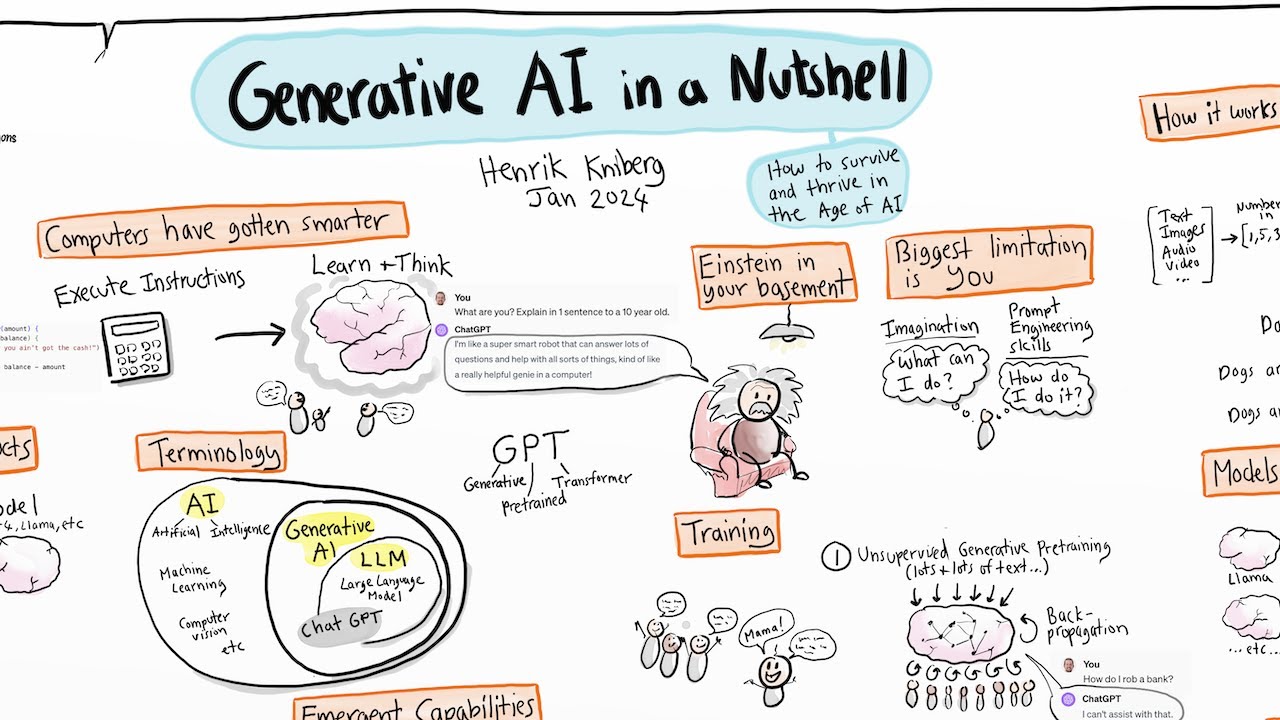
Hello everyone and welcome to a friendly introduction to Language Models, also known as LMs! I am Andreea, and I will be your guide throughout this training program. This particular course marks the beginning of a series of courses centered around the LLM (Large Language Models) learning path.
These courses are part of the H2O University department and Certification Program. Throughout this LLM Learning Path, our primary focus will be on the fundamental components of LLMs. We'll systematically cover various topics essential to the LLM domain, following a chronological order that aligns with the interests of developers and users of LLM tools.
These topics include: Foundation: We will explore the fundamental concepts governing the training of Large Language Models (LLMs) that leverage extensive text data. DataPrep: Our attention will shift to the conversion of documents into instruction-pairs, such as QA pairs, to facilitate effective learning. Fine-Tuning: We'll understand the principles behind curating appropriate datasets to instill desired output behavior in the models.
Evaluation of LLMs: As the popularity of Large Language Models continues to rise across various applications, we'll emphasize the crucial need for comprehensive evaluation and model comparison. Database: We'll discover how to efficiently leverage company data and accommodate new additions to the knowledge base without the need for retraining the entire model. Applications: Lastly, we'll showcase LLM-powered applications, exemplifying the practical utility of these language models.
The current module will allow you to navigate through the fundamental concepts encompassing Language Models. Whether you have a technical background or not, this course is suitable for anyone who wants to delve into the world of language models. Our aim is to make this learning experience both enjoyable and accessible to everyone, as well as to accommodate your preferred pace.
And by the end of it, you will have gained knowledge in the following areas: 1. Understanding what Language Models are: We will learn the fundamentals of language models, exploring their functionality and significance, as well as techniques commonly used in language models. 2.
Importance and Applications: We will discover the wide-ranging importance and practical applications of language models in various fields, as well as 3. Finally, we will get an overview of LLMs or Large Language Models, understanding their capabilities and potential uses. There will be a lot to cover, but after having completed the entire LLM Learning Path, you will be able to complete a knowledge quiz and receive a certificate of completion.
We value your feedback, so please don't hesitate to share your thoughts and insights at the end of your experience. So, without further ado, let's dive in and get started! A language model is a computational model or algorithm that learns and predicts the probability of sequences of words or characters in human language.
It captures the statistical patterns, relationships, and structure of language by analyzing large amounts of text data. Language models commonly utilize two main techniques: pre-training and fine-tuning, both of which play crucial roles in their effectiveness and versatility. Pre-training involves training a language model on an extensive collection of unlabeled text, allowing it to develop a profound understanding of language.
The model learns to predict the subsequent word in a sentence based on context, enabling it to grasp the intricacies of language structure. After this initial pre-training phase, the model is further fine-tuned on a smaller dataset that is specifically labeled for the particular task it is meant to perform. Typically, language models are pre-trained on a vast corpora like books, articles, or internet text.
During pre-training, the models acquire the ability to predict the next word in a sequence, which aids in capturing the statistical properties of language. This pre-training phase, which in machine learning language is called unsupervised learning, serves as a foundation for the model's language comprehension. Following pre-training, the language models can be fine-tuned for specific downstream tasks, such as machine translation or sentiment analysis, using datasets that are tailored to those tasks and have explicit labels for training, which in machine learning language is called supervised learning.
The techniques employed in language models have evolved over time, ranging from basic n-grams to more advanced deep learning models like Transformers. These advancements have significantly contributed to the progress in the field of language modeling. However, each technique comes with its own set of advantages and limitations, which researchers continually explore and experiment with to enhance the performance and capabilities of language models even further.
As previously mentioned, LMs can be trained using various techniques, such as n-grams, hidden Markov models (HMMs), recurrent neural networks (RNNs), or transformer-based architectures like GPT (Generative Pre-trained Transformer). These models learn the probabilities of word sequences and can generate new text by sampling from the learned distribution. Here are some additional details about the techniques commonly used in language models: 1.
N-grams are a simple method used in language modeling. They are sequences of N neighboring words or characters. To understand language patterns, the model counts how often these sequences appear in a large text collection.
However, N-grams have a downside - they struggle to grasp connections between words that are far apart in a sentence. These connections, known as long-range dependencies, go beyond the immediate neighboring words. 2.
Hidden Markov Models (HMMs) are special models that help us understand the patterns in sequential data, like language. In language modeling, HMMs use hidden states to represent different language ideas or grammar rules. These hidden states change based on probabilities, guiding how words follow each other.
HMM-based language models can predict the probability of a word based on the previous word or the context around it. 3. Recurrent Neural Networks (RNNs): RNNs are a type of neural network designed for working with sequences of data, like words in a sentence.
They have a special ability to remember important information from earlier words as they process the sequence. This memory helps them understand how words relate to each other, even if they are far apart, allowing them to capture the context in language. 4.
Transformer-based Models: Transformer-based models have had a big impact on language modeling. They use special attention mechanisms to understand the relationships between words in a sentence. It's like they can pay more attention to certain words that matter the most for understanding the context.
The Transformer architecture, which was introduced in a famous paper called "Attention is All You Need," has become very popular, and models like GPT have become really influential.



![[1hr Talk] Intro to Large Language Models](https://img.youtube.com/vi/zjkBMFhNj_g/maxresdefault.jpg)