Vamos falar sobre tokenization. Veremos agora porque isso é importante e como implementar em Python. Tokenization é o processo de dividir um texto em partes menores, geralmente palavras ou frases chamadas de tokens.
Então, cada fatia, cada pedaço, cada parte ou cada token representa uma parte gerenciável do texto completo. Imagine que você está lendo o livro, tokenization, seria como dividir o texto desse livro. em palavras ou sentenças individuais, tornando mais fácil analisar e processar o conteúdo.
Esse passo é fundamental para muitas tarefas de natural language processou ou nlp e isso, claro, inclui information retrieval. Então, quando falamos sobre por isso é importante, precisamos ter em mente que primeiro isso simplifica o processamento de texto. Isso permite que algoritmos trabalhem com unidades gerenciáveis de texto.
Também facilita a indexação em information retrieval. A indexação depende de tokens. Bom, existem três formas principais de tokenizar texto, cada uma servindo a um propósito diferente.
A primeira seria a word tokenization, que divide o texto em palavras individuais. Depois temos a sentence tokenization, que divide o texto em sentenças. E isso é útil para tarefas que exigem análise no nível de sentença.
E finalmente a character tokenization, que divide o texto em caracteres individuais. Essa é menos comum, mas é útil para algumas tarefas específicas de eh NLP. Claro que existe alguns desafios quando se trata de tokenização.
Então, decidir se deve remover ou manter a pontuação pode impactar a análise. Às vezes, um ponto ou uma vírgula afeta o significado. E, claro, também as diferenças de idioma.
idiomas diferentes possuem regras diferentes de tokenização, especialmente aqueles sem separações claras entre palavras, como o chinês ou o japonês. Bom, para fazer isso em Python e partir pra implementação prática, vamos usar o NLTK, Natural Language Talkite. Vamos dar uma olhada nesse exemplo.
Vou instalar o NLTK. Então, vi add nlt, OK? criar um novo arquivo, chamar ele de tokenization 01.
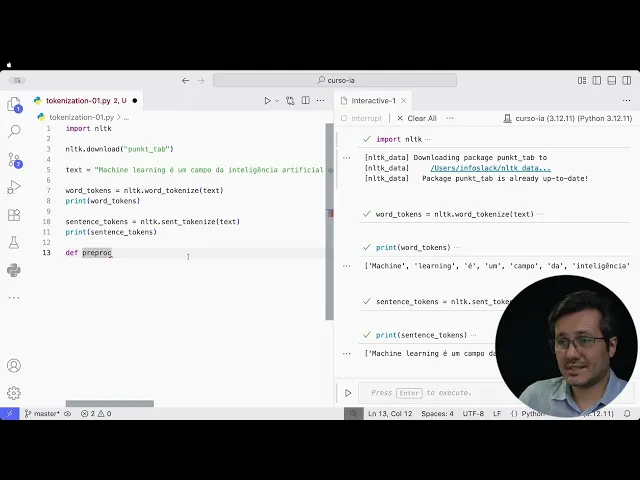
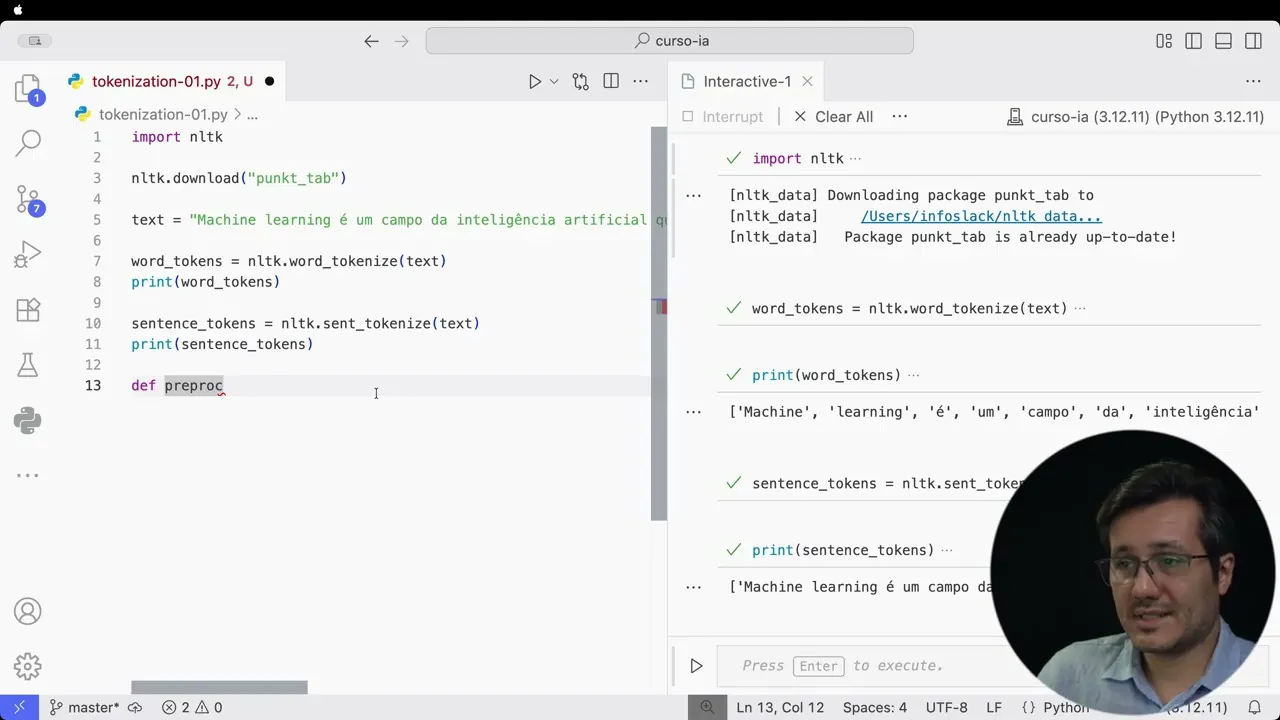
Bom, vou começar importando, né? Vamos importar o NLTK, port NLTK e fazer o download ntk pon download do punkt tab. Tenho aqui punkt tab.
Essa é uma maneira de toquenizar. Vou pegar aqui o texto de exemplo. Temos aqui esse texto.
Machine Learning é um campo da inteligência artificial que permite que computadores aprendam, blá blá blá blá blá. Então esse vai ser o nosso texto de exemplo. E para começar a gente vai fazer a o Word tokenization.
Então se eu quiser tokenizar em palavras ou se eu quiser tokenizar em sentenças, eu vou criar Word tokens. recebe nltk pon word tokenizer e o texto bacana. Vou carregar isso.
Então, se eu quiser dar um print nas o Word tokens, esse seria o resultado. Então, como o Word Tens, né, uma tokenização por palavras, nós temos esses elementos separados. machine, depois learning, é, um, etc.
Então, todos os termos são separados por palavras. Já os sentense tokens dividriam o texto em ah duas sentenças, né, uma para cada período. Podemos fazer um exemplo com sentence tokens.
Tokens. Então, no sentence tokens, eu tenho o ntk. o sentence tokenize e o texto text.
Deixar logo o print pronto. Sentence tokens. Se a gente executar aqui, eu só tenho uma sentença, como a frase ela é separada por vírgula, mas eu posso fazer uma experimenta partir de dados.
Ponto. Vou criar aqui uma segunda sentença. Então, se eu executar tudo, tá?
Vou limpar e executar outra vez. Parte um, word tokenizers. Parte dois, sentence.
Vamos ver agora as sentenças. E ele quebrou em duas sentenças, separado aqui por um ponto. Ficou duas frases.
OK. Agora, se dermos um passo além no preprocessing, por exemplo, né, removendo qualquer token que não seja alfa numérico e até mesmo convertendo, né, o texto para minúsculas, ficaria assim. Então, teria aqui um preco recebe o texto.
E aí dentro dessa função eu tenho os tokens, vai ser igual a nlt wordizer, vai ser por palavras. E aí o primeiro preprocess, eu vou deixar todo em minúsculas lower. Ah, o retorno dessa função vai ser um, opa, uma implementação de lista Word.
For word in tokens. C word. Ok.
Carregar a função. E para exemplificar melhor, eu vou pegar uma lista de documentos. Então, nessa lista eu vou ter mais frases, né?
Três sentenças. Então, vou ter os documentos preprocessados. Preprocess vai receber.
Vou dar aqui no join preoc [Música] doc and documents. Beleza? Ele vai ter nessa lista e passar os elementos, né?
E sentenças paraa função preprocess. Cada documento, né? Cada elemento aqui da lista, cada sentença vai ser preprocessada toda em minúsculas, removendo qualquer parte ali alfa numérica.
E a gente vai carregar isso e ver o resultado no print. Então vou dar um print no preprocess. docs.
Carregar e executar. Primeiro só isso aqui, a lista. Vou ver aqui se funcionou.
Documents. A lista está carregada. A execução e agora o nosso print.
Então agora tá tudo em minúsculos. Machine learning é o aprendizado automático. Tá tá tá tá.
Sentença dois começa todo em minúsculas também. Ele permite que os sistemas façam previsões e a última também. Até parece uma uma sentence tokenization, mas tem em mente que eu tô apenas eh pressando cada um dos documentos, né, cada uma dessas sentenças dentro da lista de documentos.
Bem, isso é só para te dar uma ideia geral do que acontece na tocenização. Esses foram os outputs. Então, quando se trata de dicas práticas para uma tocenização eficaz, o principal que você precisa fazer é pré-processar o texto, ou seja, limpar e normalizar o texto antes da tokenização.
Então, remover caracteres desnecessários, converter o texto para minúsculas, trabalhar com stops como a D, N, sempre dependendo do caso de uso, mas geralmente remover a ajuda. Depois considere o contexto. Devemos ficar atentos ao contexto em que a tokenização será usada.
Tarefas diferentes podem exigir estratégias diferentes de tokenização e, como sempre, testar e iterar. Só para concluir, tocenização pode parecer um processo simples, mas é um passo absolutamente crítico para lidar com dados de texto e analisá-los. E entender todas essas diferentes formas de toquenizar vai te ajudar a criar uma base muito sólida para tarefas mais complexas, tanto aqui no curso quanto fora dele.
Te vejo no próximo vídeo.