Всем привет в этом видео Я разберу задачу е из текущего алгоритмического отброшен контеста на стажировку в Яндекс Но прежде чем начать предлагаю подписаться на мой Telegram канал там я разбираю задачки со вступительных контентов других компаний НВ Озон контур и так далее выкладываю решение задач разборы наиболее важных тем на собеседований и многое другое интересное также подписывайтесь на этот YouTube канал ставьте лайки делитесь своим мнением в комментариях ну а мы начинаем Ну и переходим непосредственно к задаче здесь перед вами представлен кусок собственно полные условия есть в telam канале можете туда пойти посмотреть знакомиться с условием также здесь
я не буду его полностью читать можете поставить видео на паузу самостоятельно его изучить единственное Я немножко поясню это условие чтобы Лучше понимать механику задачи и Лучше понимать То что от нас хотят собственно авторы Значит у нас есть соответственно Финикийский язык есть буква латинского алфавита и у нас собственно есть табличка по которому букв латинского алфавита переводится в собственно финики символ Давайте немножко обсудим как это делается Допустим мы хотим букву е перевести собственно Финикийский язык что мы делаем мы видим что буква е расположена в строке которая собственно имеет идентификатор 3 и расположена собственно на втором месте поэтому
мы эту тройку идентификатор строки записываем подряд два раза собственно это есть в кодовое представление на буквы е Или например там букву Давайте букву Y Да видим что буква y соответственно в строке с идентификатором де на третьем месте расположено поэтому мы можем эту девятку три раза переписать собственно и получим букву Y вот такое вот собственно кодирование декодирование у нас получается задача стоит следующим вам да од стно из та максимальную длину вот оно записано собственно на финикийском языке корректное финикийское предложение вот также у вас Дан словарь слов состоящих из латинских букв собственно и задача такая нужно исходная
входное слово на финикийском языке декомпозировать да то есть разбить на корректные слова которые собственно Можно потом расшифровать влом первый пример у нас какой значит видим Что значит девятка - это у нас символ в да Поэтому если мы возьмём вот строку начинающий с девятки до конца это собственно будет действительно корректная репрезентация слова World собственно по вот этому Вот по вот этой вот таблички Ну и слово значит такое вот заканчивается последней шестёрке это собственно корректная репрезентация слова Hello вот видим да что и World и Hello они у нас собственно в словаре присутствуют Вот и соответственно нам нужно
вот декомпозировать входное слово на слова корректные из нашего словаря вот при этом собственно если Существует несколько способов расшифровки нужно вывести абсолютно любой хорошо Наде условие вам понятно значит давайте собственно переходить к решению Но прежде чем обсуждать уже непосредственно решение задачи Давайте немножко позадаём вопросы связанные с кодированием декодирования Вот и постараемся на них ответить значит первый вопрос Давайте лучше посмотрим собственно на перевод из цифр в буквы и из букв в цифры И вопрос такой а единственный ли способ допустим Представьте У вас есть кая строка например рочка из ТХ двоек единственный ли способ перевести вот эту строку
в строку из латинских букв и ответ кажется нет Поче потому буквы А можем вот так вот если мы разбиваем первым способом У нас две двойки это собственно буква Б одна двойка буква а иначе если мы сначала берём одну двойку и потом две у нас будет буква а и потом буква Б получается конкретному слову из финикийского языка а соответствует два различных слова собственно изн латинских букв и кажется это проблема в будущем вот вот собственно это нам потом ещё аукнется Теперь давайте сделаем наоборот вот у вас есть собственно кая строка из латинских букв Давайте какая-нибудь D DG
такая вот строка будет единственный ли способ расшифровки этой строки в цифры и ответ Конечно же да почему Да потому что каждый символ из каждый латинский символ имеет свой собственное уникальное представление в виде цифр Ну и собственно раз каж представление каждой буквы уникальна то собственно и способ декодировать в собственно тройку буква G в четвёрку и такой способ будет один и вот это на самом деле очень сильно нам в будущем поможет поэтому Давайте этот результат мы с вами запомним на этом этапе в голову может прийти достаточно простое решение кажущееся решение Да допустим у нас есть какая-нибудь строка
Входная там 3 2 4 4 2 5 6 какой-нибудь семь Вот такая вот Входная строка и мы собственно Хотим её перевести собственно в слова которые у нас есть в словаре Что будем делать Давайте идти с самого начала строки и каждый раз очередной набранный префикс собственно проверять Да декодировать его в строку состоящую из латинских символов проверять что эта строка есть в словаре если она есть то мы собственно этот префикс значит отсекаем и соответственно уже к расшифровке оставшейся части строки да Мы набрали префикс допустим про него забыли дальше переходим к расшифровке вот этого оставшиеся части и вот
здесь две большие проблемы первая проблема мы уже с вами сказали что строка из цифр может несколькими способами расшифровывать в собственно латинские буквы это проб проб заключается ВМ может такая ситуация Представьте что у вас вот строка распадается на соответственно два корректных финикийских слова и при этом первое слово есть в словаре а второе слова нету да то есть наш алгоритм что будет делать он будет идти слева направо вот здесь у нас сечёт наш префикс Да собственно скажет что слово набралось далее посмотрит на последнее слово его словаре нету И он скажет что Упс строку нельзя перевести в собственно
корректное слово словаря но может быть такая ситуация что целиком вся строка У нас есть в словаре Да тоже есть и поэтому единственный корректный вариант собственно расшифровать будет взять вот полностью вот эту всю строку и собственно перевести её латинские буквы поэтому данный алгоритм вот такой вот жадный Да набирать э эти самые слова из словаря как только набрали отсекаем заново набираем кажется некорректным да И вот здесь нужно что-то придумать что-то более оптимальное что-то более умное Ну и чтобы получить полное решение по этой задаче Я использовал метод динамического программирования Давайте более подробно в это погрузимся сразу Давайте какую-нибудь
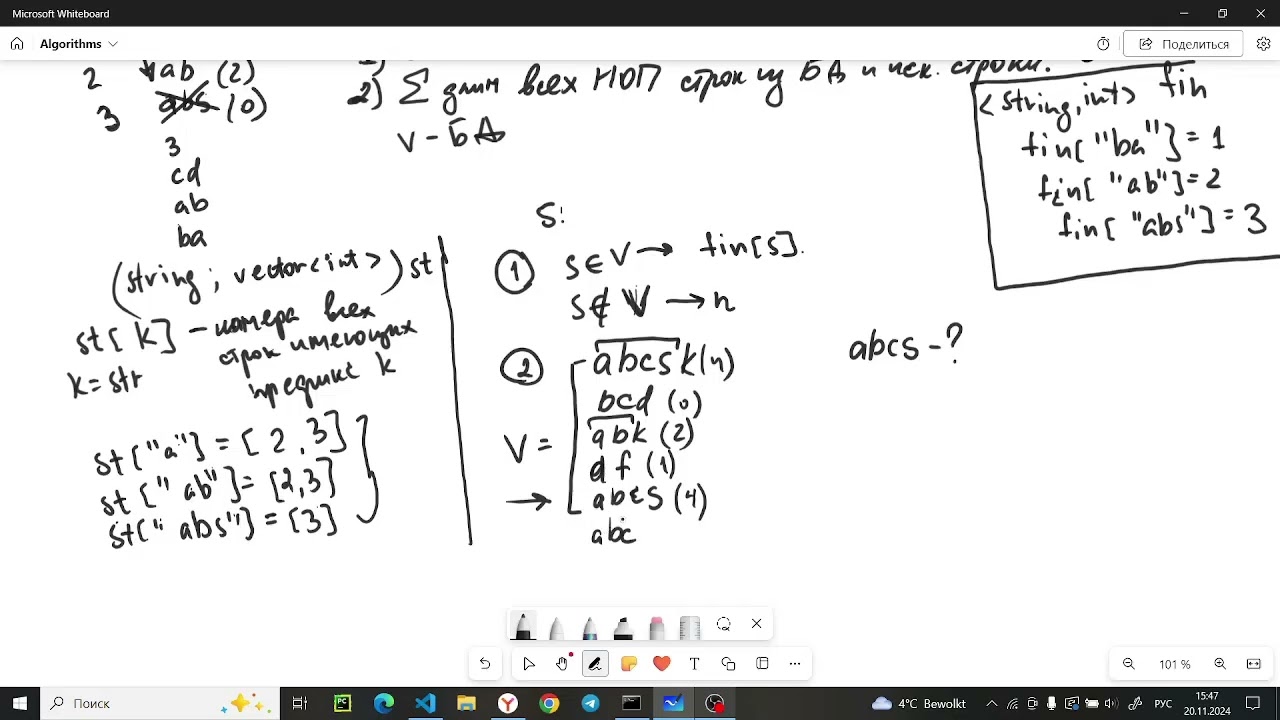
строку S просмотри так какая-нибудь там 3 4 2 5 5 5 6 2 2 2 3 4 ка такая строка у нас будет Входная строка для того чтобы решить задачу динамического программирования Нам ну массив И массив Давайте подробнее поговорим про то собственно что они из себя будут представлять значит что такое из исть Да массив из элемент в НМ и он будет равняться либо нулю либо едини в зависимости от следующей вещи из и будет равняться едини если если мы можем декомпозировать префикс строки S длины и на слова из входного словаря да то есть Давайте скажем что
у нас вот в - это входной словарь если мы хотя бы одним способом можем как-то декомпозировать нашу вот эту входную входной префикс длины и на слова из словаря то из и будет равняться едини в данном случае да если Мы это можем сделать из из и будет радини если мы это сделать не можем Да не существует ни одного способа чтобы разбить наш префикс и на слова где каждое слово было бы в нашем словаре да то соответственно из и будет равняться нулю замечательно с из им разобрались что касается соответственно ДП ито что же это такое хорошо значит
смотрите Давайте снова обратимся к нашей позиции скажем что допустим у нас и да какая-нибудь Такая позиция будет Вот здесь и тогда DP ИТ будет равняться либо G либо какому-нибудь ээ м какому-нибудь числу которое никогда не встретится э больше в этом массиве например какое-нибудь число не знаю бесконечность да давайте возьмём значит когда DP Ита будет равняться G И что же такое G вообще так вот G - это тоже позиция в нашей строке какая э позиция такая что подстрока S начинающаяся на элементе и заканчивающаяся на элементе и будет принадлежать нашему входному словарю Да смотрите Давайте вместо того
чтобы мы собственно цифры расшифровали в буквы Да мы знаем что это может быть неоднозначно мы будем наоборот из букв в цифры переходить поэтому Давайте вот у нас есть словарь обозначение возм все слова изго словаря в данном случае получается какие-то слова будут какие-нибудь слова World Quantum Hello все эти слова Мы собственно Предварительно переведём в числа то есть закодируй их числовыми да то есть это всё будет числовой словарь тогда DP ИТ будет равняться G если собственно подстрока строки S начинающей с индекса G заканчивающийся в индексом и будет принадлежать нашему входному словарю Ну и собственно Если такого не
существует да Если вот мы перебрали все вот эти позиции G начиная там от и до заканчивая нулём например И вообще ну не одно слово не принадлежит собственно нашему выходному словарю то собственно скажем чтоп и будет равняться бесконечности да такой метка того что а такого слова не существует Замечательно Это Всё конечно хорошо но лучше бы понять для чего вообще это нужно собственно давайте это выясним перепишем е раз эту строку 4 2 три пятёрки шестёрка двойка двойка двойка три иче вот наша строка такая вот будет Для чего собственно это надо давайте рассмотрим последнее последний собственно символ в
нашей строке мы знаем что По условию Да у нас говорится что гарантируется что существует хотя бы один способ Пра сообщение поэтому смотрите раз у нас существует хотя бы один способ и собственно рение кажется должно давать это способ что будет посмотрим на последнюю ячейку у нас здесь номер допустим и собственно будет равняться какой-то позиции скажем что позиция здесь у на буде например этот Что это значит Это значит что вот э вот подстрока начинающая а теперь посмотрим на собственно значение G -1 это у нас вот эта позиция и посмотрим конкретно на значение из от G -1 и
если и G - радини Что это значит Это значит что мы выделили вот это вот слово оно есть в словаре и весь префикс длины G -1 остаточный мы тоже можем декомпозировать на слова из словаря Да потому что и Что это значит значит что мы можем Вот это слово выделить сказать что это слово из нашего ответа и потом перейти от Вот это позиция с конечной Вот вот сюда в позицию G -1 и теперь получается мы пришли От декомпозиции префикса длины -1 да то есть всей строки Мы хотим всю строку разбить на слова перешли к декомпозиции префикса
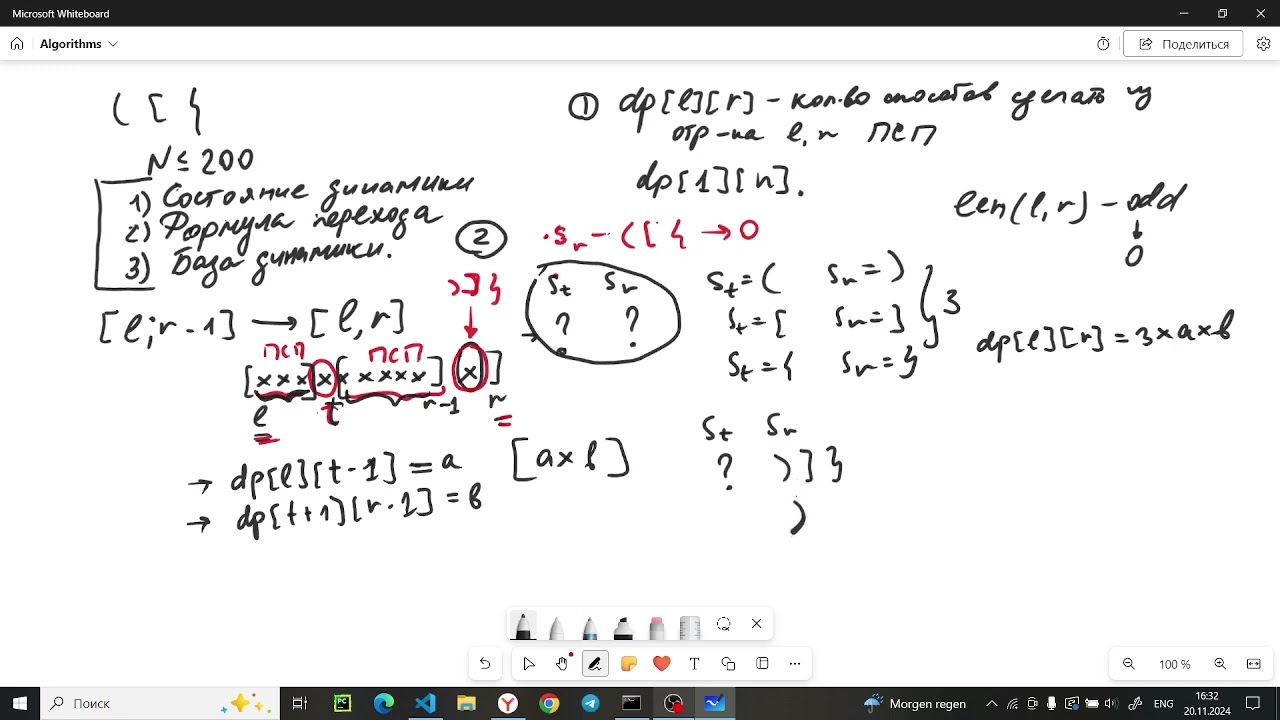
длины G -1 выделили последнее слово и перешли к префиксу Лины G -1 Но ведь у G -1 тоже есть какое-то значение DP да то есть DP там G -1 какой-нибудь будет да то есть у нас получается какая-то другая позиция к вот здесь будет соотвественно теперь мы переходим к вот такому же префиксу это новое слово у нас Получилось Да вот слово у нас вот здесь слово и снова получается какой-то другой префикс и снова переходим вот этой позиции и так далее пока мы окончательно не декомпозировать хорошо но нам нужно понять как на практике пересчитывать массив ДП и
массив из собственно этим мы сейчас и займёмся давайте снова Или давайте сейчас очищу это всё запишем нашу строку S А так так-так и собственно поймём как мы будем конкретно высчитывать эти значения DP и и значит давайте идти по нашей строке слева направо и вот допустим представим что мы дошли до позиции и когда мы говорим про решение задачи путём динамического программирования мы говорим что мы уже умеем считать случае и и из для всех от Ну до и ми1 то есть мы знаем значение динамического программирование так сказать да Для всех вот этих вот ячеек мы уже их
умеем считать и нам нужно как-то научиться пересчитывать собственно длях от этой позиции значит попробуем выделить какую-то подстроку и посмотреть а является эта подстрока словом из входного словаря причём мы будем делать это не вложенными циклами да как это обычно можно сделать вять который будет Вот так вот итерироваться собственно брать очередную подстроку пытаться расшифровать её в слово из словаря и так далее тогда можно сделать а можно сделать чуть по-другому можно сонно перебрать позиции и Давайте переберёмся первое если это равно единички Значит мы можем разбить наш префикс как-то декомпозировать его на слова сходного словаря супер теперь Давайте попробуем
взять подстроку строки S начинающуюся в позиции и и имеющую такую же длину как и строка Т то есть длина L допустим вот такая вот строка будет взяли Вот эту вот под строчку Теперь попробуем счи Вот эту вот подстроку и строку т и если они одинаковые то вот мы нашли соотвественно новое слово которое входит в наш словарь тогда мы можем уже апдейт значение Вот это получается там и п L Ми 1 потому что мы вот мы сли поняли что вот эта вот подстрока совпадает со строкой Т из и ми ра едини то есть мы можем этот
префикс разбить и собственно получается Что получается мы можем и префикс длины и п входное слово заканчивается в позиции и пми оно начинается в позиции и да то есть Таким образом мы можем перебрать все строки из нашего входного словаря попробовать сметь эти строки с под строкой строки начинающей позиции имеющей такую же длину и апдейт нуть все соответствующие вот такие вот е для всех вот этих вот последую позиций собственно мы будем делать да получается какая у нас асимптотика будет асимптотика будет от Да потому что мы перебираем все соответственно символ входной строки также мы перебираем значит все строки
входящие в множество пытаемся сметь их на каж пого случае мы собственно пытаемся сравнивать эти строки сравниваем под строку строки S и сравниваем строку Т собственно мы видим да что длина каждого слова из входного словаря не превышает 156 то ещё максимум умножаем там на 256 Вот такая вот асимптотика у нас получается мот обозначить какая-нибудь длина Там D ИТ вот на самом деле Вот это решение не будет работать на полный балл Почему Потому что вот это вот это слишком долго на бы хотелось сделать что-то быстрее и вот здесь что мы можем оптимизировать та это сравнение строго и
сделать это мы можем с помощью полиномиальной хаширова то есть получается мы будем непосредственно проходиться по всей этой подстроке и пытаться сметчик её с нашей строкой т а сделать это Чуть более умным способом И вот собственно это можно сделать с помощью полиномиальной хаширова Нея поэтому давайте сейчас мы немножко отступим и я сделал небольшой экскурс в то что это такое Как это работает и дальше уже собственно продолжим обсуждение этой задачи Итак что же такое полиномиальное хеширование Представьте У вас есть две строки строка S состоящая из символов s0 S1 и так далее SN и строка Т состоящая из
символов т0 Т1 и так далее и ваша задача сравнить э две строки сказать они одинаковые или различные ну самое очевидное решение решение за у от N пройтись по всем символам первой строки и сравнить каждый символ первой строки соответствующим символом из второй строкино сделать даль уже выводы од те оптимально да то есть избежать вот этого вот сравнения за ун сделать что-то гораздо гораздо более оптимальным и собственно на помощь приходит идея полиномиальное идея заключается в следующем Давайте сопоставим каждой строке какой-то число H от S и собственно будем сравнивать теперь не строки а числа при этом соответственно Мы
хотим вот эту функцию сделать таковой что если у нас строки одинаковые то соответственно и хэш-функции не одинаковы от них Да и собственно если строки различные то и хэш-функции должны быть тоже различны Да ну и наоборот если функции различны то строки различные и если функции одинаковы то строки тоже одинаковые то есть идея заключается в том чтобы перейти от сравнения строк К сравнению чисел Однако теперь нам нужно корректно задать Вот эту вот функцию которая по строке будет выдавать нам число и одной из вариантов этих функций является просто полином да полиномиальное хаширова то есть функция каким-то многочленом значит
давайте во-первых во-первых мы поймём какой вообще алфавит используется в наших строках в данном случае давайте скажем что алфавит у нас будет состоять из символов от А до Z Да маленьких латинских букв их у нас всего 26 букв Теперь давайте каждой букве сопоставим какой-нибудь числовой код Ну например букве а сопоставим числовой код о букве б числовой код 2 и так далее бук числовой код 26 также примерно равное количеству символов ВМ алфавите и делящееся простым Ну в данном случае подходит например число 31 они примерно сравнимы с и собственно число 31 является простым замечательно А теперь смотрите Теперь
мы очень легко сможем задать нам вот эту вот функцию H от S и функция будет выглядеть таким образом это будет п в степени 1 плюс и так далее плю S у P в степени N Когда я пишу s0 S1 и так далее SN Я имею в виду соответственно числовые коды соответствующих букв числовой код буквы s0 числовой код буквы S1 и так далее очевидно что вот эта функция является числом да вот и с очень-очень большой вероятностью во многих задачах эта функция действительно будет удовлетворять вот этим вот свойством Да самый плохой случай когда у нас строки различны
А хэш-функции у них одинаковые да Это плохой случай тогда у нас сравнение будет некорректно это случай называется коллизия Да когда хш коды различных строк совпадают вот Однако в многих задачах можно сказать что вот это вот происходит с очень-очень маленькой вероятностью и этим можно пренебречь и использовать такой вот полиномиальный хш от нашей строки замечательно последний момент кой остаётся выяснить это то Насколько быстро растёт наша функция Да не трудно убедиться что если у нас строка какая-то очень большая например 100.000 символов то очевидно вот эта вот сумма будет очень и очень-очень большой и соответственно Как считать Да ну
ответ достаточно простой Давайте читать эту функцию по какому-нибудь модулю да то есть будем вычислять не значение самой функции а значение этой функции по модулю а то есть остаток отделения этой функции на какое-нибудь число M нужно выбрать обязательно модуль достаточно большим чтобы у нас Чтобы избежать вот этих ситуаций называемых коллизий Да вот собственно выбираем модуль и Вуаля мы теперь умеем В каждой строке сопоставлять число и дальше уже сравнивать эти числа и в зависимости от результата сравнения чисел говорить о том различны или одинаковы наши строки Отлично мы выяснили что такое полиномиальное хаширова А теперь давайте применим его
немножко в другой задаче Представьте у вас есть две строки опять же s0 S1 и так далее SN и строка Т т0 Т1 и так далее Т уже M Давайте скажем что N у нас будет больше чем M сразу давайте рассмотрим пример и потом уже обобщим всё это на общей на более общий случай значит пусть строка S стать символов s0 S1 S2 S3 S4 и S5 например и строка Т будет состоять из символов т0 Т1 и Т2 и нам бы хотелось проверить совпадают ли подстрока строки S начинающийся с второго символа заканчивается четвёртым Вот и собственно строка
Т да то есть теперь мы хотим сравнивать не две строки а одну строку с под строкой от другой строки Хорошо давайте посмотрим на собственно функцию У нас есть функция строки S это у нас будет s0 на P в степени 0 П S1 на P в степени 1 П S2 на P в степени 2 и так далее плюс S5 на P в степени 5 и есть ш функция от второй строки Давайте возьмём Ту же самую H от Т Да и скажем что здесь у нас получается 0 P сте 0 п1 степени 1 П2 на P степени
2 хорошо у нас известно вот такое вот значение и вот такое вот значение нужно их сравнить как-то но очевидно во-первых Давайте выделим собственно из этой хэш-функции от H от S выделим значение функции отвечающее только за Вот эту вот подстроку очевидно это будет что очевидно это будет S2 на P в степени 2 п S3 п собственно S4 P в сте 4 Давайте опять же считать функции как собственно префиксные суммы то есть заведём массив H Да где H ИТ - это будет собственно сумма давайте от S это будет сумма получается s g от Ну до собственно и
S Умно на в степени G То есть получается H и от S - это собственно хш функция от префикса строки и длиной строки S длины и хорошо тогда мы знаем что из метода фикх сумм чтобы получить хш вот такой вот получается подстроки Мы можем взять H4 от S и вычесть соответственно H пер от S Таким образом мы возьмём префикс там длины даз и вым мусор вот это вот который то что нам и нужно а значение ш функции под строки сно от номера два до номера 4 Замечательно Это мы можем выделить сделав вот такое вот преобразование
Однако Да и получаем соответственно эти вот вещи S2 на P в степени 2 + S3 на P в степени 3 и п S4 на P в степени 4 а Здесь мы получаем т0 на P в степени 0 + T1 на P в степени 1 и собственно плюс Т2 на P в степени 2 отлично количество слагаемых одинаково Однако что мы видим Мы видим что степени соответствующие отличаются на Ровно одну и ту же величину на два да то есть получается из-за того что у нас а вот это вот это подстрока в строке s да то есть начинается
она собственно Она идёт не Сначала с нашей строки о а после какого-то смещения Да поэтому все степени у нас будут соответствующими смещения и нам бы хотелось эти степени УВ Ну можно конечно же вот это результат поделить нак А можно сделать наоборот Да мы знаем что раз у нас всё хш по модулю считается а деление по модулю это более сложная операция что можем сделать мы можем второй хш умножить нак Да и собственно получаем уже вот такое значение т0 на P в степени 2 плюс соответственно Т1 на в степени 4 вот такой вот хэш от этой подстроки
и вот такой вот хэш от подстроки из строки S и теперь уже Мы можем их сравнивать Да мы привели их к одинаковым степеням P посчитали эти хэши осталось просто сравнить эти числа и собственно проверить на совпадение Таким образом мы за у от единицы с помощью вот такого преобразования и дальнейшего умножения на следующую степень получили хш от подстроки данной строки да и учились собственно их сравнивать замечательно и собственно Давайте теперь обобщим это на собственно общий вариант Какой общий алгоритм у нас будет если мы хотим получить хэш аэ от строки S от подстроки строки S начинающий с
позиции и заканчивается позиции G Мы можем взять из жи той ячейки и вычесть соответственно и минус первую ячейку хорошо мы получили вот такой вот такую вот величину и остаётся теперь раз мы хотим сравнивать Эти хэши нам бы хотелось привести хэш вот этой строки значит Да чтобы степени были одинаковы таким образом нам нужно второй хэш умножить на соответственно P в степени и Супер это у нас с первой хэш-функции происходит это у нас со второй хш функции происходит Ну а дальше уже можно собственно выполнять сравнение отлично получается мы избавляемся от Вот это вот множителя Да собственно теперь
нам не нужно проходиться по всей подстроке чтобы сравнить её с вот этой вот строкой т и собственно мы теперь это сравнение с помощью полиномиальной хеширования можем проводить за у от единички собственно и итоговая симптом А количество строк лежащих в нашем входном словаре что в целом достаточно оптимальное решение и проходят все тесты супер вот так вот с помощью динамического программирования и полиномиальной суть своего рассуждения суть своего решения А теперь давайте перейдём непосредственно к кодин вот так вот выглядит програмное решение задачи и Давайте разбираться с ним подробнее значит здесь я объявляю несколько констант которые нам понадобятся в
дальнейшем Константа Long Long inf отображающая собой такую абстрактную бесконечность Да просто очень большое число на практике далее Константа P равна 31 собственно Константа которую будем использовать в хеширование Константа ма N равняется миллиону это собственно Максимальная степень в которую нам придётся возводить число P или же максимальная длина строки которую нам вообще придётся когда-либо зашивать это либо длина строки в числовом виде из входного словаря либо собственно длина входной строки которая нам нужно будет потом декомпозировать на строки из словаря Ну и собственно модуль я взял модуль 10 п 7 Вот хорошо что я делаю далее Далее объявляю массив
котором собственно заранее предпочитаю все степени числа P Ну и массив H с помощью которого мы будем производить хеширование далее объявляю две вспомогательной функции и сложение и умножение по модулю соответственно на практике это очень хорошая тако привычка Да очень сильно помогает делать вычисление по модулю далее собственно функция которая вычисляет все степени числа P мы знаем что P в нулевой степени - это единичка А дальше P в степени и это P в Степе - 1 у P далее функция которая собственно считает хш от переданной ей в качестве аргумента строки S что мы делаем мы очищаем массив H
если там что-то лежало заранее считаем размер нашей строки А дальше вычисляем Просто ш Да у нас H и то есть ш от фи длины и это хш От преф длины и -1 плюс собственно очередное слагаемое очередное слагаемое - это числовой код очередного символа умноже на P в степени I да то есть просто S Уно P в степени I всё как мы обсуждали в теоретической части далее функция Get substring хш которая вычисляет хш от подстроки по заданной позиции начала и собственно длины нашей подстроки то есть формально Мы хотим посчитать строки начинающей в позиции и собственно заканчиваю
позиции п -1 собственно берм ш от всего префикса д п - далее если у нас ID не нулевая позиция да то есть если у нас подстрока не является префиксом то у нас есть какой-то мусор который мы хотим вычесть собственно мы его вычитаем вычитаем H мием жу три отображения и сейчас Обратите внимание Только на первое из них это отображение из символа в строку оно используется для того чтобы закодировать каждую букву латинского алфавита в строку из чисел финикийского алфавита далее тут два отображения из числа в строку дикт и и н да запомните это мы впоследствии их ещё
коснётся они нам очень сильно понадобятся далее функция N код которая каждой Латинской букве сопоставляет строку из чисел Да тут код достаточно понятный Просто реализуем то что у нас есть в табличке данные в условии собственно сум сим да по конкретному символу латинского алфавита хранить себе строку его кодирующую далее собственно функция STR которая по зада строке S состоящий из латинских букв за кодирует её и возвращает строку уже состоящую из цифр что мы Для этого делаем мы идм по всей нашей строке и собственно Каждый раз к переменной результата прибавляем код очередного символа нашей строки который уже хранится в
нашем отображении замечательно теперь переходим к основной части к функции Sol для начала мы собственно кодируем все латинские буквы вызываем функцию предпо заранее все степени далее мы объявляем входную строку считываем её считываем количество слов выходном словаре А дальше их собственно обрабатываем объявляем очередное слово считываем его из словаря далее что мы получаем собственно кодируем его цифрами получаем цифровое представление этого слова далее считаем хш уже от цифрового представления Да соответственно теперь хш собственно всей строки хранится в последней ячейке ма собственно мы его берм и теперь что мы делаем теперь у нас появляются те самые два отображения отображение и
отображение собственно по заданному хэш Да по вычислено хешу от текущей строки словаря мы собственно кладём его латинское представление да то есть представление этого слова латинским буквами и представление этого слова в виде цифр собственно это нам нужно для восстановления от это уже дальше у нас при собственно динамическом программировании нам понадобится Замечательно а дальше что мы делаем дальше мы вычисляем хэш от входной строки собственно и теперь в массиве H у нас хранятся хэши префиксов строки S входной строки Это важно далее Я объявляю массив ДП собственно заполнить изначально константами очень большими бесконечностей отображение из которое числу сопоставляет логическое
значение переменной но или о здесь использу отображение потому что я вот здесь хочу минус первой ячейки сопоставить значение оди потому что у нас там строка нумеруется с нуля Вот и нам нужно какое-то значение отражающее вот пустой префикс да то есть формально здесь говорю что формально говорю что пустой префикс я могу декомпозировать на слова из входно словаря но а пустой префикс для этого у нас ну используется индекс -1 можно от этого избавиться можно вообще избавиться от массива is Вот и собственно сделать это без этого однако для лучшего понимания для того чтобы прямо вот ну визуально было
понятно я решил это всё здесь оставить Хорошо а теперь собственно вычисляем значение динамического программирования а далее мы пытаемся набрать очередное слово которое начинается в ячейке и во-первых проверяем что мы можем декомпозировать префикс длины и -1 на собственно слова из словаря если это можем сделать тогда мы можем набрать очередное слово начинающееся в позиции и если мы этого не можем сделать то мы собственно прекращаем Да ничего не набираем нашей позиции и если у нас и и -1 равно едини мы можем декомпозировать префикс длины и ми1 тогда что мы делаем тогда мы перебираем все слова из входного словаря
ключом служит хш коды собственно значением служит кодовое представление каждой строки в виде цифр что мы делаем значит извлекаем размер этой строки из цифр дальше проверяем что мы не вышли за границ массива если мы не вышли за границы массива что мы делаем мы собственно считаем хэш под строки строки S имеющей такую же длину как и слово как текущее слово из входного алфавита собственно берём хш этого слова исходного алфавита да до умножаем этот хэш на степень на P в степени и Да чтобы эти степени смещение у них уравнять А дальше проверяем на совпадение эти хэши если хэши
одинаковые да то собственно обновляем значение ДП и п СЗ -1 говорим что для вот той позиции началом входного слова которое заканчивается в той позиции будет позиция и то есть у нас получается что слово и то есть подстрока начинаю позиции и и заканчиваю в позиции и ПЗ -1 есть в нашем входном словаре Ну собственно говорим что теперь префикс длины и п СЗ -1 мы можем тоже декомпозировать на слова из словаря замечательно значение динамического программирования всех динамики мы посчитали и остаётся собственно из этого теперь получить ответ Собственно как именно мы декомпозировать idx изначально равную N - 1
собственно это позиция конечная позиция последнего слова и теперь пока idx будет больше ра нуля что мы будем делать Значит у нас есть позиция idx это позиция которая указывает на Последний символ последнего слова Теперь для этого мы можем найти начальную позицию очередного слова да Для этого мы собственно и делали динамику получается теперь очередное слово у нас будет и заканчиваться в позиции idx собственно копируем это слово берём от него хш собственно Да хш посчитали А дальше что мы делаем А дальше собственно мы Обращаемся в наше отображение к которое по хш кодам хранит соответственно латинское представление слов из
словаря собственно берм латинское представление по хэш вот этой вот подстроки и собственно кладём его в ответ А дальше прыгаем на ячейку ST -1 то есть вот это слово мы Свами получили и теперь нам нужно декомпозировать уже префикс собственно начинающийся в позиции ноль и заканчиваются в позиции ST -1 Ну собственно делаем до тех пор пока вот это вот idx переменно будет больше или равна нуля до тех пор пока мы собственно всю строку не декомпозировать на слова из словаря дальше мы получаем что раз мы слова эти ляли начиная с конца то они у нас в массиве АС
будут лежать в обратном порядке поэтому мы массив АС разворачиваем и собственно получаем Ту самую искомую декомпозицию выводим его на экран и собственно задача решена