um and we just said this that uh one drawback of a ridge regression it doesn't actually select variables and set things to zero when as you said in situations like that previous picture where things are small would be nice if they could just say these are zero we can forget about them so the lasso is a more recent technique for for shrinking coefficients in regression it looks very much like ridge regression but with one change so here's the lasso criterion again we have the the rss as before now we have a penalty but whereas before
the penalty was the sum of the squares of the coefficients now it's the sum of the absolute values of the coefficients so it's a shrinkage towards zero using an absolute value rather than a sum of squares and this is called an l1 penalty uh in by analogy to the l2 penalty the l1 penalty is just the sum of the absolute values it's a norm but it's called the l1 norm rather than the l2 norm so what's the effect of changing this from a square to an absolute value it's actually a small change but it's quite
important um it turns out that the lasso like the ridge shrinks towards zero but it has the effect of actually setting variables the coefficients of variables uh exactly equal to zero when lambda is large enough so it's it's neat it does it shrinks but also it does subset selection in a similar way to the best subset selection so it'll set coefficients to zero exactly if that feature is not important and lambda is large enough so we say that this this there's a term for this is called sparsity so the last cell yields was called sparse
models models which only involve a subset of the variables and again it's a function of this tuning parameter lambda which as an original regression we have to choose somehow and we'll do so by cross validation so wow the lasso seems like a really good idea so clever i wonder who came up with it rob thanks so daniela's trying to embarrass me so this was so it's actually a paper that i wrote in 1996 and it's become at the time actually it was published and didn't get a lot of attention but in the last about 10
years or so it's become a very hot topic both in statistics and computer science and other areas and there's been a lot of work in sparsity in general not just regression but the use of l1 penalties in a lot of different areas i think one reason for its popularity now is computation this computation is actually this is what's called a convex optimization so that's good news um and there's a lot of work in complex optimization especially in the last 10 or so years and along with so the the the progress in complex optimization and fast
computation fast computers um people can solve this problem now of a lasso for very large values of p and n and this is actually just been a fun thing that i've even seen like when i started grad school you know there was like one approach that statisticians were using to to fit this model and um this was a famous paper that had just come out when i started and it was written by rob and trevor and a few other people at stanford and statistics and then then a new paper came out with a better idea
and then 20 more papers came out with better ideas for how to fit this model and this has suddenly become something that anyone can solve on their laptop no matter how big your data is basically and so it's just become an incredibly useful tool in a way that it even wasn't when i started grad school so we'll talk about uh glm now which is on our library which we use a lot in this book and in the in the book in the course and we'll we'll show you uh how you can solve a problem like
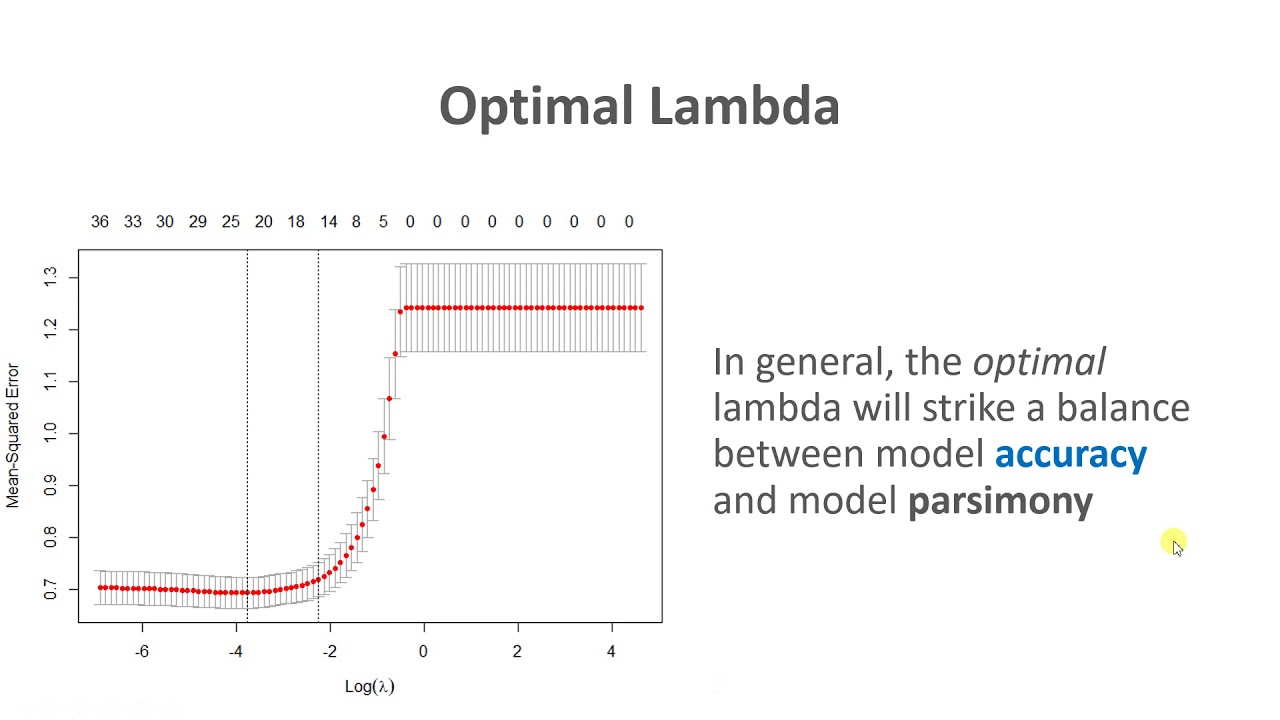
solve the lasso using glm9r again where the numbers of variables might be in the tens of thousands you can solve it in on a standard desktop computer in less than a minute so we'll talk about the computation later on in the course but let's let's first see what the what looks like in the same example now so again the credit data set and we're plotting the standardized coefficients as a function of lambda for the lasso again we haven't talked about how to choose lambda and that's going to be important we use cross validation but let's
for now look at the solutions as a function of lambda for all values of lambda and now you can see again when lambda is small we get essentially the full least squares estimates when lambda zero we get exactly least squares if i plotted this all the way to the left and now as we increase lambda we get shrinkage as we do for ridge regression but something special happens at this point for example here beyond this point all these gray variables are exactly the coefficients are exactly zero whereas for ridge regression they were small but they
weren't zero so it's actually we can tell it tells us you can throw away all these variables at this point and just retain these three the blue red and orange similarly this plot shows you the same thing in the other direction so it's it's a combination of both shrinkage and selection of variables and so one thing that's worth mentioning is that in a lot of applications selecting variables is actually really important because you know let's say i'm working with a doctor who wants to come up with a really good way to to test for some
particular disease and he might start out by getting 30 000 gene expression measurements for patients with this type of disease so he starts out with p equals 30 000 and he wants to find a really great model that can be used to transfer this disease but when push comes to shove and he's actually going to use this test in the clinic he doesn't want a test that involves all 30 000 genes because a test like that would be too expensive it just wouldn't be feasible to actually use but if he can get a test that
works really well that only involves six or eight or 25 genes that could be a real breakthrough in testing for this disease and so just from a practical perspective the lasso is just hugely useful because it allows us to efficiently find these types of sparse models that involve just a really small subset of the features you should be you should be my personal sales salesman doing good job but but seriously i mean danielle is right and i i myself i use the lasso in schools and projects here at the medical school it's very satisfying to
you know to apply it and to you know to see it helping helping uh scientists to find the signal in their data and come come up with interpretable subsets among the thousands of features they present to me so at this point it might seem like magic why it is that that's just using absolute value penalty gives us the sparsity property why do we get exactly zero and i'll i'm going to show you that in the picture so let's let's think about that um first of all we can we can we we can formulate the problem
in an equivalent way rather than putting a penalty remember before i had this i had the rss plus lambda times the sum of the absolute values an equivalent way to say the lasso is to pose the lasso problem is to say minimize the rss with a constraint a budget on the total l1 norm of the coefficients okay so this is an equivalent problem in the sense that if you give me a a budget s there's a lambda in the previous formulation that corresponds to the same problem and vice versa and by the way if that
looks like a total mystery if you can like reach back to your you're just in a not so distant past if you ever took ap calculus and you saw lagrange multipliers in high school this is really something that you you might have truly seen in in high school calculus a long time ago but for simpler types of problems and that's just this is just a more complex application of that same idea but in a way that it's bound form is is to me more intuitive in the lagrange form because it's think of it this way
suppose you that you you do full least squares and you get a certain answer and now i tell you and let's suppose the sum of the absolute values of your coefficients is 10. so you give me an answer and i say well actually i want to i want to make your budget smaller you've spent too much coefficient so rather than 10 i want to give you a budget of maybe 5. so now i ask you to solve the same problem but you're not allowed to use the coefficients as large as you want you have the
total budget you have is 5 and that's the bound here so the last i was giving a budget on the total l1 norm that you can spend and within within that budget you have to fit as well as possible and as a budget gets smaller and smaller the coefficients get smaller and smaller if the budget is zero the coefficients have to be zero if the budget is large enough you can you you're free to use fully squares but in between the budget's going to trade off the size the coefficients would they fit so i think
it's it's quite an intuitive way of looking at these problems for ridge regression you get exactly the same analogy but now the budget is in terms of the sum of squares so again this is equivalent to the the lagrange formulation for ridge regression we saw earlier but the reason i want to bring this up is this following picture which helps to explain why uh the lasso gives gives sparsity so on the right is ridge regression and on the left is the lasso it gets this a bit more mathy than most things in this course but
hang in there and i think if you do you'll it'll be some payoff so this picture is ridge regression so what's going on here this first of all p is two so there's two coefficients and i've indicated here the full least squares estimates so if there's no there was no penalty i just did least squares on the two variables i'll call the solution beta hat and that's this point and now the sums of squares in in the in the rss um the contours of that function and i was it's lowest here because that's the least
squares estimate but now as i move away if i think of this like as a maybe a cereal bowl and i slice the cereal bowl here are the contours so here's the value at which rss is a bigger value this next contour is a higher contour of rss so these are the contours of rss as i move away from the minimum okay and this is the constraint region remember in ridge regression and this formulation here says you have a budget on the total sum of squares of the betas so the budget is the the radius
of the circle right and here i have a fixed budget and so in words the ridge problem says finally the first place these contours hit the constraint region in other words find me the smallest rss you can get within the budget defined by this circle that's ridge regression and the solution in this picture is right here so this is the the ridge estimates for this budget in the in the data this particular data that the data is determining the shape of these contours and the location of beta hat so ridge regression says finally the first
place the contours hit this constraint region it's this solution and you can see because the constraint region the sum of squares is a circle this is where the sum of squares of beta 1 and beta 2 is less than a budget it's a circle right and unless you're very lucky that you're not going to hit exactly at a place where one or the other is zero right now let's move over to the lasso same picture least squares same thing the the sum of squares function is the same all the same up here but this the
constraint region is now the sum of the absolute values so rather than a circle it's a diamond a diamond has corners so in this picture i've hit this corner and now i get a place where beta 1 is beta 1 hat is 0. right so here's the lasso estimate so in other words to summarize the absolute values give you a constraint region that has sharp corners and high dimensions you have edges and corners and along an edge or corner if you hit there you get a zero so this is geometrically why you get sparsity in
the lasso so here's oh sorry um here's our case first of all the returned example where we had 50 uh let's see four things for the 45 variables and they all had nonzero coefficients so now i'm looking at comparing the lasso to ridge so on the on the left picture for the lasso we see the bias variance and mean square error as a function of lambda and the right we've superimposed the biased variance in mean square error of ridge aggression with the broken line and the lasso and we can see that overall so again the
solid line here for mean square air is the lasso the broken line is ridge they're very similar ridges a little better perhaps right so we don't we don't do much better we don't do better at all with the lasso here and the reason is is that we've got the true model is not sparse the true model actually involves 45 variables all of which have been given nonzero coefficients in the tree in the population so so it's not surprising we don't do better than ridge in this case and one thing we should mention is the on
this right hand panel the the x-axis is something we haven't seen before which is the r squared on the training data and the reason we have that x axis is because in this figure on the right hand side we're plotting both ridge regression and the lasso so it wouldn't make sense to to you know show ridge regression and the lasso with lambda on the x-axis because the lambda means two different things for those two models so when we look at r-squared on the training data on the x-axis that's kind of a universally sensible thing to
measure regardless of what the type of model is so um you must have drawn this picture in the book yeah i made this picture it's a beauty thank you yeah okay i would have noticed that detail otherwise okay so now now here's a situation where we do we do perform better with the lasso and this is the case where now in the population only two of the predictors have non-zero coefficients so the previous situation was was dense or non-sparse this situation is sparse we've only there's only two predictors in the true model that are nonzero
coefficients now we can see what happens well the lasso's mean square error here is minimized for quite a large value of lambda because it wants to make the model sparse as it needs to there's only two nonzero coefficients and now when we compare the lasso to ridge remember ridge is the broken line and the lasso is the solid line you can see we do quite a bit here's the lasso's mean square error and there's ridge is here you know you can see we're doing quite a bit better using the lasso in this situation and again
it's not surprising the true model is sparse so it pays to use this a a technique which encourages sparse sparse models coming out of its its estimation whereas with ridge it doesn't we don't get a sparse model we get a dense model so in conclusion we're comparing these two techniques as as is usually the case in in most things in statistics and science in general there's there's no rule that there's no simple rule that means that you should always use one technique over another it depends you always hear that from statisticians it depends well it
depends on the situation in in this particular case if the true model is quite dense most predictors are not have non-zero coefficients we expect expect to do better with ridge if the true model is quite sparse only a few coefficients have are non-zero then the lasso can be expected to do better of course we don't know that usually we hope actually that things are sparse because life is simpler then but going into a data analysis we have no idea whether the true number of coefficients non-zero coefficients is large or small so we have we use
it's typically to apply both methods and use cross-validation to determine the the best model coming out of each method and then compare the cross-validated error for the two methods