hey everyone welcome back to another video I know it's been a few weeks now since I've posted my last video here on YouTube I just wanted to say I've been taking a bit of a break from YouTube but we are back with more content related to llms and AI in general and what better way to start off the year than what deep seek released today which is their deep seek R1 model and they're claiming that they have performance on par with open AI o1 there is a technical report and it's also including open-source models so
distill models which are available for research and Commercial purposes in other words this is such an awesome release and a good start of the year for the community because we have now a very powerful model that we can use to do research on and can build on top of as you know R1 is deep seek thinking or reasoning model as they are referred to today and you can actually access it here so what I'm going to do in this video is is just do a brief summary of the paper and I want to do like
a tldr for it I'm not going to spend too much time on the details but I also want to try out a few examples some things that actually tested on the previous preview model that they released so let's go to the paper and check out some of the important details and then we're also going to take it for a spin because we can access it right here today I believe everyone should be able to access this so that's another thing that I really like about deep seek and they even have an app that's available now
good work de seek congratulations to the team and let's get started with the report and jump into some examples from my point of view I think this is such a breakthrough because it is one of the first open-source models that competes directly with the likes of the openi 01 model and we can see that by the performance itself so you can see on code forces some of these different benchmarks with which these reasoning models are using to Showcase your strength and performance how similar it is in terms of cap ility and I would say it's
a very competitive model just based on these results now these are just Benchmark results I think it's important to also test the models so the basic idea of this particular deeps car1 model is that they want to train a system or propose a training strategy which incentivizes as you can see in the title here the reasoning capabilities in the large language model itself and reinforcement learning is going to be the key and main theme throughout the paper and I think the method itself is very interesting because it's not really clear what exactly leads to very
capable reasoning models I think it's still very early days and there has been a lot of experimentation with ideas such as Monte carot research some don't use that in this paper that's not used and it's a very interesting approach to enhance the reasoning capabilities of these models so let's take a look at some of the details here I will look however at some of the important points so for instance I want to summarize here the contributions now they have applied reinforcement learning to a base model so that's the one of the first steps that they're
using here okay so we went from a base model to applying reinforcement learning and this again says without relying on supervised Fain tuning and they're mentioning here that this approach allows them model to explore Chain of Thought for solving complex problems basically it could lead to a very coherent U model that can do long reasoning reflection these Chain of Thought steps to solve very complex problems they demonstrate capabilities such as self-verification reflection and generating long chain of thoughts as I was saying and it says notably it is the first open research to validate that reasoning
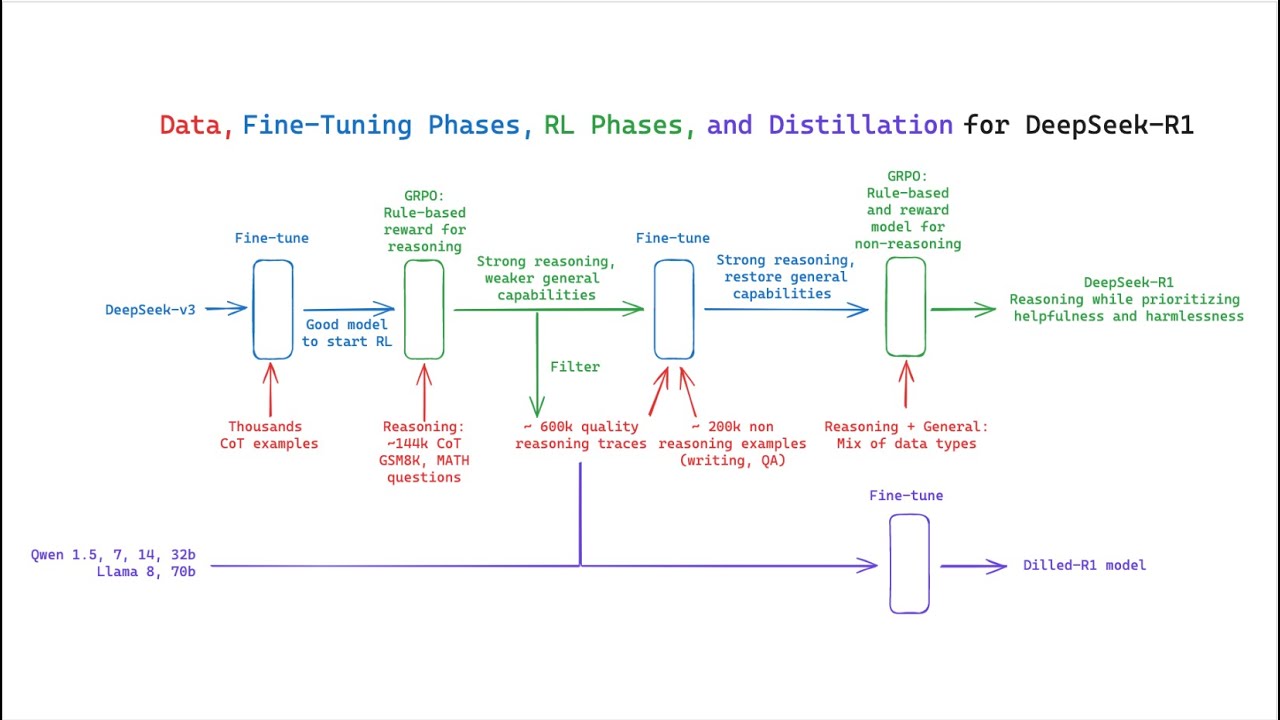
capabilities of llms can be incentivized purely true reinforcement learning I think this is one of the interesting findings from this paper and without the need for sft most of these approaches are using sfd as a you know first step and this one jumps right from Bas M directly to RL and then they introduce a pipeline which would include multiple steps to develop deep C car1 so keep in mind there's two versions here so we have the Deep seek r10 which is from Bas to RL and then there is this deep seek R1 which will involve
different steps and I'm going to go through the different steps so they say INR the pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences so how to make a very capable model in terms of reasoning because that's really what most of these llms or most of the advanced llms are doing today along with making sure that they have this alignment right we don't sacrifice the alignment because alignment is really important for application or putting these things into production so they have as well as two sftd stages that serve
as a seed for the model's reasoning and non- reasoning capabilities right it's not just about reasoning but also those non- reasoning capabilities so we're talking about a complex and very general system that can do all of these different things and there's no sacrifice of performance in terms of reasoning and some of the other important capabilities of the llm so that's roughly speaking the P plane here and they also have this distillation process which they use to distill some models I think the models that they're using are Quinn and Lama I believe so we're going to
see some of the results later but this is just a summary of it basically the approach is going to be like this so the first step as I was saying is this this deep seek r10 right where you go from a base model applied reinforcement learning so that's being applied to the base model no supervised data and that's the first step they use G RPO as their RL algorithm so you can see all the details there and then they have some kind of template that they use okay you can take a look at the template
and then they have like the reward modeling and they adopt a rulebase reward system that mainly consists of these two type of rewards so there's an accuracy reward and then format reward which is really important here to have this kind of consistent output of these tokens for the thinking part of the model so these are the results or a summary of it you can see that this is the model here that we're talking about and then we have the 01 mini and 01012 snapshot of that and you can see that this model is quite capable
I mean it does come close in terms of performance and sometimes it even outperforms the open1 model on all of these important benchmarks so like code forces and life code gpq di I noticed that this is one of the benchmarks that the open a folks really focus a lot on and that's because this is a very complex Benchmark and so you can see the results there this DC car 10 Z Model is pretty capable already um and this is the beginning so this is just showing that you can build something without all the fancy stuff
like MCTS very simple reward models and so on and they also show here the accuracy of IM right on deep seek r10 during training so for each question with sample 16 responses and calculate the yourl average accuracy to ensure a stable evaluation so these are some of the performances here this is talking about this particular model and they have this as a demonstration of how RL can drive a model to improve proove its reasoning capabilities in an autonomous way so I think there is a lot to dig into with this specific finding and I think
we're going to see a lot more of this I think this can become a really interesting approach to optimizing these models for reasoning and they even show this chart here which I found also super interesting so this is about the average response length of deep seek r10 on the training set during the RL process so deeps r10 naturally learns to solve reason task with more thinking in time and we have seen this before right the opening eye models and some of the results that they have shown also show something quite similar right the more the
model spends on thinking the better it gets at some of these reasoning tasks so the AA moment I think was interesting the share that a particularly intriguing phenomenon observed during the training of the C r10 is the occurrence of an AA moment this moment as Illustrated in table tree occurs in an intermediate version of the model during this phase this model learns to ocate more thinking time to a problem by re-evaluating its initial approach this behavior is not only a testament to the mes growing reasoning abilities which is what they wanted to show with these
different charts but also captivating example of how reinforcement learning can lead to unexpected unsophisticated outcomes now if you're a researcher in the space this is a very exciting result right because for a long time we know that RL has the capability right with alphago and all these different systems that are based on RL we know that it has the potential but we really haven't seen a purely RL approach to llms and I think we are starting to see that here in this paper in particular so there are more details here if you want to read
it I'm not going to go through all of that but I think one of the issues with deep c car1 z which they report here is this poor readability while it can output coherent long reasoning reflection coot steps and so on it does suffer from this poor readability and language mixing so they want to address that and the way they address that is via this multi-training procedure so the first part is going to be reinforcement learning with cold start okay so that's basically going into like from RL to sft so the Deep seek R1 is
not something we're going to trow away it's something we're actually going to build on top of and that's kind of the idea here so you can see here it says we collect thousands of Co start data to find un deeps V3 base as a starting point forl and compared to deeps r10 the advantages of call start data include the readability part and also some other things that I mentioned here and then they go from the supervised fine tuning to RL so this is the reasoning oriented reinforcement learning so again it's applying very similar or the
same RL training process as they applied to deeps car10 so they're just reusing that and the idea is that they want to do that to enhance the model reasoning capabilities in particular on reasoning intensive tasks such as coding mathematics science and logic reason in so that's the idea here or at least the the high level idea and again they mentioned something about language mixing which they want to kind of tackle and they show that they introduce a language consistency reward during RL training and that's how they can improve on those different issues that they saw
in the initial um model that they train right the Deep seek r10 and together with that what they do is they now introduce the supervised fine tuning right with rejection sampling H this is a very common step that's being applied you know to some of these models so nothing surprising here what's interesting is the different steps right like they apply these different wrongs of training which helps create a more stable system or train a more stable system and also obviously incorporating all of these Advanced reasoning capabilities as well so this is just tax about reasoning
data there are 600k reasoning related train example and this is RL for all scenarios is this again it's going to go from sft to RL basically applying reinforcement learning again and this one the idea is that they want to improve the mod healthfulness and harmlessness while keeping those reasoning capabilities right so there's a lot of unstability that can happen in these different phases of training this system so it's important that these models are also very aligned as not just having good reasoning capabilities but have good alignment and part of the reason why that's important is
because I saw this when I did my early test on the preview of this model I noticed that the model is really good at the thinking steps but it sometimes like didn't understand the intent of my prompt right that could be a really big issue there um and so you cannot really sacrifice the human preferences because that is what makes these models you know usable and at the same time you want to keep this reasoning capability so it's kind of a balance between the two and I think this is early days with this research I
think there might be other more effective ways to do this and then there's a lot of experiments here I'm just going to jump here to the main results these are the main results you can see deep SE R1 here very good model you can see how it Compares with the open1 models right here and very capable model overall there is also results on the distal mle I'm not going to summarize this here but you can check that out on your own we're going to jump into some examples about the mle but I highly encourage you
to look at the paper if you have any questions let me know in the comments if I missed anything important here as I said I just finished reading and overviewing this paper at least one round I need to go back again and look at the paper there's a lot of really cool details in the paper itself that I may have missed in this video just let me know if you have anything that comes up I'm happy to provide more context or details I want to actually show you here first before I start with the examples
I wanted to highlight first that they have an app that you can download so if you want to use this in your mobile you can do that and I'm going to go first this burn candles because this one it was really about understanding first what the problem is and I think this is the alignment that's missing from these models so I think they saw a lot of examples of people trying out different prompts and they noticed that oh while it is doing really good in the thinking steps it kind of misunderstood the intention of the
task itself and that's really bad you need to have good reasoning capabilities of course but you also or problem solving capabilities but you also have to have a way to train the model to be really good at understanding the task itself so that it's pretty useful in the real world let's take a look at how it's going to perform on that I haven't done this one I have tried other task here and I really want to show you because there are some interesting and exciting results and this one obviously when I did this the first
time with the preview model of their thinking model this one answered candle 4 which is the wrong one it should be this one so let's see if that was improved so go to chat again here I want to enable deep think I don't really need search I'm just going to do deep think I'm going to just prompted like that okay so it's going to do thinking and then this is the thinking steps those are the thinking steps I think I'm not sure if it's this one or the other models but I noticed that there was
no distinction between the thinking steps and the actual response but now I can see that distinction and you can see here that it actually got it right so you can see this one it understood the task it says the first candle blown out is the one that burned the least which is correct hence remaining the longest among the options candle tree has the most equals indicating it was extinguished earliest I mean this while a very simple task at first glance most of the allel struggle with this and it's really good even the previous model as
I showed you suffered from issues of understanding the actual task but this one is clearly re working really well so that's already a huge Improvement on this particular matte puzzle now let's look at U this crossword puzzle so I actually gave it this crossword puzzle which I think is probably one of the tasks that I usually test these models on that none of the models can actually solve this includes the o1 models so it'll be interesting to try this on O3 when that does come out so I'm excited about that one too but this is
one of the tasks the crossbo puzzle that really none of these models can solve and that's because for this task in particular it's not just about reasoning it's about understanding it's about understanding references having access to a lot of complex knowledge and very deep knowledge in fact and none of these models can get this correct and also I saw that this particular model wasn't able to solve this one as well like it got some of them correct but most of them it got wrong so no surprises here so let's look at one of the interesting
tasks that I tried before with the previous iteration of this thinking model uh that wasn't correct and I actually gave it the task again and I told it let me see here write a bash script that takes a matrix presented as a string with format this is the format and prints the transpose in the same format and okay did a lot of thinking I mean you can see how long this thinking is and then it generated a script so what I did is I took this script and then I copy pasted it into my script
locally and I test it right obviously I have to test it to see if it's correct now the previous thinking model that they previewed before obviously did not get this correct and you can watch my previous video on that here on my YouTube channel but I wanted to check out if it actually got it correct this time so I tested it here is the actual script you can see it here I just copy pasted it right here and then down here I can actually run it so I actually run it already so it's this one
right here so this one is the Deep transpose. sh that's the script where I pasted the code and then I give I'm giving it this as an input and you can see that here I run it already I'm just going to run it right you can see here that it gave me the correct response so that's actually the correct output and in a lot of cases it was giving me the wrong output the wrong Matrix in or maybe the wrong Dimension and so on and sometimes it didn't even work so I've been testing this particular
task and then I noticed that there's definitely an enhancement in terms of the code that was being generated by this particular thinking model so it's great to see the results on that and I do believe I have this transpose Matrix that sh which is the one from openi and I just want to show you here that the code is a little bit different so I'm just going to run it again or run this one just to show you that the opening IM models actually got this correct and I'm talking about the 01 model oh sorry
I did not provide the input I'm just going to copy this so yeah you can see that this one actually got it correct okay so that's kind of the thing that I want to show about code so that's the example I'm very impressed that finally this deeps model got it correct so this is definitely an improvement all right so going back here I have a few more tests that I wanted to Showcase now actually th one of the prompts originally posted in the blog post about reasoning llms from openi where is this this particular Tas
which I found interesting which is it needs to decode something here and basically it goes throughout the entire process you can see how long that is and then it says the decoding message is there are three hours in Strawberry I thought was when went open I released that and you can see that this model also has that capability which is really interesting there is this test that I did too and this one I think I tested this one on their on the Quin model so this one is about please add a pair of parentheses to
the incorrect equation and when I look at the results this seems yeah this is the correct result right here so that's really good to see all right and those are the examples if you want to test out more examples um I do have some videos where I tested more things like mad problems and things like that I will be testing these models more and more all right that'll be it for this video thank you for watching hopefully it was useful let me know if you have any questions and thanks again for supporting the channel I'm
very excited to continue doing YouTube videos let me know what are the interesting topics I will be posting a lot more tutorials as well this year but I'm happy to be back on YouTube and and wishing everyone a good start of the year and whatever you're doing whatever you're working on do leave a comment below as I said if there's anything that you found interesting as well anything that you want to share in addition to what I shared and I'll see you all in the next one