दे स्टूडेंट्स वेलकम तू गेट मेजर्स आज की स्पीड में एक्सप्लेन करने जा रहा हूं इंट्रोडक्शन तू हलूप जादू की स्टोरी जो है वो स्टार्ट होती है 21st सेंचुरी की बिगिनिंग से मतलब अगर हम बात करें 2001 से तो वहां से इसकी स्टोरी जो है वो स्टार्ट होती है जब इंटरनेट जो था वो पॉप्युलर होने लग गया था मतलब उसे टाइम पे इंटरनेट जो है वो मार्केट में ए चुका था और वहां पे बहुत सारे यूजर्स जो है वो डेली बेसिस पे इंक्रीस हो रहे द तो उसकी वजह से हुआ क्या उसकी वजह से बहुत बड़ा
फर्क पड़ा डाटा के ऊपर मतलब उससे पहले की बात करें तो डाटा हम लोग journalli क्या कर रहे द rojed कॉलम्स में डाटा को स्टोर कर रहे द मतलब एक प्रॉपर स्ट्रक्चर डाटा था और उसी को ही हम स्टोर कर रहे द और उसी को हम प्रक्रिया करके आंसर फाइंड आउट कर रहे द अब अगर मेरा डाटा स्ट्रक्चर है तो मेरे पास बहुत सारे अच्छे सॉल्यूशंस अवेलेबल द ताकि मैं इजीली डाटा को स्टोर कर सकूं क्योंकि डाटा की वैल्यू जो है डाटा की अगर हम बात करें वॉल्यूम या उसके डाटा साइज की बात करें तो
वो बड़ा लिमिटेड था तो मैं सिंगल स्टोरेज डिवाइसेज में उसको रख सकता था और सिंगल प्रोसेसिंग एलिमेंट्स उसको प्रक्रिया कर सकता था तो कम बड़ा एजी चल रहा था बट जैसे ही इंटरनेट का कॉन्सेप्ट आया तो वहां से टाइप ऑफ डाटा सबसे पहले चेंज हो गया तो डाटा में हम लोग उसे करने लगे टेक्स्ट डाटा को हम लोग उसे करने लगे इमेजेस को वीडियो को इमेज जो द वो बहुत पॉप्युलर होंगे तो एकदम से जो डाटा के अंदर ये चेंज आया तो एक्चुअल में उसका साइज जो था वॉल्यूम पे बढ़ गया क्योंकि इतना उचित अमाउंट
ऑफ डाटा जो है वो जेनरेट होने लग गया क्योंकि अगर मैं बात बताऊं ना वर्ल्ड वर्ल्ड कप 2003 और फोर की बात करूं तो उसे टाइम पर मैं नाइंथ टेंथ क्लास में था तो पहली बार तब मैंने फोन जो है मोबाइल जो है वो पहली बार उसे टाइम पे मैंने देखा था नोकिया 3310 और नोकिया 1100 उसे टाइम पे उसे करना स्टार्ट किया था तो उसमें तो सिंपल टेक्स्ट मैसेज हम लोग सेंड कर सकते द और फिर 2004 में हल्की 2003 में ए चुका था नोकिया 6600 बट 2004 5 में वो बहुत पॉप्युलर हुआ और
उसमें कैमरा भी था कैमरे से आप इमेजेस भी का सकते हो और साथ ही साथ आप वीडियो भी बना सकते हो तो वहां से जो है वो एक नॉर्मल इंसान मतलब हम लोग जो द एक सिंपल मीडियम फैमिली से बिलॉन्ग करें और हम लोग भी वीडियो इमेजेस और इस टाइप की डाटा से डील करने लग गई डेली बेसिस पे तो देखो पुरी दुनिया में एकदम से कितना रिवॉल्यूशनरीज हुआ की सारे के सारे लोग जो है वो डिफरेंट टाइप ऑफ डाटा को उसे करने लगे तो इसीलिए इस टाइप ऑफ डाटा को हम लोग क्या बोलते हैं
बिग डाटा तो क्या हुआ पैरेलल ही उसी टाइम पे 2002 की बात करें तो उसी टाइम पे डॉग कटिंग जो की फादर ऑफ बिग डाटा या फादर ऑफ फाडू बोलते हैं तो डेट इस डॉग कटिंग एंड माइक इन दोनों ने एक प्रोजेक्ट के ऊपर वर्क करना स्टार्ट किया डेट इसे जादू और इसका बेसिकली पर्पस ही क्या था की कैसे हम बिग डाटा को बड़ी अमाउंट ऑफ डाटा को इजीली स्टोर कर सकें और उसको प्रक्रिया कर सके तो उन्होंने 2002 में इस चीज के ऊपर कम करना स्टार्ट किया और फिर बाद में 2008 में याहू ने
ओपन सोर्स जो है वो डिक्लेयर कर दिया इसको रूप के प्रोजेक्ट को एंड दें 2012 में पब्लिक के लिए अपाचे ने इसको क्या कर दिया अवेलेबल कर दिया तो फिर ये तब से अपाचे रूप के नाम से पॉप्युलर हो गया और ओपन सोर्स है फ्रीली अवेलेबल है तो इसीलिए रूप का पर्पस आपसे पूछ लें की क्या होता है तो रूपन ओपन सोर्स फ्रेमवर्क इट इस नॉट अन सॉफ्टवेयर आप ये नहीं का सकते की इस ओनली या सॉफ्टवेयर जैसे आरडीबीएमएस है या जैसे हम बात करें सिंपल डेटाबेस है नहीं ये एक्चुअल में पूरा फ्रेमवर्क है ये
अकेला एवं इसलिए डेटाबेस नहीं है यह एक्चुअल में पूरा फ्रेमवर्क है जो अलाव करता है की डाटा को हमने कैसे स्टोर करना है प्रॉपर्ली और फिर उसे डाटा को कैसे हमने एक्सेस करना है और इसके लिए हम लोग उसे करते हैं डिसटीब्युटेड मैनर में डिसटीब्युटेड मैनर मतलब रदर दें कीपिंग ऑल डी डाटा इन अन सिंगल एरिया इन अन सिंगल डिवाइस हिदूप कहता है की उसे डाटा को डिफरेंट डिफरेंट एरियाज में डिफरेंट डिफरेंट क्लस्टर में उसको स्टोर करो ताकि उसको पैरेलल ही एक्सेस कर सके तो यह कहानी जो है वो हरूप लेके आया तो इसका जो
पूरा कॉन्सेप्ट था पूरा फ्रेमवर्क था वो जावा प्रोग्रामिंग में इनिशियली लिखा गया लेकिन आप लोग अगर c++ में comefortable हो पाइथन में हो जावा में हो तो आप इसके प्रोग्राम जो है वो उसे कर सकते हो फ्रेमवर्क के अंदर तो देखो यहां पे अगर हम बात करें की रूप में बहुत सारे कॉम्पोनेंट्स आते हैं इस पूरे फ्रेमवर्क में बहुत सारे कॉम्पोनेंट्स आते हैं लेकिन दो सबसे बेसिक फ्रेमवर्क के अंदर जो कॉम्पोनेंट्स आते हैं डेट इस सस एंड मैप रिड्यूस यह दो तो आप का सकते हो इस सिस्टम की जान है क्योंकि एचडीएफसी क्या है हलूप
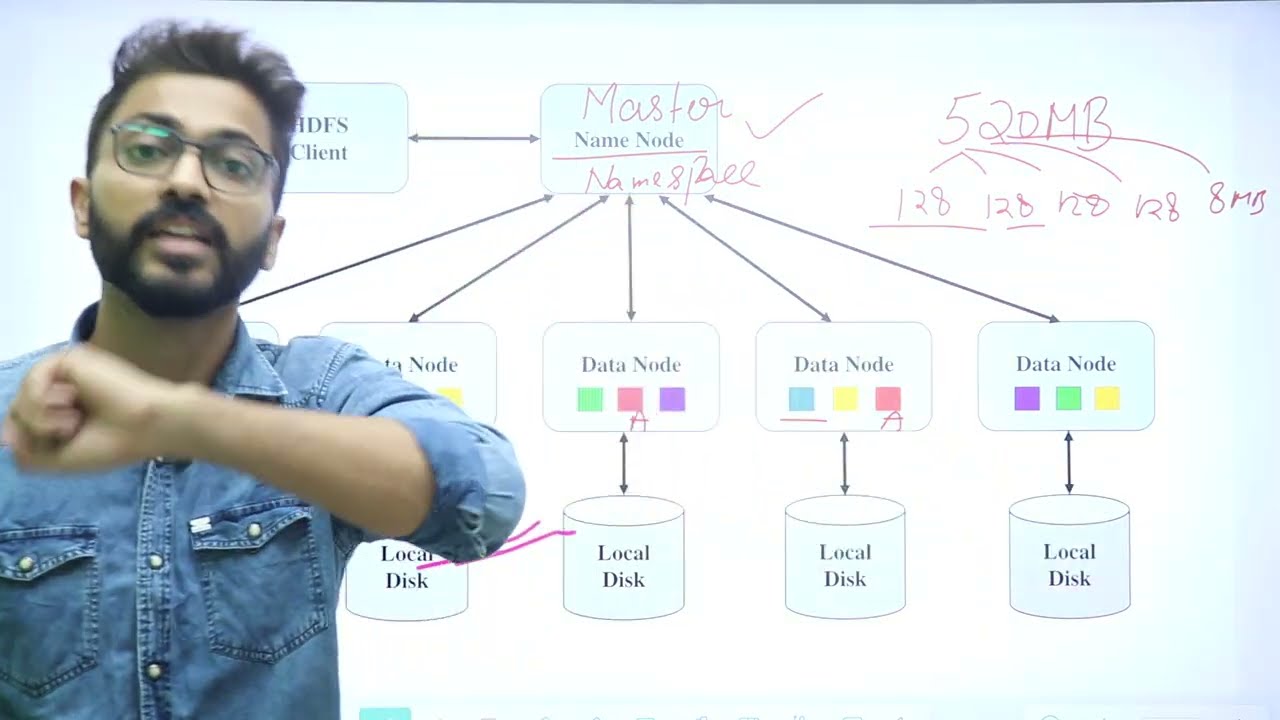
डिसटीब्युटेड फाइल सिस्टम जैसे हम नॉर्मल विंडोज में लिनक्स में उसे करते हैं फाइल सिस्टम जिनका पर्पस क्या है फाइल्स को मैनेज करना तो ये सारी चीज ना लोकल सिस्टम में ओके है लेकिन जब हम बिग डाटा के कॉन्सेप्ट को उसे करते हैं जहां पे ह्यूज अमाउंट ऑफ डाटा से डील कर रहे हैं तो वहां पे हम एक डाटा को एक सिंगल जगह पे नहीं रख सकते हमें जो है वो डिसटीब्युटेड मैनर में रखना पड़ता है तो उसके लिए जो एचडीएफसी जो है वो स्पेशली डिजाइन किया हुआ है की रदर थन कीपिंग डी डाटा ऑन अन
सिंगल एरिया जैसे आपके पास कोई फाइल है 1280 एमबी की तो इसमें करना क्या है ना इसमें पुरी एक फाइल को यह पुरी जो एक फाइल है 1280 एमबी की एक जगह पे नहीं स्टोर करनी इसने क्या करना है उसको पहले डिवाइड करना है उसको क्या करना है डिवाइड करना है और डिवीज़न ये करता है बाय डिफाल्टर 128 एमबी के साइज की तो आप यहीं से अंदाजा लगा सकते हो की ओरेकल में सीक्वल सर्वर में हम 8 कब की पार्टीशन करते हैं 16 कब की पार्टीशन करते हैं या फिर 64 कब किलोबाइट की पार्टीशन करते
हैं यहां पे एक पार्टीशन जो हो रही है ना वही 128 एमबी की हो रही है तो पार्शियली अपने आप में इतनी बड़ी है तो obbviesli ये कितने ज अमाउंट ऑफ डाटा को डील करता होगा तो इस तरीके से ये पार्टीशन करता है और फिर इन पार्टीशंस को क्या करता है अलग-अलग जगह पे से करता है जिसको हम बोलते हैं डाटा नोट्स क्या बोलते हैं डाटा नोट्स तो अलग-अलग जगह पे इन डाटा को यहां पे क्लस्टर में रखता है और इसके लिए ऐसा नहीं की नए-नए हार्डवेयर नए-नए डिवाइसेज को उसे करते हैं हम ऑलरेडी एक्जिस्टिंग
जो कमोडिटी हार्डवेयर हैं उन्हें को ही उसे करते हैं मतलब कॉस्ट को भी यहां पे बचाने की कोशिश की हुई है और फिर जब हमने इसको स्टोर कर लिया तो हमें पता कैसे लगता है की कौन सा डाटा किस रोड पे पड़ा है तो उसके लिए एक होता है मास्टर एक होता है उसमें मास्टर नोड वैसे तो मैं अलग से आपको बताऊंगा जब मैं एचडीएफसी और मैं एवरी ड्यूज को एक्सप्लेन करूंगा लेकिन फिर भी एक आइडिया आपको बता रहा हूं तो इसमें सारा का सारा मैटर डाटा पढ़ा होता है मास्टर रोड में जो बताता है
की कौन सा डाटा किस रोड पे पड़ा है उसकी लोकेशन उसका फाइल का साइज उसके सारे करैक्टेरिस्टिक्स तो डेट इसे कॉल्ड अन मैटर डाटा तो वो इस जगह पे स्टोर रहता है अब यहां पे स्टूडेंट के दिमाग में ए सकता है की सर हमने अलग-अलग तो रख लिया लेकिन लेट्स से अगर एक डाटा नोट फैल हो गया करप्शन हो गया डाटा के अंदर प्रॉब्लम ए गई तो क्या करेंगे ये तो गया डाटा और गया कितना 128 एमबी डाटा लॉस हो गया तो डाटा लॉस तो हो नहीं सकता तो यस यहां पे डाटा लॉस नहीं करता
पीडीएफएस पार्टीशन करके अलग जगह पर तो रखता ही है साथ ही साथ यह उसे करता है कॉन्सेप्ट ऑफ डुप्लीकेशन या रिप्लिकेशन जिसको हम बोलते हैं तो रिप्लिकेशन का कॉन्सेप्ट क्या है की इस पूरे एक ब्लॉक को यहां पे तो रखता ही है पुरी डाटा ब्लॉक को यहां पे यहां पे अलग-अलग साथ ही साथ जो डाटा मैं यहां पे रख रहा हूं इस डाटा मोड पे उसकी एक नहीं कम से कम दो से तीन कॉपीज जो हैं वो अलग-अलग डाटा नोट पे पड़ी रहेंगी ताकि इन केस ऑफ फैलियर हम लोग सेकेंडरी डाटा नोट्स को उसे कर
सके इनको बोलते हैं सेकेंडरी डाटा नोट्स एक तो होगी प्राइमरी जहां पे आपका पूरा फ्रंट फेज हो गया जैसे किसी कंपनी में किसी भी आप जाते हो किसी शोरूम पे तो शोरूम क्या है उसका एक फ्रंट पेज है तो फ्रंट पेज में सारी चीज पड़ी है उनका एक गोडाउन भी होता है की अगर लेट से यहां पे कोई प्रॉब्लम ए गई तो वो गोडाउन से चीज को ले गया यहां पे खत्म हो गया तो ग्राउंड से चीज ले आएंगे तो वो गोडाउन से अलग से रखोगे तो वही चीज यहां पे सेकेंडरी डाटा जहां पे उनकी
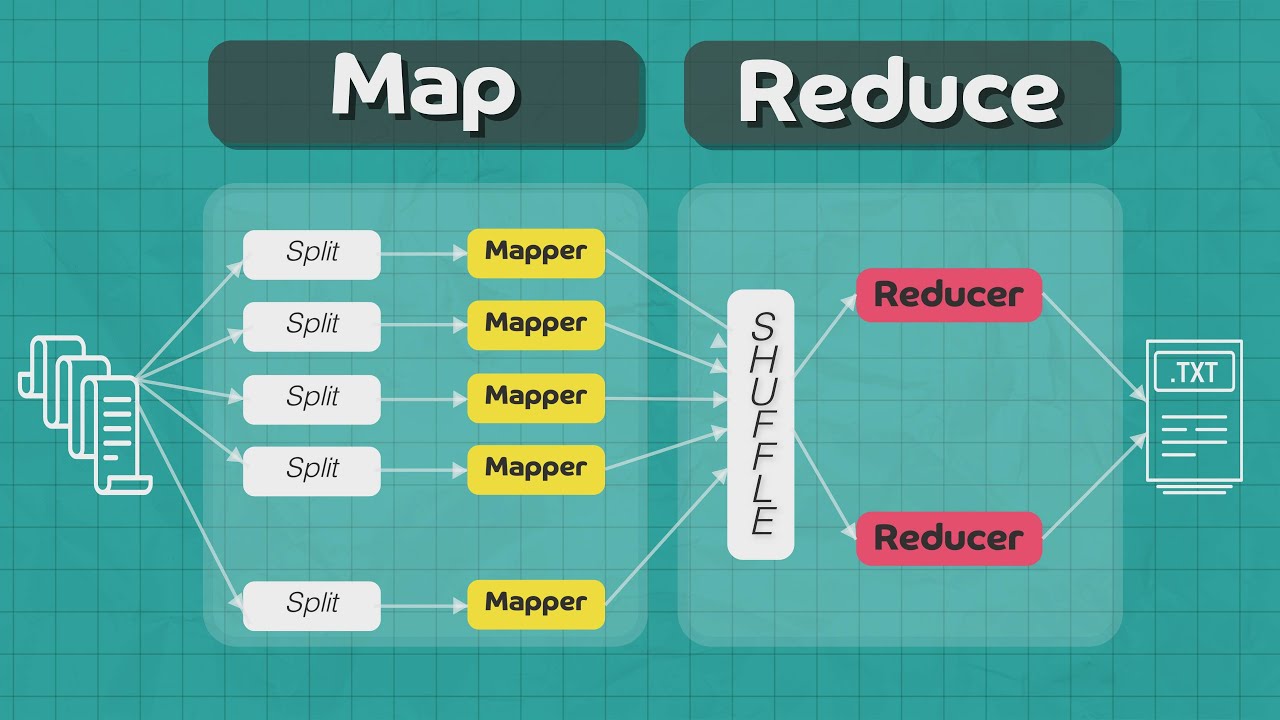
कॉपीज को रखते ताकि इन केस ऑफ फैलियर हम वहां से उठा सके तो देखो कितना पावरफुल टूल यहां पर डिज़ाइन की है दूसरी चीज अपडेट कर लिया अब उसे किया जाता है डेट इस अन प्रोसेसिंग एलिमेंट ऑफ जादू जिसको हम बोलते हैं मैप रिड्यूस ये एक तरह से इसका प्रोसेसिंग एलिमेंट्स सीपीयू और बोल सकते हो तो जिसका कम क्या है इस क्वेरी कोई भी यूजर अगर क्वेरी लिख सकता की मेरे को कोई पार्टिकुलर डाटा चाहिए तो ये पैरेलल्ली डाटा जो है वो एक्सेस कर सकता है और एक्सेस करके उसको जो है वो फाइंड आउट करता
है और मैप रिड्यूस करता है कॉन्सेप्ट ऑफ की वैल्यू पैर तो डाटा को बड़ी प्रॉब्लम को छोटी-छोटी प्रॉब्लम्स में पहले रिड्यूस करके की वैल्यू पर्स में कन्वर्ट करके और फाइनली फिर डिवाइड एंड कंकर की तरह जो है ये वर्क करता है तो इसके पुरी कहानी में आपको फरदार बताऊंगा बट मैनली mainpurities क्या है इसका प्रोसेसिंग एलिमेंट जो एक्चुअल में यूजर ने जो क्वेश्चन पूछा है क्वेरी पूछा उसको आंसर में कन्वर्ट करना तो ये दो में कॉम्पोनेंट्स हैं इसके अलावा हाई है यान है बहुत सारी जुकीपर है वो मेक एक करके डिस्कस करेंगे लेकिन अगर आपको
इंट्रोडक्शन के बारे में पूछ ले क्यों आया कैसे आया तो वो इस वीडियो में आपको अच्छे से मैंने एक्सप्लेन कर दिया थैंक यू


![Hadoop అంటే ఏంటి? What is Hadoop [Telugu] | Big Data in Telugu | Vamsi Bhavani](https://img.youtube.com/vi/Qdy8OZLP0AI/maxresdefault.jpg)