que é a representação dos embeds utilizando o liga Albert
PT e depois treinando aqui no classificador onde aqui a gente utiliza a arquitetura do Bert né como essa estrutura de classificação né do modelo de classificação na tarefa de classificação de uma de uma sentença né onde a sentença que é o documento é esse texto que é passado como entrada daí o modelo é treinado a gente faz as predições no conjunto de teste desse grupo né e faz a avaliação quanto ao F1 micro macro E ponderado deste grupo tá Então essa é a sequência de passos que nós utilizamos aqui para gerar o modelo de classificação
seguindo a abordagem de grupo tá eh esse modelo né aqui embaixo Mais especificamente ele segue uma abordagem de fitan né do modelo pré-treino liga Albert então a gente utiliza aqui o esse mesmo modelo de linguagem né dentro do modelo de classificação utilizamos como eh tamanho do Bet o com 30 épocas aplicamos também o stop com o critério de paciência de cinco épocas o otimizador o Ada como a taxa de aprendizagem de de 1 e-5 tá Então essas são algumas características mais pontuais desse desse modelo Ok então esse processo como mencionado não é seguindo essas essas
características do modelo é feito para cada um dos grupos então para cada um dos nove grupos nós seguimos essa etapa portanto ao final nós temos nessa estrutura nove modelos de classificação um modelinho para cada um dos grupos tá sendo que nós eh utilizamos ainda aqui uma etapa específica que foi a separação das fontes de dados eh anteriormente eu havia mencionado para vocês que nós fizemos uma análise quanto a distribuição dos dados em relação ao tipo do tribunal o tipo federal estadual e do trabalho então nós adicionamos aqui de forma complementar de forma adicional uma etapa
de separar esse conjunto de dados conforme o tipo do tribunal portanto eh nós seguimos uma uma uma etapa dessas né gerando nove modelos de classificação um para cada grupo contemplando todas as fontes de dados contemplando todos os tribunais e fizemos uma outra estratégia de separar esses documentos conforme o tipo do tribunal então a gente pegou aqui o o conjunto de dados separou né as fontes específicas pegamos aqui os a apenas os dados correspondente ao tipo do tribunal do trabalho por exemplo obtivemos quais são os grupos desses tribunais do trabalho e fizemos o modelos de classificação
para cada um desse grupo depois obtivemos aqui os dados relacionados apenas aos tribunais estaduais separamos os grupos desses desses dados e seguimos aqui para gerar outros modelos de classificação para eles e depois fizemos aqui a separação pelo os dados eh Federal né pelos tribunais que são do tipo Federal e também separamos os grupos geramos outros modelos de classificação então além de fazer a geração dos modelos de classificação para todos os dados separando por grupo mas considerando todas as fontes eh de dados nós também fizemos uma etapa adicional que foi separar esse conjunto de dados conforme
os tipos de tribunal especificamente do trabalho federal e estadual geramos para cada um deles modelos conforme os grupos desses dessas fontes de dados como nem todos os tipos de tribunal contempla todos os grupos a gente pôs aqui uma tabelinha de modo a dizer que sim ó quando a gente utiliza todos os dados nós vamos ter nove modelos de classificação porque nós temos esses nove grupos quando a gente utiliza os dados eh apenas dos tribunais federais tem dois grupos que não são contemplados nesses tribunais ou seja esses tribunais não têm assuntos relacionados ao direito processual penal
nem ao direito do trabalho portanto ao utilizar os tipos de Tribunal Federal nós geramos esses modelos né conforme esses grupos né então nós geramos um modelinho para o direito previdenciário contemplando apenas os dados dos tribunais federais um outro para o direito do tributário um outro para o direito civil e assim por diante então nós geramos esses modelinhos aqui para as fontes do Tribunal Federal quando a gente olha para o Tribunal do Trabalho esse Tribunal do Trabalho ele só contempla dados de dois grupos do Direito Processual Civil e do trabalho e do direito do trabalho então
ao utilizar essas fontes de dados foram gerados dois modelinhos de classificação um para o grupo Direito Processual Civil do trabalho e outro para o direito do trabalho e quando a gente utiliza as fontes estadual só não tem o direito do trabalho tem todos os outros grupos não tem do trabalho então Aqui nós temos Eh toda essa quantidade de modelos de classificação que foram gerados A partir dessa abordagem de grupo uma estratégia né utilizando todos os dados de todos os tribunais e outras estratégias separando aqui por Fontes específicas Federal trabalho e estadual então além dessa abordagem
de grupo nós eh fizemos uma outra abordagem ou seja agora a gente segue para uma outra estrutura do classificador que é o classificador que segue a abordagem hierárquica eh eu havia mencionado que na abordagem do grupo O que que a gente tem a gente tem a petição inicial e o algoritmo ele vai fazer a classificação do assunto dessa petição inicial levando em consideração que o usuário informa qual é o grupo né ou seja Qual é aquele assunto eh raiz na abordagem hierárquica o usuário ele não vai informar o assunto raiz então o que nós vamos
fazer é receber a petição inicial e o algoritmo vai fazer a predição do assunto independentemente de qual grupo ele esteja associado porque essa informação do grupo Ela não é tida como entrada A entrada é apenas a petição inicial Tá então portanto dado o conjunto de dados de petições iniciais vou saltar aqui a fonte de dados de novo a gente passa pela etapa de pré-processamento onde nesse pré-processamento há o tratamento do texto depois esse texto ele é convertido nos embeds utilizando o Lig Albert e é submetido a um classificador hierárquico né para esse classificador hierárquico a
gente utiliza aqui uma estratégia né do contrastive learning mais A Hierarquia de assuntos né para poder fazer eh essa classificação hierárquica gera-se aqui um modelo treinado esse modelo treinado a gente utiliza aqui com as edições no conjunto de teste fazendo também a avaliação eh dessas métricas né do fu micro macro e ponderado tá mas especificamente esse classificador ele segue aqui uma abordagem de promp Titan né para a classificação hierárquica de textos né que é uma abordagem que fizemos inspirada em um paper né nesse paper do oang eal 2022 utilizamos também um Bet de tamanho 8
com 30 épocas com early stop com critério de paciência de c épocas um otimizador Adam com uma taxa de aprendizagem de eh 3E -5 tá então aqui eh o desafio ele é um tanto quanto maior porque nós vamos ter mais classes né para o classificador poder classificar né ao todo nós temos 153 assuntos eh compreendidos lá no nível folha para o classificador fazer a classificação Então a gente tem um desafio um tanto quanto maior né Eh e a a saída vai ser eh como se trata de um classificador hierárquico o classificador ele vai poder nos
informar todo esse nível né de hierarquia nosso objetivo é conhecer o nível três né do do da petição inicial mas por se Tratado de um classificador hierárquico a classe ela é modelada com toda essa hierarquia ou seja com o nível um com o nível dois e com o nível três então a a predição do classificador vai nos informar também esses esses três níveis né Por se tratar do nível do do classificador hierárquico Apesar de que o nosso foco é saber o nível três mas todo esse essa hierarquia ela é enviada como saída e com a
taxa de convicção eh de cada uma desses desses níveis tá vai sair apenas um único né Apesar de que no modelo que que foi disponibilizado vai sair apenas um um único né mas ele vai informar qual é a taxa de convicção de cada um dos outros ou seja assim ó eh o assunto que eu que fez a predição com maior probabilidade é esse mas tem um outro assunto que é probabilidade é esse outro um outro assunto que é esse outro a saída vai informar os demais né os demais com a taxa de convicção de cada
um deles de todos a gente pôs essa a saída desta forma então tanto a abordagem de grupo como a abordagem hierárquica a gente tem como saída né o aquele de maior convicção mas também é informado os outros os outros assuntos com a sua taxa de convicção né porque por vezes né ou seja não é o primeiro mas o segundo está bem próximo a gente até assim teve uma uma grande discussão com o pessoal eh do direito né domínio do negócio mesmo e eles até percebem se ó tem determinados processos que eles são realmente vinculados a
dois Assuntos Então a a essa taxa de convicção ela acaba sendo próxima mas o o a gente tem essa saída identificando-se isso né qual é o assunto de maior convicção e quais são todos os outros com a sua respectiva taxa de convicção para ambas as abordagens para eh ambas as abordagens nós utilizamos eh nós mencionamos aqui né Qual foi a infraestrutura eh de treino né que nós utilizamos né então nós eh tivemos máquinas diversas aqui para poder fazer o processo do treino né desses desses classificadores eh havia mencionado mas vale destacar que nós fizemos uma
série de experimentos então a gente precisou de de recurso para esses vários experimentos que foram realizados ao longo do projeto né Então e nós utilizamos essas máquinas com essa infraestrutura especificamente tá eh nós temos aqui também o tempo de treino eh aproximado né em média eh para cada uma das abordagens então na abordagem de grupo nós tivemos em média né nessa estrutura final aqui eh o horas para o treino por modelo né e Vale destacar aqui que nós mencionamos que são gerados vários modelos de classificação não apenas um só né então para cada um desses
modelinhos a gente tem alguns deles que demoram um pouco mais outros um pouco menos porque quando a gente faz aqui um filtro por exemplo na fonte específica Federal a quantidade de dados É menor né então leva um pouco menos de tempo mas em média cada um dos modelos aqui nós treinamos em cerca de 8 horas em média tá tá e na abordagem hierárquica nós eh temos em média 76 horas para treinar por modelo eu acabei saltando aqui mas eu vou volar só para para explicar essa partezinha da fonte de dados eh Eu segui aqui explicando
que nós eh geramos um modelo né de classificação hierárquica para todos os dados então aqui a gente gerou um modelo mas nós também aplicamos a mesma estratégia lá da abordagem de grupo de separar esse conjunto de dados por fontes de dados Então nós pegamos aqui o dataset e separamos pelos tribunais do trabalho aí fizemos todo esse processo geramos um outro modelo eh fizemos também separando por a fonte de dados Estadual geramos um outro modelo e fizemos também o Federal e geramos um outro modelo então nós temos quatro modelinhos aqui que seguem pela abordagem hierárquica daí
em média esses quatro modelinhos Eles foram eh treinados em 76 horas tá então nós temos aqui vários modelos né na abordagem de grupo que cada um deles leva em média 8 horas e nós temos aqui quatro modelinhos gerados pela abordagem hierárquica que em média leva 76 horas então seguindo Eh esses experimentos né a gente vai fazendo Os experimentos vai avaliando a gente teve diferentes momentos aí de ter modelos diferentes de classificação Como Eu mencionei que utilizava uma representação de dados diferente eh mas nós chegamos n essa etapa final com essas abordagens com esses modelinhos e
com esses resultados que eu apresentarei agora né então nós temos aqui a separação dos resultados pela abordagem de grupo e hierárquica e o treinamento conforme todas as fontes de dados e separadamente pelas Fontes específicas né então nós temos aqui os resultados eh para eh cada um dos níveis na abordagem hierárquica esse N1 n2 e N3 correspond onde ao nível um que é o nível raiz ao nível dois que é aquele intermediário e ao nível três que é o nível do assunto folha então nós acabamos nos concentrando e nesse nível três né para fazer uma comparação
com a abordagem de grupo tá eh e também verificando aqui de forma separadinha né tanto todas as fontes como de fontes específicas e o que a gente observa aqui nessa primeira avaliação é que a abordagem de grupo ela tem resultados superiores a abordagem hierárquica quando a gente olha aqui para o nível três que é o nível que a gente pode comparar ambas né mas é que a gente eh tem eh uma suposição né de que quando o usuário ele informa o grupo ele informa já o assunto Raiz A gente já tem parte da informação eh
sendo eh tratada pelo classificador e a gente tem menos classes a serem tratadas no processo de classificação quando a gente não tem esse grupo não tem o assunto raiz eh O O classificador ele tem um fio maior né que é classificar aqui em 153 classes independentemente de qual seja o nível raiz né então por conta disso né o classificador de grupo ele tem resultados maiores tá quando a gente olha eh eh eh nas fontes separadas eh da mesma forma né o classificador utilizando essa abordagem de grupo ele também tem resultados maiores se comparado com a
classificação hierárquica então aqui assim é qual a decisão né utilizar eh cada um desses classificadores vai de encontro se se tem essa informação inicial do assunto raiz né se se tem eh vale mais a pena utilizar aqui o classificador de grupo uma vez que ele vai ter resultados melhores em relação ao classificador hierárquico contudo se essa informação ela não é conhecida nós temos a opção de utilizar esse esse classificador hierárquico que ele já vai fazer a predição de ambos tá nós apresentamos aqui também eh mostrando os resultados conforme o tipo do tributo tribunal Ou seja
quando a gente separa né a gente separa as fontes de dados a gente ó a gente separou pelo Tribunal Federal pelo tribunal do trabalho e pelo tribunal Estadual então nós também temos aqui esses resultados separadinho né por cada uma dessas Fontes quando a gente utiliza as fontes específicas para cada tipo do tribunal e quando a gente consolida assim ó eu treinei com todas as fontes qual o resultado eu teria se fosse considerado apenas o Tribunal Federal então nós temos aqui esses esses resultados né para para cada um eh desses desses tribunais Ok tem alguns tribunais
que os resultados eles são melhores né Ou seja que o Tribunal Federal os resultados são melhores se comparados com tribunal do trabalho se comparado com o tribunal Estadual [Música] ok h