so what i need is actually a way to estimate the test error for each of these models m0 m1 m2 all the way through mp so that i can choose among them and basically in order to estimate the test error i have two approaches and one approach is that i can indirectly estimate the test error by somehow computing the training error and then adjusting it and the idea behind this adjustment is that if i can somehow adjust the training error to account for the bias due to overfitting then that can give me an estimate of
of test error that's again based on the training error but somehow looks more like a test error and the alternative approach is that i can try to directly estimate the test error and i can do that using some of the approaches that are in chapter five of this book um and and those involve either cross validation or a validation set approach and so so that's a really direct approach to estimating the test error where i fit models on part of the data and then i evaluate them on a holdout set so we're now going to
talk about both of these approaches so cp aic bic and adjusted r squared all adjust the training error in order to give us an estimate of the test error and and they all can be used to select among models with different numbers of variables so we're now going to look at a figure showing us cp bic and adjusted r squared for the best model of each size that we get using best subset selection on the credit data so we're first going to look at this figure and then we'll talk about how these quantities are defined
so again this is on the credit data example and on the x-axis here we have the number of predictors in each of these figures and on the y-axis we have cp bic which stands for bayesian information criterion and adjusted r squared and again we'll define all three of these quantities in a minute but the idea is roughly speaking we want these quantities to be small so we prefer a model in which cp bic and are as small as possible and actually i misspoke we want adjusted r squared to be as large as possible so if
i look at the shape of this curve i can see that um cp is minimized when we look at the model with six predictors bic is smallest when we look at the model with four predictors and adjusted r squared is smallest when we look at a model with six predictors again so that suggests that we should use somewhere between four and six predictors and actually if we look at these figures a little more closely we can see that basically these curves are more or less flat after we get to around three or four predictors and
so on the base of these these figures i would say you know i really don't think we need more than three or max four predictors to do a good prediction on this credit data so you know and i've scribbled all over the slide oops on this picture it's hard to see here but actually the curve is going up right as we go to the right despite the fact it's it's flat that's right yes i like the rss exactly it's a little hard to see yeah but this is slightly increasing it's smallest with four predictors and
then it goes up a little bit but you know i don't really think that there's compelling evidence here that that four is really better than three or better than five so if it were me you know i think simpler is always better so i'd probably choose a model with you know three predictors maximum four predictors yeah i agree great so now we're going to talk about on malocp and once again this is an adjustment to the training r squared the the training rss that gives us an estimate for the test rss and it's defined in
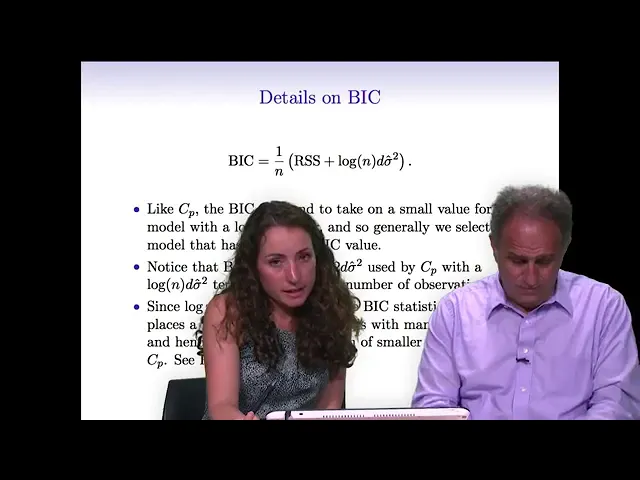
this formula so let's say we're looking at a model with d predictors um so then we're going to calculate the rss for that model with g predictors and we're going to add to the rss 2 times d where again d is the number of predictors times sigma hat squared where sigma hat squared is an estimate of the variance associated with each error epsilon in the linear model and so the idea is we can calculate cp for those models m0 m1 m2 through mp that we were looking at a few minutes ago and we can just
choose the model with the smallest cp so like if we're looking at the model m3 then that model contains three predictors and an intercept so that model has d equals four and we can calculate the rss for the model m3 and we just calculate sigma hat squared there's a formula for that it gives us a cp and out of all these models m0 to mp we're just going to choose the one for which the cp is smallest because that's the one that we believe is going to have the smallest test set rss now just to
clarify a bit about the sigma hat squared first of all if if p is bigger than n we're going to have a problem right because what typically sigma hat squared the same values the same estimates used for all models being compared so you usually do is you fit the full model all p predictors and you take the mean square residual for that model to give you sigma hat squared um so that's the way you do it of course that's going to create a problem p is bigger than n because that full model was not defined
and the error will be zero so already we see that cp is restricted to cases where you've got n bigger than p that's right and even if p is close to n you're going to have a problem because you're asking the sigma squared might be far too low so so that's malo's cp and then another very closely related idea is called the aic criterion so the the aic stands for a keiki information criterion akaiki was the name of the guy who came up with this idea and the way that this is defined is negative 2
log l plus 2 times d where d is once again the number of predictors in the model that i'm looking at so for m3 d equals 4 and now capital l here is the maximized value of the likelihood function for the estimated model so this looks a little bit complicated and in fact it's written in this very general way because aic is a quantity that we can calculate for many different model types not just linear models but also logistic regression and so on but it turns out that in the case of a linear model negative
2 log l is just equal to rss over sigma hat squared so if you look at that and you plug in rss over sigma hat squared for negative 2 log l then what you realize is that aic and mallow cp are actually proportional to each other and since we're just going to choose the model for which cp is smallest that's equivalent to choosing the model for which aic is smallest so so aic and cp are actually really the same thing for linear models but for other types of models these things are not the same and
aic is a good approach so we've talked about cp and aic and another very related idea here is the bic where b stands for bayesian so this is the bayesian information criterion and it's like the aic and the this malocp but it comes from sort of a bayesian argument and once again we've got a very similar formula we calculate the residual sum of squares and then we add an adjustment term which is the log of the number of observations times d which is once again the number of predictors in the model i'm looking at so
like m3 since it has three predictors and intercept m three has d equals four and once again sigma hat squared is an estimate of the error variance which may or may not be available depending on whether n is greater than p or less than p and so once again with bic we're estimating the test set rss or rather the average test at rss across the observations and so we want it to be as small as possible so we're going to choose the model with the smallest bic so what's the difference between bic and aic well
remember aic it had it would look just like this but in aic this term was actually 2d sigma hat squared right so the only difference between aic and bic is the choice of log n versus two bic has this log n here and um and aic has a 2. and so in general if n is greater than 7 then log n is greater than 2. and so what that means is that if you have more than seven observations in your data bic is going to put more of a penalty on a large model and in
other words bic is going to tend to choose smaller models than aic is so so bic is going to give you the selection of models that have fewer variables than either cp or or aic so we see that these three ideas bic cp and aic are really almost identical they just have slightly different formulas they all we want to minimize them and they all require an estimate for sigma hat squared which again is not available necessarily if it's only going to be available if n is greater than p so the last of these approaches that
i'm going to talk about that sort of indirectly adjusts the training error to get an estimate of the test error is the adjusted r squared and so we saw in chapter 3 the idea of the r squared and remember r squared was defined just as a little refresher r squared is defined as 1 minus the residual sum squared divided by the total sum of squares where in case we need a reminder the total sum of squares is just the sum of y i minus y bar squared so y bar is the average response y i
is the ith response and we're just taking the sum of those squared values and so this was the r squared and as we've as we know a big r squared indicates a model that really fits the data well but unfortunately you can't compare models by just taking the you can compare models of different sizes by just taking the one with the biggest r squared because you can't compare the r squared of a model with three variables to the r squared of a model with eight variables for instance so the adjusted r squared tries to fix
this and the way that it does that is that it makes you pay a price for having a large model so the idea is adjusted r squared adjusts the r squared so that the values that you get are comparable even if the numbers of predictors are different so the way that it does this is by adding a denominator to the to rss and to tss in this ratio so in so instead of just taking 1 minus rss over tss we take 1 minus rss over n minus d minus 1 divided by tss over n minus
1 where again d is the number of variables in the model that we're considering and so basically the idea here is that when d is large this denominator is really large and so you're dividing the rss by a really big number and you're going to end up with a smaller r squared so so what's happening is that we're going to pay a price for having a large model in the adjusted r squared unlike the classical r squared which where we know pay no price for having a large model with a lot of features so the
adjusted r squared we want it to be large if it's large then that indicates a model that really fits the data well and again the idea is that adjusted r squared is something that we can actually compare in a meaningful way regardless of the number of predictors in the model some of this notice looks like you can it doesn't it doesn't require an estimate of sigma squared that's good and you can also apply it when p is bigger than n yeah that's right so that's a really nice advantage of of rss as rob said we
don't need to estimate sigma squared which can be a problem and in principle we can apply it when p is larger than n so um we want a large value of adjusted r squared and and so the adjusted r squared in practice people really like it it tends to work really well so some statisticians don't like it as much as um cp aic and bic and the reason is because it sort of works well empirically but some statisticians feel that it doesn't kind of have the theoretical backing of some other approaches what do you think
of that rob that's that's true there is a bias in our field towards things which have more theory behind them um and i guess is this a example of that but one nice thing about adjusted r squared is like if you're working with um someone who's not a statistician like scientists who aren't statisticians are really familiar with r squared and so from when to understand r squared adjusting r squared is just a really small one off and it's kind of easier to explain to someone in a certain sense than a ic cp or bic and
so that's one really nice thing about it but adjusted r squared you can't really generalize to other types of models so if you have like logistic regression you can't do this so you'll see in the next section we'll talk about cross validation which is uh our our favorite method which you can generalize and one major advantage is you don't need to know d so the the d in in this method in in adjusted r squared and cp and aic is the number of parameters but in some methods like ridge regression and the lasso which we'll
also talk about again in a few minutes the value of d is not even known so we can't apply any of these methods but cross-validation can still be applied yeah that's true so like in this whole discussion i've been talking about least squares models and then i've been occasionally mentioning logistic regression but i could have some totally crazy model that i come up with that like is like something that nobody's ever seen before and it would be totally hopeless to to apply an aic type of idea to it or an adjusted r squared type of
idea but i can always perform cross validation or the validation set approach no matter how wacky my model is and that's actually a really nice thing about those two approaches