hello all today we will be solving I will be creating a book recommendation system using K nearest neighbor and in my previous video I have already shown you how we can create a book recommendations from using tour relation that is Pearson correlation but now we basically use advanced machine learning technique called as K nearest neighbor or you can just say nearest neighbor which is also an unsupervised technique and will try to find out which are the similar movies that can be recommended to the users as usual when if you have seen my previous video the
first step is that you download the data set from this particular URL and then I'm going to take some data sets the CSV file like books or CSV I'm going to consider with this some columns from them and then I'm going to see the users dot CSV and finally the book ratings dot CSV so I'm basically using ponders to read all this particular CSV file I'm reading the data set with all the necessary features after reading it these are some warnings no need to worry about it but just consider all the data set that you
have and then here are some rating distribution that I'm sure are trying to check all these code materials are present in the github link you just have to download from the description box and then what you can do that after downloading you just go and run this all things ok everything is same like my previous session if you have already seen you have not seen he's going go ahead and have a look how we are done with the help of how we created this book recommendation system with correlation Pearson correlation but all the steps are
same till here till the seventh step all the steps of stream where I'm actually reading the data set I am basically seeing the shape of the ratings data set similarly with seeing the shape of the movies data set also so here it is every information is given over here and then this is basically I am trying to check out the histogram of the user age I am trying to see that how many people what is the age distribution basically what people have basically seen okay basically if people have you know given their ratings now will
apply some statistic analysis saying that if the users are given will consider only those records or those ratings where the users have BC even more than 200 ratings and the book should not a book with less than 100 rating should not be considered because there will be so many books guys which will just be having one rating to reading free ratings and very less number of ratings and by that we cannot just consider that that book may be you know a very famous and a popular book so what we do is that I'm trying to
put this condition when if the users are given more than 200 ratings I am going to consider those kind of books along with the books rating which are less than hundred I'm just going to exclude them okay so this condition I am just applying on my ratings data set by finding my value counts and then putting this condition where my counts is greater than 200 I am going to take that indexes only similarly in the case of the ratings column also I am saying that if it is greater than 100 with respect to a specific
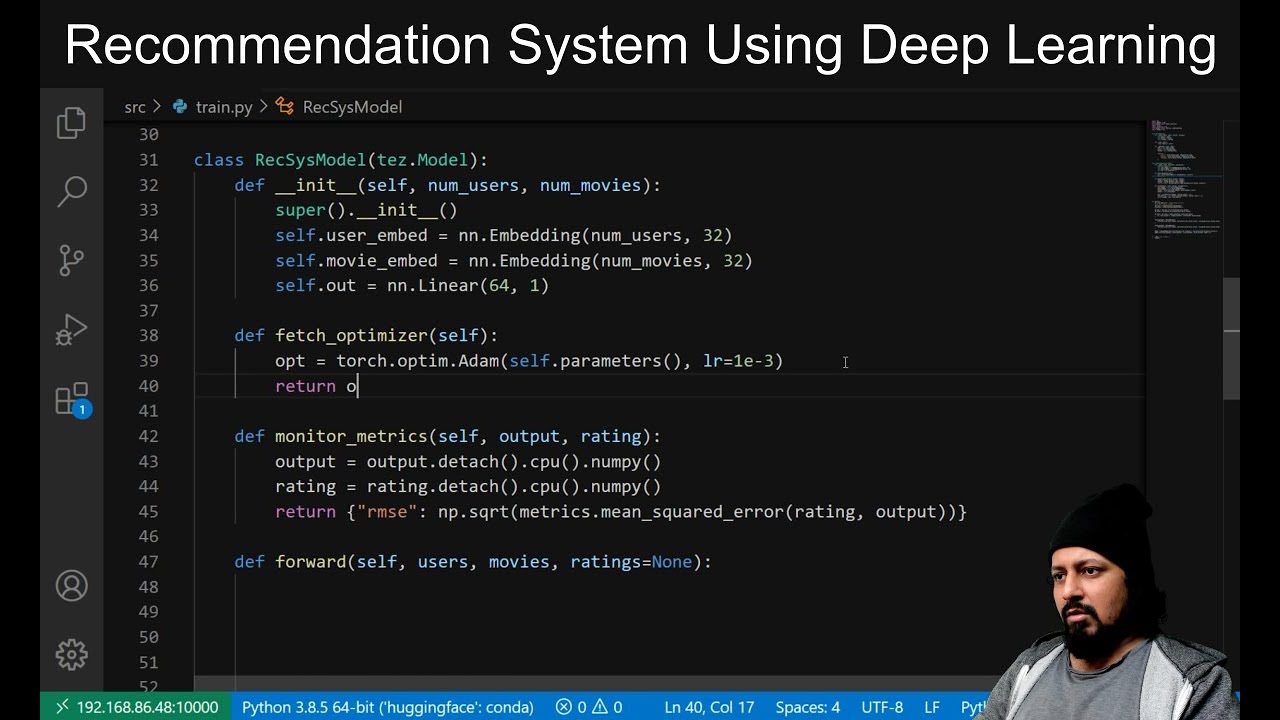
user I am going to take that particular record on me all you have to do guys this is very much simple just executed line by line you will be able to understand now the main techniques arises how do it and in this particular technique am Biscay but we use collaborative filtering using K nearest neighbor what I will be focusing on guys series first of all I have my readings data set which I have read it from my data set I have book data set right I'll try to merge this 2 based on ISBN which is
my unique user unique ID of the book once I merge it I have my combined book book ratings and from this I am specifically taking some of the columns over here so this all columns I don't require it so Ron I'm just making it as a list and I'm dropping it over there from here because for collaborative filtering all I will be requiring is my user ID ISBN book rating and book title you'll just see to it how it is done so here when I see the head of my data set of the combined after
merging and after dropping the columns I basically have four things one is user ID is being book rating and book title now the next thing arises is that what we are trying to do is that I try to find out the count of the ratings you know though we'll see we then group by book titles and create a new column for the total rating for so for each and every book how many total ratings is there we will be calculating that and we'll be creating a new column it is called as total rating form now
why I am doing this see why I am doing this is that because ah from this books also you may have just one or two ratings or four you know you may have ten ratings again if you have so many so less number of ratings that cannot be a popular book so I am just trying to create a threshold value wherein I'll say that if this particular book has a total rating count of more than 50 or 100 then only I'll be considering those rows so on this particular dataset so once I apply this particular
condition and see the total rating down and this is a simple port wherein I'm just taking my combined book rating which I had created over here and trying to group by book title and book rating and I'm trying to see the count and finally after seeing the count I have the total rating comes over here so this particular total rating counts is like just you can see over here you have for some books like the light in the storm just have two ratings right always have popsicles this book has just one rating just imagine and
you can't just have that much information to recommend somewhere so what we do is that we try to we'll just create some you know we'll create some threshold value wherein will be saying that if it is greater than that threshold value only those records I will be considering but before that what I will do is that I will try to merge this column or this dataset which is my rating counts since I need this total rating down and then I am going to merge with my this combined book based on I is here and that
is what I am actually true doing in this particular for combined underscore book rating dot merge and Here I am giving my book under score rating count book under score rating count is basically my dataset of this my left on on which key I am actually using it this is basically book title right on will be my book title again so this is basically which key I am going to take from a left data frame which key I am going to take on my right data frame and how what kind of joy none basically using
this is basically a left join yeah once I do it once I see the head part you can see like this I will be getting my dataset okay now as I said that my total rating count is near one condition I'll put is that I'll keep a threshold value saying that if it is greater than that particular threshold value only those ratings I will be considering so what I will do is I will create a variable called as popularity threshold which will be 50 okay that basically means if they are more than 50 ratings or
total ratings for that book then only I am going to consider and finally I'll just say that rating with total rating count which is my variable which I created over here and I'll say that I'll put a query saying that if the total rating count is greater than the popularity Thresh then I'm going to take the head off then here you have the complete leaders okay so I have basically removed all the books you know which is not having more than 50 total ratings and because I know that till that many books it may not
be popular okay since we have again this threshold value can be changed you can try up to a different friend special value now when I did this and when I saw the shape they were around 62,000 records in all ways now the main problem is that when I was trying to run it up like a nearest neighbor it was really ting much time in my laptop so what I did is that I just took the users from using USA and Canada only when I took the users from US and Canada there was small number of
Records so what will do is that you just try to create a recommendation for USA and Canada citizens of Canada people who are staying over there and based on this particular dataset will just give the recommendation definitely if you have a powerful laptop you can definitely apply for the completely so here what I am doing is that the rating popular book I'm merging with the users because I have to take only users from user and Canada you remember I have a user data set which I have already read and here you can see this is
my user data set right so user data set I have already so I am just going to apply a small condition saying that I'm going to take I'm going to join left on join with user ID and user ID over here what end of join when I'm merging this data frame with my users data frame I am going to take a left join after taking a left join all I do is that I apply this particular condition where I say that whenever the location string contains us in Canada just pick up that particular rows so
all the rows will be you know stored in this particular variable after that I drop the H column I don't who are it okay age because based on age we are not providing the recommendation you're just providing based on US and Canada and based on the ratings that they provide and this is my data set how it will look like and you can see that location is basically USA it is given on the right hand side now the main thing is that if I am applying you know cane a nearest neighbor one technique that I'm
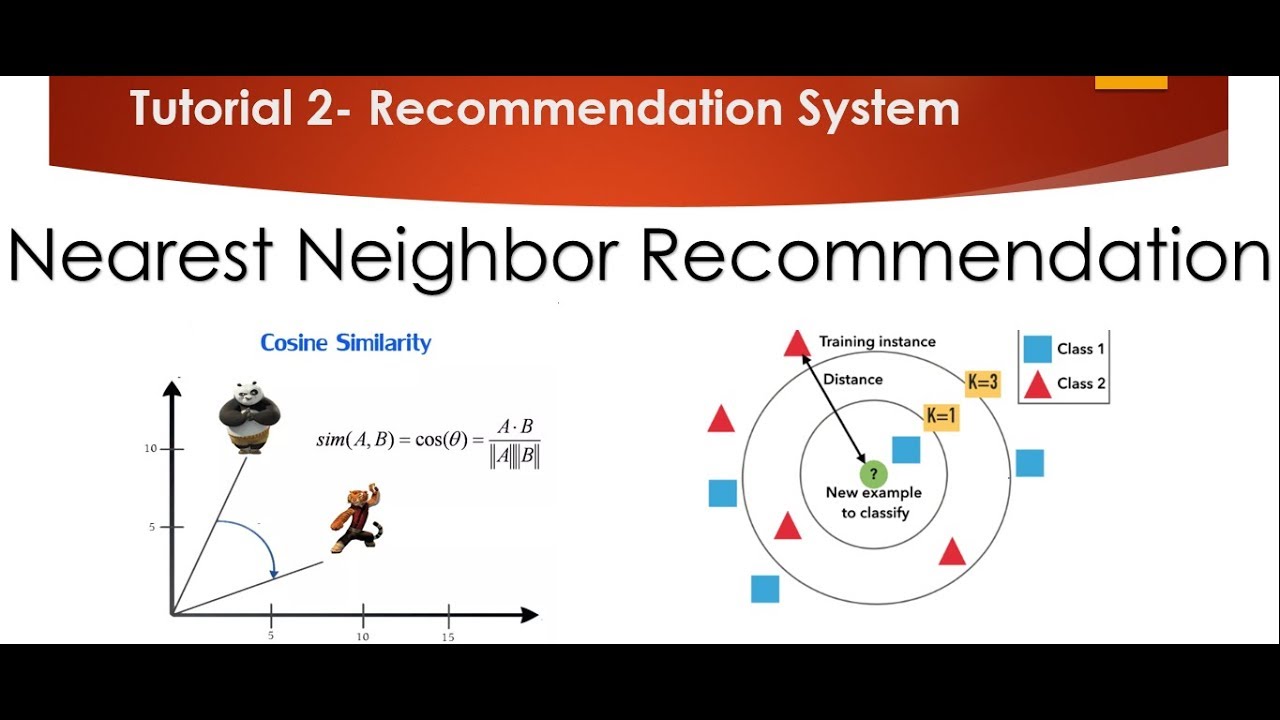
going to apply something called as cosine similarity cosine similarity what we do is that each and every movie each and every movie will be represented in vectors suppose I have a movie called as Avengers and Avengers vectors are somewhere like 1 comma 0 and it is pointed over you okay it is pointed away let me just remove this if suppose it is point I'll just create it once again so this is my graph and suppose I consider that Avengers is basically a two vectors steel cosine similarity if you don't know that I have already explained
in a previous video oh each and every movies will be represented in vectors okay and that will be populated in a graph like this intimately suppose my Avengers is basically represented as 1 comma 0 this is 1 and this is 0 so it may be pointing away suppose I want to find other movie which is just like a comedy movie like minions ok and suppose for this the vector is 0 comma 1 and I see that you know the distance is so much how to how do we find out the cosine similarity between this is
by using this simple formula and if I just go and create a line like this there will be some angle created suppose this is 45 degree in order to find out the relationship between minion and Avengers here I can just use cos 45 and this will be somewhere around the you know 0.53 so this basically indicates that there is around 53% of similarity between minions and Avengers even though minions is a comedy movie and then just have some amount of comedy scenes but it is not completely when you see some scenes of Hulk and all
so this kind of percentage basically indicates that how similar the movies are based on percent similarity and this cosine similarity we are going to use with respect to K nearest neighbor because K nearest neighbor will help us to compute the distance when I want to compute the distance this kind of distance between this point and this point be able to get the angle if I use cosine as my parameter okay so let's see how to do this let's see how to do this practically so here what I am doing is that first of all whatever
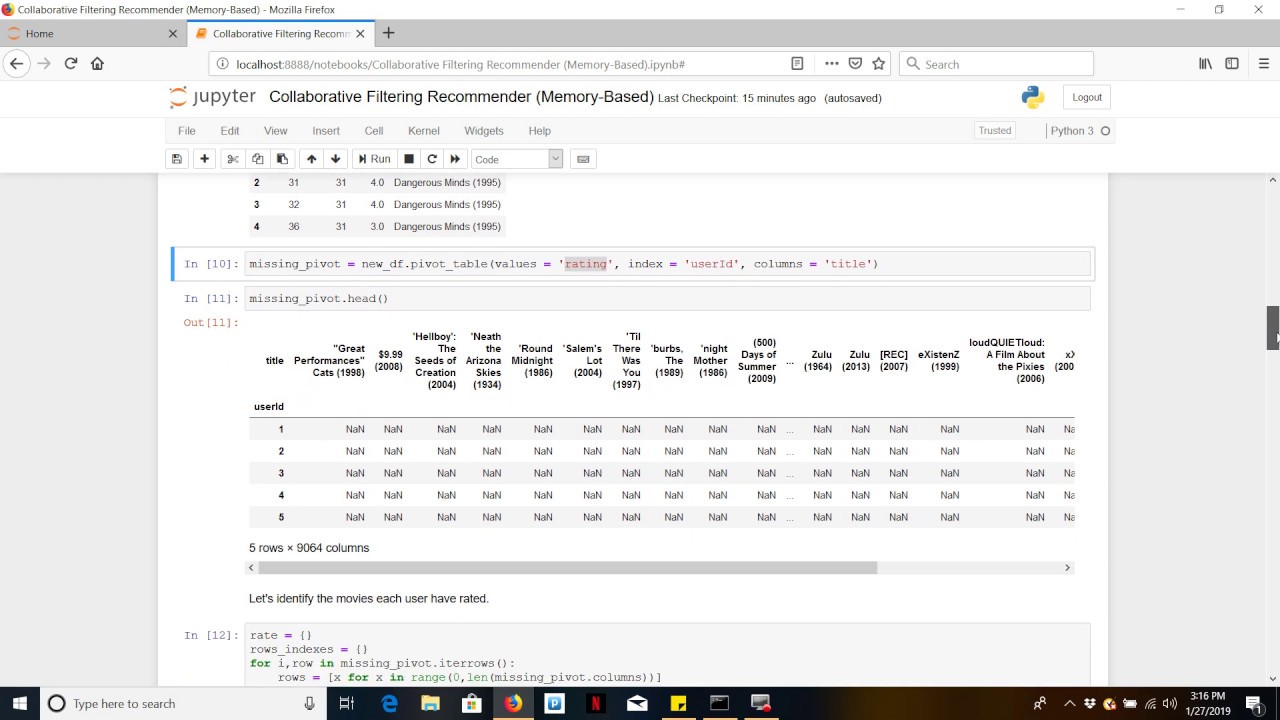
matrix this I have I am converting this into an array I have to convert this into an array so for that what I will do is that I will be taking my user ID so here you can see that I am saying that drop duplicates user ID in book title because they may be some duplicates and then after that I will create a pivot table based on book title so basically on on on all my indexes there will be book titles okay on all my Nexus there will be book title and my columns it should
have user ID and my value should be having ratings okay so let me just are acute this for you and let me just show it to you how it will look like for that what I will do is that I'll just go and execute all these things that is required I'll just give me a second I'll just execute all these things because okay this is executed I have to create the data set for us in Canada I see this as soon as I execute this statement and when I create a new cell now main thing
is that I have created a pivot table okay so before creating a pivot table if I go and see this okay and I just write dot head here you can see that what what this pivot table is doing in the index is I have taken all my book title in all my features I have basically taken my columns so column is basically all my user IDs and these are the ratings that are given by this particular user ID suppose over here you have ten this basically indicates that for this particular user ID it has given
ten rating for this particular movie sorry non-moving for this particular book okay so this is what I have basically created this is basically my pivot table now after creating this because see the main thing I need is book title user ID and book rating based on this I will be trying to you know do a recommendation here I'm basically using collaborative filtering so after this what I do is that I create this in the form of matrix and for that I will be using Skype I in Skype I you have something called as CSR underscore
matrix which will actually create a sparse matrix sparse matrix basically indicate is that most of your values will be zeros and some of the values will be non zeros here you can see an example for that and for that I am creating a matrix by using Skype ID or sparse after this what I do is that I implement this K nearest neighbor and for implementing the nearest neighbor all I have to do is that I have to use SK learn dot neighbors input nearest neighbor so inside this nearest neighbor I am going to use the
metric cosine the algorithm will be root and then finally I am going to fit this particular data set that I have actually created from that pivot umm so not timid sorry it will be the matrix part so here it is once I do this it will basically apply all the things remember guys how many neighbors I am going to take by default to define neighbors P is equal to two indicates that the distance it will be calculated based on Euclidean distance please have a look I have already created videos on this also after this what
I will do is that I will go down I will just select suppose I'll select one movie suppose this particular shape of zero and basically selecting an index number and based on that particular index number what I am doing is that I am taking that whole field old field whole row right whole row and I am trying to find out give me the nearest six neighbors by using model and the Spokane and dot K neighbors okay so these are the parameters that you have to supply whenever you want to do this first is that which
row you want the complete data set and how many neighbors how many movies recommendation you want so six I have written so here you can see that once I execute it right so I have got six fifty five throw so 653 row information is given in the first parameter all this information the records all the information how many neighbors how many movies I want to get the recommendation so I have written in six so let me just go and see that this 655 is rich movie movie is something called as the summer house and for
this recommendation I have just written a small code because this this K nearest neighbors will give us two parameters as a response one is the distance value that basically indicates that how far the other recommended movies are from this current movie that is the summer house and indices that basically indicates at which movie is basically recommended which in movies basically you can convert that and once you execute it you can see that recommendations for the summer house is basically you have five movies that has given you know and there is also a distance parameter VLC
the 73 percent 73 percent point seven three point seven four and always remember that as the distance increases you know as the distance increases that basically means that it is less recommended okay so in this case the highest recommended is this miss Julia speaks of mind this is unknowable and this is basically the distance is 0.7 three it is not in percentage sorry it is in point three point seven three that basically means that that much far it is from the summer house and this is the most nearest recommended me so this was with respect
to K nearest able guys the most important thing is that how do you implement this cosine similarity this cosine similarity is basically given as a functionality in your kN so here it is in it is given in your ka you can see that my first parameter metric is basically given s so this was about how you can create a book recommendation system using a nearest neighbor I hope you like this particular videos guys make sure you subscribe the channel if you have not already subscribed I'll see you all in the next video I hope you
are learning a lot from my videos from my contents please like the videos to share with all your friends who ever acquire this kind of this and make sure you press the bell icon or because whenever I upload any videos will get the notification thank you one and all I'll see you in the next video