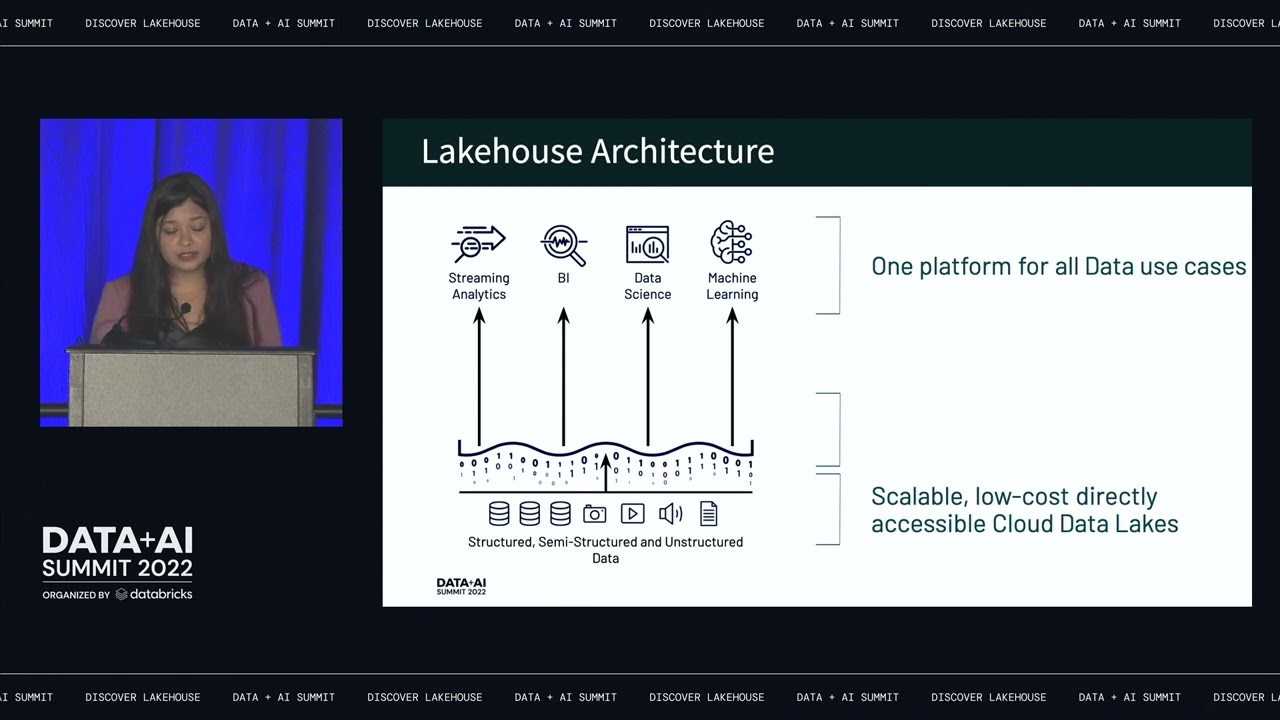
databricks Lakehouse platform architecture and security fundamentals data reliability and performance in this video you'll learn about the importance of data reliability and performance on platform architecture Define delta Lake and describe how Photon improves the performance of The databricks Lakehouse platform first we'll address why data reliability and performance is important it is common knowledge that bad data in equals bad data out so the data used to build business insights and draw actionable conclusions needs to be reliable and clean while data Lakes are a great solution for holding large quantities of raw data they lack important features
for data reliability and quality often leading them to be called Data swamps also data Lakes don't often offer as good of performance as that of data warehouses some of the problems data Engineers May encounter when using a standard data Lake include a lack of acid transaction support making it impossible to mix updates of pins and reads a lack of schema enforcement creating inconsistent and low quality data and a lack of integration with the data catalog resulting in dark data and no single source of Truth these can bring the reliability of the available data in a
data Lake into question as for performance using object storage means data is mostly kept in immutable files leading to issues such as ineffective partitioning and having too many small files partitioning is sometimes used as a poor man's indexing practice by data Engineers leading to hundreds of Dev hours lost tuning file sizes to improve performance in the end partitioning tends to be ineffective if the wrong field was selected for partitioning or due to high cardinality columns and because data Lake slack transactions support appending new data takes the shape of Simply adding new files the small file
problem however is a known root cause of query performance degradation the databricks lake house platform solves these issues with two foundational Technologies Delta Lake and photon Delta lake is a file-based open source storage format it provides guarantees for acid transactions meaning no partial or corrupted files scalable data and metadata handling leveraging spark to scale out all the metadata processing handling metadata for petabyte scale tables audit history and time travel by providing a transaction log with details about every change to data providing a full audit Trail including the ability to revert to earlier versions for rollbacks
or to reproduce experiments schema enforcement and schema Evolution preventing the insertion of data with the wrong schema while also allowing table schema to be explicitly and safely changed to accommodate ever-changing data support for deletes updates and merges which is rare for a distributed processing framework to support this allows Delta Lake to accommodate complex use cases such as change data capture slowly changing Dimension operations and streaming upserts to name a few and lastly a unified streaming and batch data processing allowing data teams to work across a wide variety of data latencies from streaming data ingestion to
batch history backfill to interactive queries they all work from the start Delta Lake runs on top of existing data lakes and is compatible with Apache spark and other processing engines Delta Lake uses Delta tables which are based on Apache parquet a common format for structuring data currently used by many organizations this similarity makes switching from existing parquet tables to Delta tables quick and easy Delta tables are also usable with semi-structured and unstructured data providing versioning reliability metadata management and time travel capabilities making these types of data more manageable the key to all these features and
functions is the Delta Lake transaction log this ordered record of every transaction makes it possible to accomplish a multi-user work environment because every transaction is accounted for the transaction log acts as a single source of Truth so that the databricks Lakehouse platform always presents users with correct views of the data when a user reads a Delta lake table for the first time or runs a new query on an Open Table spark checks the transaction log for new transactions that have been posted to the table if a change exists spark updates the table this ensures users
are working with the most up-to-date information and the user table is synchronized with the master record it also prevents the user from making divergent or conflicting changes to the table and finally Delta lake is an open source project meaning it provides flexibility to your data management infrastructure you aren't limited to storing data in a single cloud provider and you can truly engage in a multi-cloud system additionally databricks has a robust partner solution ecosystem allowing you to work with the right tools for your use case next let's explore Photon the architecture of the lake house Paradigm
can pose challenges with the underlying query execution engine for accessing and processing structured and unstructured data to support the lake house Paradigm the execution engine has to provide the same performance as a data warehouse while still having the scalability of a data Lake and the solution in the databricks lighthouse platform architecture for these challenges is photon photon is the next Generation query engine it provides dramatic infrastructure cost savings where typical customers are seeing up to an 80 total cost of ownership savings over the traditional databricks runtime Spark photon is compatible with spark apis implementing a
more General execution framework for efficient processing of data with support of the spark apis so with Photon you see increased speed for use cases such as data ingestion ETL streaming data science and interactive queries directly on your data Lake as databricks has evolved over the years query performance has steadily increased powered by spark and thousands of optimization packages as part of the databricks runtime Photon offers two times the speed per the tpcds one terabyte Benchmark compared to the latest dbr versions some customers have reported observing significant speed UPS using Photon on workloads such as SQL
based jobs Internet of Things use cases data privacy and compliance and loading data into Delta and parquet photon is compatible with the Apache spark data frame and SQL apis to allow workloads to run without having to make any code changes Photon coordinates work on resources transparently accelerating portions of SQL and Spark queries without tuning or user intervention while Photon started out focusing on SQL use cases it has evolved in scope to accelerate all data and Analytics workloads photon is the first purpose-built lake house engine that can be found as a key feature for data performance
and The databricks Lakehouse platform unified governance and security in this video you'll learn about the importance of having a unified governance and security structure the available security features Unity catalog and Delta sharing and the control and data planes of the databricks Lakehouse platform while it's important to make high quality data available to data teams the more individual access points added to a system such as users groups or external connectors higher the risk of data breaches along any of those lines the and any breach has long lasting negative impacts on a business and their brand there
are several challenges to data and AI governance such as the diversity of data and AI assets as data takes many forms Beyond files and tables to complex structures such as dashboards machine learning models videos or images the use of two disparate and incompatible data platforms where past needs have forced businesses to use data warehouses for bi and data Lakes for AI resulting in data duplication and unsynchronized governance models the rise of multi-cloud adoption where each cloud has a unique governance model that requires individual familiarity and fragmented tool usage for data governance on the lake house
introducing complexity in multiple integration points in the system leading to poor performance to address these challenges databricks offers the following Solutions Unity catalog as a unified governance solution for all data assets Delta sharing as an open solution to securely share live data to any Computing platform and a divided architecture into two planes control and data to simplify permissions avoid data duplication and reduce risk we'll start by exploring Unity catalog Unity catalog is a unified governance solution for all data assets modern lake house Systems Support fine-grained row column and view level Access Control via SQL query
auditing attribute-based Access Control Data versioning and data quality constraints and monitoring database admins should be familiar with the standard interfaces allowing existing Personnel to manage all the data in an organization in a uniform way in The databricks Lakehouse platform Unity catalog provides a common governance model based on ANSI SQL to Define and enforce fine-grained access control on all data and AI assets on any Cloud Unity catalog supplies one consistent model to discover access and share data enabling better native Performance Management and security across clouds because Unity catalog provides centralized governance for data and AI there
is a single source of Truth for all user identities and data Assets in The databricks Lakehouse platform the common metadata layer for cross workspace metadata is at the account level it provides a single access point with a common interface for collaboration from any workspace in the platform removing data team silos Unity catalog allows you to restrict access to certain rows and columns to users or groups authorized to query them and with attribute-based Access Control you can further simplify governance at scale by controlling access to multiple data items at one time for example personally identifiable information
in multiple given columns can be tagged as such and a single rule can restrict or provide access as needed Regulatory Compliance is putting pressure on businesses for full compliance and data access audits are critical to ensure these regulations are being met for this Unity catalog provides a highly detailed audit Trail logging who has performed what action against the data to break down data silos and democratize data across your organization for data-driven decisions Unity catalog has a user interface for data search and discovery allowing teams to quickly search for Relevant data assets for any use case
also the low latency metadata serving and auto tuning of tables enables Unity catalog to provide 38 times faster metadata processing compared to hive metastore all the Transformations and refinements of data from source to insights is encompassed in data lineage all of the interactions with the data including where it came from what other data sets it might have been combined with who created it and when what Transformations were performed and other events and attributes are included in a data sets data lineage Unity catalog provides automated data lineage charts down to table and column level giving that
end-to-end view of the data not limited to just one workload multiple data teams can quickly investigate errors in their data pipelines or end applications impact analysis can also be performed to identify dependencies of data changes on Downstream systems or teams and then notified of potential impacts to their work and with this power of data lineage there is an increased understanding of the data reducing tribal knowledge and to round it out Unity catalog integrates with existing tools to help you future proof your data and AI governance next we'll discuss data sharing with Delta sharing data sharing
is an important aspect of the digital economy that has developed with the Advent of big data but data sharing is difficult to manage existing data sharing Technologies come with several limitations traditional data sharing Technologies do not scale well and often serve files offloaded to a server Cloud object stores operate on an object level and are Cloud specific and Commercial data sharing offerings and vendor products often share tables instead of files scaling is expensive and they aren't open therefore don't permit data sharing to a different platform to address these challenges and limitations databricks developed Delta sharing
with contributions from the OSS community and donated it to the Linux Foundation it is an open source solution to share live data from your Lighthouse to any Computing platform securely recipients don't have to be on the same cloud or even use the databricks lake house platform and the data isn't simply replicated or moved additionally data providers still maintain management and governance of the data with the ability to track and audit usage some key benefits of Delta sharing include that it is an open cross-platform sharing tool easily allowing you to share existing data in Delta Lake
and Apache parquet formats without having to establish new ingestion processes to consume data since it provides native integration with power bi Tableau spark pandas and Java data is shared live without copying it with data being maintained on the provider's data Lake ensuring the data sets are reliable in real time and provide the most current information to the data recipient as mentioned earlier Delta sharing provides centralized Administration and governance to the data provider as the data is governed tracked and audited from a single location allowing usage to be monitored at the table partition and version level
with Delta sharing you can build and package data products through a central Marketplace for distribution to anywhere and it is safe and secure with privacy safe data clean rooms meaning collaboration between data providers and recipients is hosted in a secure environment while safeguarding data privacy Unity catalog natively supports Delta sharing making these two tools smart choices in your data and AI governance and security structure Delta sharing is a simple rest protocol that securely shares access to part of a cloud data set leveraging modern cloud storage systems it can reliably transfer large data sets finally let's
talk about the security structure of the data lake house platform a simple and unified approach to data security for the lake house is a critical requirement and the databricks lighthouse platform provides this by splitting the architecture into two separate planes the control plane and the data plane the control plane consists of the managed back-end services that databricks provides these live in databrick's own cloud account and are aligned with whatever cloud service the customer is using that is AWS Azure or gcp here databricks runs the workspace application and manages notebooks configuration and clusters the data plane
is where your data is processed unless you choose to use serverless compute the compute resources in the data plane run inside the business owner's own cloud account all the data stays where it is while some data such as notebooks configurations logs and user information are available in the control plane the information is encrypted at rest and communication to and from the control plan is encrypted in transit security of the data plane within your chosen cloud service provider is very important so the databricks Lakehouse platform has several security key points for the networking of the environment
if the business decides to host the data plane databix will configure the networking by default the serverless data plane networking infrastructure is managed by databricks in a databricks cloud service provider account and shared among customers with additional Network boundaries between workspaces and clusters for servers in the data plane databricks clusters are run using the latest hardened system images older less secure images or code cannot be chosen databricks code itself is peer reviewed by security trained developers and extensively reviewed with security in mind databricks clusters are typically short-lived often terminated after a job and do not
persist data after termination code is launched in an unprivileged container to maintain system stability this security design provides protection against persistent attackers and privilege escalation for databricks support cases databricks access to the environment is limited to cloud service provider apis for Automation and support access databricks has a custom-built system allowing our staff access to fix issues or handle support requests and it requires either a support ticket or an engineering ticket tied expressly to your workspace access is limited to a specific group of employees for limited periods of time and with security audit logs the initial
access event and the support team members actions are tracked for user identity and access databrick supports many ways to enable users to access their data the table ACLS feature uses traditional SQL based statements to manage access to data and enable fine-grained view-based access IM instance profiles enable AWS clusters to assume an IM role so users of that cluster automatically access allowed resources without explicit credentials external storage can be mounted and accessed using a securely stored access key and the secrets API separates credentials from code when accessing external resources as mentioned previously databricks provides encryption isolation
and auditing throughout the governance and security structure users can also be isolated at different levels such as the workspace level where each team or Department uses a different workspace the cluster level where cluster ACLS can restrict users who attach notebooks to a given cluster for high concurrency clusters process isolation JV and white listing and language limitations can be used for safe coexistence of users with different access levels and single user clusters if permitted allow users to create a private dedicated cluster and finally for compliance databrick supports these compliance standards on our multi-tenant platform SOC 2
type 2 ISO 27001 ISO 27017 and isos 27018 certain clouds also support databricks development options for fedramp high Trust HIPAA and PCI and databricks in the databricks platform are also gdpr and CCPA ready instant compute and serverless in this video you'll learn about the available compute resources for The dataworks Lakehouse platform what serverless compute is and the benefits of databricks serverless SQL The dataworks Lakehouse platform architecture is split into the control plane and the data plane the data plane is where data is processed by clusters of compute resources this architecture is known as the classic
data plane with the classic data plane compute resources are run in the business's cloud storage account and clusters perform distributed data analysis using queries in the databrick SQL workspace or notebooks in the data science and engineering or databricks machine learning environments however in using this structure businesses encountered challenges first creating clusters is a complicated task choosing the correct size instance type and configuration for the cluster can be overwhelming to the user provisioning the cluster next it takes several minutes for the environment to start after making the multitude of choices to configure and provision the cluster
and finally because these clusters are hosted within the businesses cloud account there are many additional considerations to make about managing the capacity and pool of resources available and this leads to users exhibiting some costly behaviors such as leaving clusters running for longer than necessary to avoid the startup times and over provisioning their resources to ensure the cluster can handle spikes and data processing needs leading to users paying for unneeded resources and having large amounts of admin overhead ending up with unproductive users to solve these problems for the business databricks has released the serverless compute option
or serverless data plane as of the release of this content serverless compute is only available for use with databrick SQL and is referred to at times as databrick serverless SQL serverless compute is a fully managed service that databricks provisions and manages the compute resources for a business in the databricks cloud account instead of the businesses the environment starts immediately scales up and down within seconds is completely managed by data bricks you have clusters available on demand and when finished the resources are released back to data breaks because of this the total cost of ownership decreases
on average between 20 to 40 percent admin overhead is eliminated and users see an increase in their productivity at the heart of the serverless compute is a fleet of database clusters that are always running unassigned to any customer waiting in a warm State ready to be assigned within seconds the pool of resources managed by databricks so the business doesn't need to worry about the offerings from the cloud service and databricks works with the cloud vendors to keep things patched and upgraded as needed when allocated to the business the serverless compute resource is elastic being able
to scale up or down as needed and has three layers of isolation the container hosting the runtime the virtual machine hosting the container and the virtual Network for the workspace and each part is isolated with no sharing or cross-network traffic allowed ensuring your work is secure when finished the VM is terminated and not reused but entirely deleted and a new unallocated VM is released back into the pool of waiting resources introduction to Lake House data management terminology in this video you'll learn about the definitions for common lake house terms such as metastore catalog schema table
View and function and how they are used to describe data management in the databricks lake house platform Delta Lake a key architectural component of the databricks lake house platform provides a data storage format built for the lake house and unity catalog the data governance solution for the databricks lighthouse platform allows administrators to manage and control access to data Unity catalog provides a common governance model to Define and enforce fine-grained access control on all data and AI assets on any Cloud Unity catalog supplies one consistent place for governing all workspaces to discover access and share data
enabling better native Performance Management and security across clouds let's look at some of the key elements of unity catalog that are important to understanding how data management works in databricks the metastore is the top level logical container in unity catalog it's a construct that represents the metadata metadata is the information about the data objects being managed by the metastore and the ACLS governing those lists compared to the hive metastore which is a local metastore linked to each databricks workspace Unity catalog metastors offer improved security and auditing capabilities as well as other useful features the next
thing in the data object hierarchy is the catalog a catalog is the topmost container for data objects in unity catalog a metastore can have as many catalogs as desired although only those with appropriate permissions can create them because catalogs constitute the topmost element in the addressable data hierarchy the catalog forms the first part of the three-level namespace that data analysts use to reference data objects in unity catalog this image illustrates how a three-level namespace compares to a traditional two-level namespace analysts familiar with the traditional data breaks or SQL for that matter should recognize the traditional
two-level namespace used to address tables Within schemas Unity catalog introduces a third level to provide improved data segregation capabilities complete SQL references in unity catalog use three levels a schema is part of traditional SQL and is unchanged by unity catalog it functions as a container for data assets like tables and Views and is the second part of the three level namespace referenced earlier catalogs can contain as many schemes as desired which in turn can contain as many data objects as desired at the bottom layer of the hierarchy are tables views and functions starting with tables
these are SQL relations consisting of an ordered list of columns though databricks doesn't change the overall concept of a table tables do have two key variations it's important to recognize that tables refined by two distinct elements first the metadata or the information about the table such as comments tags and the list of columns and Associated data types and then the data that populates the rows of the table the data originates from formatted data files stored in the businesses Cloud object storage there are two types of tables in this structure managed and external tables both tables
have metadata managed by the metastore in the control plane the difference lies in where the table data is stored with a manage table data files are stored in the meta stores manage storage location whereas within an external table data files are stored in an external storage location from an access control point of view managing both types of tables is identical views are stored queries executed when you query The View views perform arbitrary SQL Transformations on tables and other views and are read only they do not have the ability to modify the underlying data the final
element in the data object hierarchy are user-defined functions user-defined functions enable you to encapsulate custom functionality into a function that can be evoked within queries storage credentials are created by admins and are used to authenticate with cloud storage containers either external storage user supplied storage or the managed storage location for the metastore external locations are used to provide Access Control at the file level shares and recipients relate to Delta sharing an open protocol developed by databricks for secure low overhead data sharing across organizations it's intrinsically built into Unity catalog and is used to explicitly declare
shares read-only logical collections of tables these can be shared with one or more recipients inside or outside the organization shares can be used for two main purposes to secure share data outside the organization in a performant way or to provide linkage between metastors and different parts of the world the metastore is best described as a logical construct for organizing your data and its Associated metadata rather than a physical container itself the metastore essentially functions as a reference for a collection of metadata and a link to the cloud storage container the metadata information about the data
objects and the ACLS for those objects are stored in the control plane and data related to objects maintained by the metastore is stored in a cloud storage container












![Hands-On Power BI Tutorial 📊Beginner to Pro [Full Course] ⚡](https://img.youtube.com/vi/5X5LWcLtkzg/maxresdefault.jpg)



![Business Analyst Full Course [2024] | Business Analyst Tutorial For Beginners | Edureka](https://img.youtube.com/vi/1QKIvt05LmA/maxresdefault.jpg)
