transformers are taking the natural language processing world by storm these incredible models are breaking multiple NLP records and pushing the state-of-the-art they are used in many applications like machine language translation conversational chat BOTS and even a power better search engines transformers are the rage and deep learning nowadays but how do they work why are they outperformed a previous king of sequence problems like recurrent neural networks gr use and LS tiens you've probably heard of different famous transformer models like Burt CBT and GB t2 in this video we'll focus on the one paper that started it
all attention is all you need to understand transformers we first must understand the attention mechanism to get an intuitive understanding of the attention mechanism let's start with a fun text generation model that's capable of writing its own sci-fi novel we'll need to prime in a model with an arbitrary input and a model will generate the rest okay let's make the story interesting as aliens entered our planet and began to colonize earth a certain group of extraterrestrials begin to manipulate our society through their influence of a certain number of the elite of the country to keep
an iron grip over the populace by the way I then just make this up this was actually generated by open AI is GPT to transformer model shout out to hugging face for an awesome interface to play with I'll provide a link in description okay so the model is a little dark but what's interesting is how it works as a model generate tax word by word it has the ability to reference or tend to words that is relevant to the generated word how the model knows which were to attend to is all learned while training with
backpropagation our intends are also capable of looking at previous inputs too but the power of the attention mechanism is that it doesn't suffer from short-term memory rnns have a shorter window to reference from so when a story gets longer rnns can't access word generated earlier in the sequence this is still true for gr use and L STM's although they do have a bigger capacity to achieve longer term memory therefore having a longer window to reference from the attention mechanism in theory and given enough compute resources have an infinite window to reference from therefore being capable
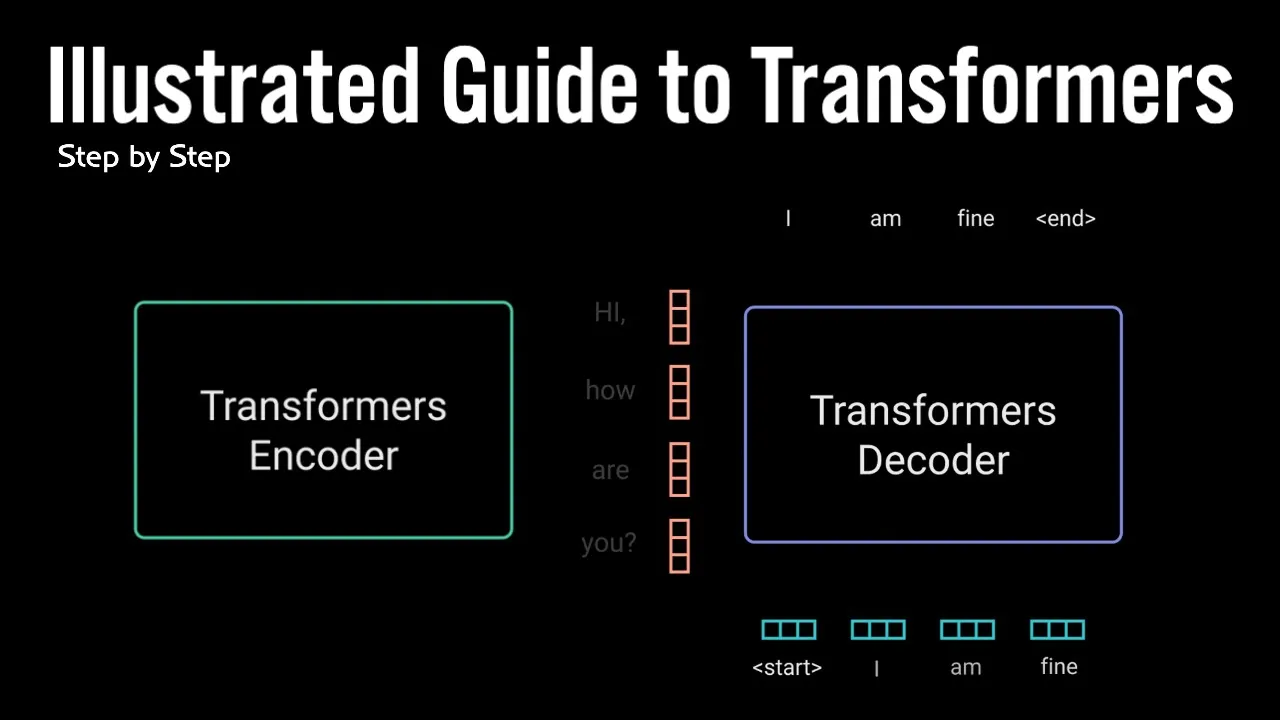
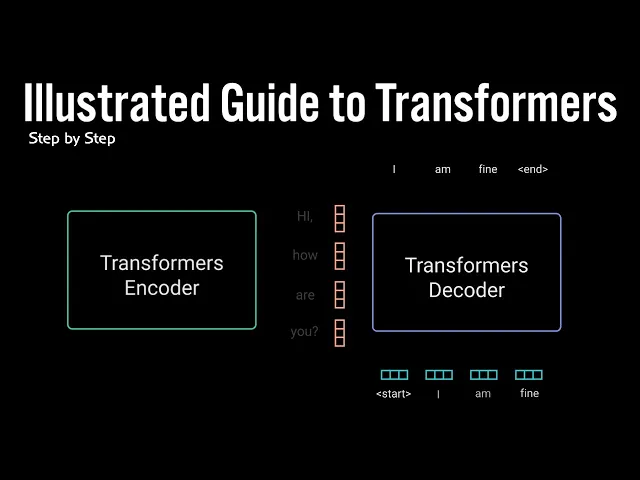
of using the entire context of the story while generating the text this power was demonstrated in the paper attention is all you need when the author's introduce a new novel neural network called the Transformers which is an attention based encoder decoder type architecture on a high level the encoder Maps an input sequence into an abstract continuous representation that holds all the learned information of that input to decoder then takes our continuous representation and step by step generates a single output while also being fed to previous output let's walk through an example the attention is all
you need paper applied to transformer model on a neuro machine translation problem our demonstration of the transformer model would be a conversational chat bot the example with taking an input tax hi how are you and generate the response I am fine let's break down the mechanics of the network step by step the first step is feeding our input into a word embedded layer a word embedding layer can be thought of as a lookup table to grab a learn factor of representation of each word neural networks learned through numbers so each word maps to a vector
with continuous values to represent that word next step is to inject positional information into the embeddings because a transformer encoder has no recurrence like recurrent known networks we must add information about the positions into the input embeddings this is done using positional encoding the authors came up with a clever trick using sine and cosine functions we won't go into the mathematical details of the positional codings in this video but here are the basics for every odd time step create a vector using the cosine function for every even time step create a vector using the sine
function then add those vectors to their corresponding embedding vector this successfully gives the network information on two positions of each vector the sine and cosine functions were chosen in tandem because they have linear properties the model can easily learn to attend to now we have the encoder layer the encoder layers job is to map all input sequence into an abstract continuous representation that holds the learned information for that entire sequence it contains two sub modules multi-headed attention followed by a fully connected network there are also residual connections around each of the two sub modules followed
by a layer normalization to break this down let's look at the multi headed attention module multi-headed attention Indian code applies a specific attention mechanism called self attention self attention allows a model to associate each individual word in the input to other words in the input so in our example it's possible that our model can learn to associate the word you with how M are it's also possible that the model learns that word structured in this pattern are typically a question so respond appropriately to achieve self attention we feed the input into three distinct fully connected
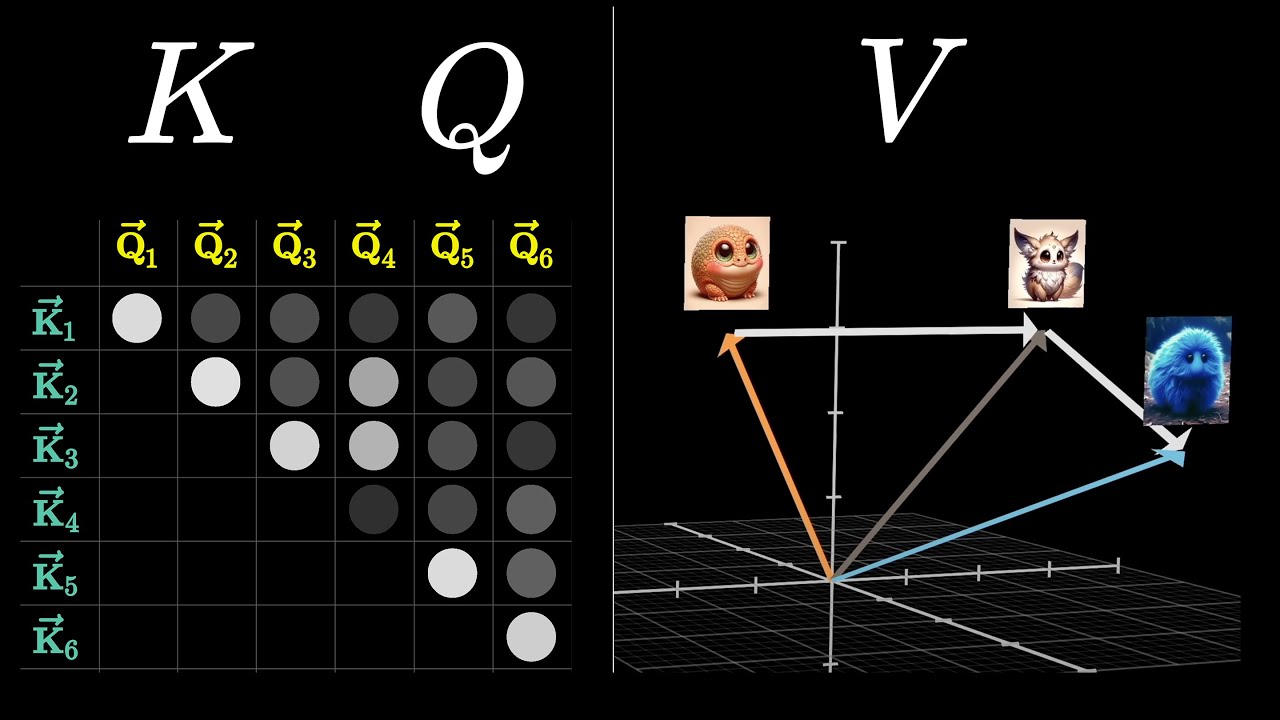
layers to create the query key and value vectors what are these vectors exactly I found a good explanation on stock-exchange stating the query key and value concept comes from the retrieval system for example when you type a query to search for some video on YouTube the search engine will map your query against a set of keys for example video title description etc associated with candidate videos in the database then present you with the best match video let's see how this relates to self attention the queries and keys undergoes a dot product matrix multiplication to produce
a score matrix the score matrix determines how much focus should a word be put on other words so each word will have a score to correspond to other words in the time step the higher score the more the focus this is how queries are mapped to keys then the scores get scaled down by getting divided by the square root of the dimension of the queries and the keys this is to allow for more stable gradients as multiplying values can have exploding effects next you take the softmax the scaled score to get the attention weights which
gives you probability values between 0 & 1 by doing the softmax the higher scores get heightened and the lower scores are depressed this allows the model to be more confident on which words to attend to then you take the attention weights and multiply it by your value vector to get an output vector the higher softmax scores will keep the value of the words the model learn is more important the lower scores will drown out their irrelevant words you feed the output vector into a linear layer to process to make this a multi-headed attention computation you
need to split the query key in value into adding vectors before applying self attention to split vectors that goes through the same self attention process individually each self attention process is called a head each head produces an output vector that gets concatenated into a single vector before go through in a final linear layer in theory each head would learn something different therefore giving the encounter model more representation power okay so that's multi-headed attention to sum it up multi-headed attention is a module in a transformer network that you to the attention waits for the input and
produces an output vector with encoded information on how each word should attend to all other words in a sequence next step the multi-headed attention output vector is added to the original input this is called a residual connection the output of the residual connection goes through a layer normalization the normalized residual output gets fed into a point-wise feed-forward network for further processing the point-wise feed-forward network are a couple of linear layers with a relict evasion in between the output of that is again added to the input of the point-wise feed-forward network and further normalized the residual
connections helps the network train by allowing gradients to flow through the networks directly the layer normalizations are used to stabilize the network which results in sustained producing the training time necessary and a point-wise feed-forward layer are used to further process the attention output potentially giving it a richer representation and that wraps up the encoded layer all these operations is for the purpose of encoding the input to a continuous representation with attention information this will help the decoder focus on the appropriate words in the input during the decoding process you can stack the encoder and times
to further encode the information where each layer has the opportunity to learn different attention representations therefore potentially boosting the predictive power of the transformer network now we move on to the decoder the decoders job is to generate text sequences the decoder has similar sub layers as the encoder it has two multi-headed attention layers a point-wise feed-forward layer with residual connections and layer normalization after each sub layer these sub layers behave similarly to layers in the encoder but each multi-headed attention layer has a different job it's capped off with a linear layer that acts like a
classifier and a soft Max to get the word probabilities the decoder is auto regressive it takes in the list of previous outputs as inputs as well as the encoder outputs that contains the attention information from the input the decoder stops decoding when it generates an end token as an output let's walk through the decoding steps the input goes through an embedding layer in a position on coding layer to get positional embeddings the positional embeddings gets fed into the first multi-headed attention layer which computes the attention score for the decoders input this multi-headed attention layer operates
slightly different since the decoders autoregressive and generates the sequence word-by-word you need to prevent it from condition into future tokens for example when computing attention scores on the word am you should not have access to the word fine because our word is a future word that was generated after the word am should only have access to itself and the words before this is true for all other words where they can only attend to previous words we need a method to prevent computing attention scores for future words this method is called masking to prevent the decoder
from looking at future tokens you apply a look-ahead mask the mask is added before calculating the softmax and after scaling the scores let's take a look at how this works the mask is a matrix that's the same size as the attention scores filled with values of materials and negative infinity x' when you add the mask to the scale attention scores you get a matrix of scores with the top right triangle filled with negative infinity x' the reason for this is once you take the softmax of the mask scores the negative infinity is get zeroed out
leaving a zero attention score for future tokens as you can see the attention scores for M have values for itself and all other words before it but zero for the word fine this essentially tells the model to put no focus on those words this masking is the only difference on how the attention scores are calculated in the first multi-headed attention layer this layers still have multiple heads that the masks are being applied to before getting concatenated and fed through a linear layer for further processing the output of the first multi-headed attention is a mask output
vector with information on how the model should attend on the decoders inputs now on to the second multi-headed attention layer for this layer the encoders output are the queries in the keys in the first multi-headed attention layer outputs are the values this process matches the encoders input to the decoders input allowing the decoder to decide which encoder input is relevant to put focus on the output of the second multi-headed attention goes through a point wise feed-forward layer for further processing the output of the final point wise feed-forward layer goes through a final linear layer that
access a classifier the classifier is as biggest number of classes you have for example if you have 10,000 classes for 10,000 words the output of that classifier will be of size 10,000 the output of the classifier again gets fed into a soft max layer the soft max layer produced probability scores between 0 and 1 for each class we take the index of the highest probability score and that equals our predicted word the decoder didn't taste the output and adds it to the list of decoder inputs and continue decoding again until end token is predicted for
our case the highest probability prediction is the final class which is assigned to the end token this is how the decoder generates the output the decoder can be stacked n layers high each layer taking in inputs from the encoder and the layers before it by stacking layers the model can learn to extract and focus on different combinations of attention from its attention heads potentially boosting its predictive power and that's it that's the mechanics of the transformers transformers leverage the power of the attention mechanism to make better predictions recur known networks trying to achieve similar things
but because they suffer from short term memory transformers are usually better especially if you want to encode or generate longer sequences because of the transformer architecture the natural language processing industry can now achieve unprecedented results if you found this helpful hit that like and subscribe button also let me know in comments what you'd like to see next and until next time thanks for watching




![The moment we stopped understanding AI [AlexNet]](https://img.youtube.com/vi/UZDiGooFs54/maxresdefault.jpg)