In this video, we take a look at how ChatGPT works. We learned a lot from making this video. We hope you will learn something, too.
Let’s dive right in. ChatGPT was released on November 30, 2022. It reached 100M monthly active users in just two months.
It took Instagram two and a half years to reach the same milestone. This is the fastest growing app in history. How does ChatGPT work?
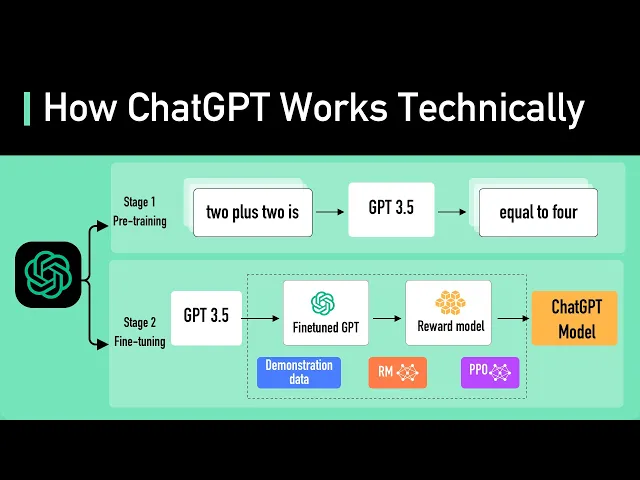
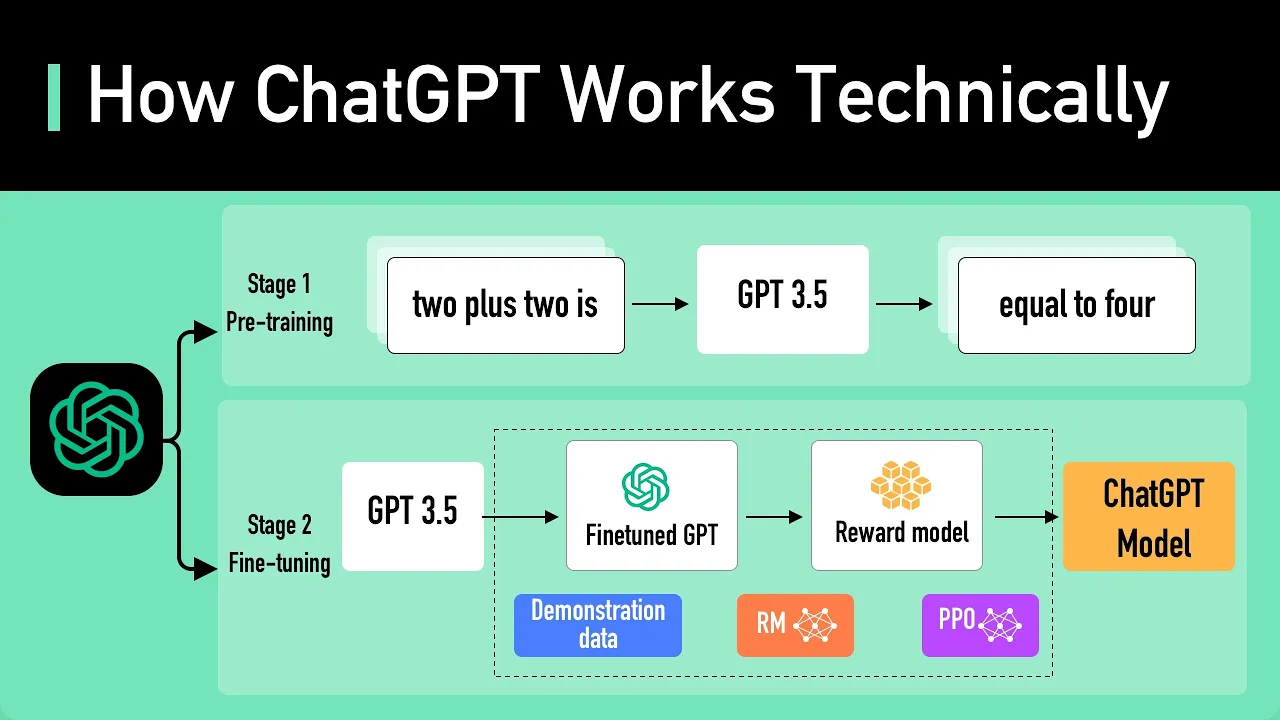
The heart of ChatGPT is an LLM, or a Large Language Model. The current LLM for ChatGPT is GPT-3. 5.
ChatGPT could also use the latest GPT-4 model, but there is not much technical detail on GPT-4 for us to talk about yet. What is a Large Language Model? A Large Language Model is a type of neural network-based model that is trained on massive amounts of text data to understand and generate human language.
The model uses the training data to learn the statistical patterns and relationships between words in the language, and then utilizes this knowledge to predict the subsequent words, one word at a time. An LLM is often characterized by its size and the number of parameters it contains. The largest model of GPT-3.
5 has 175 billion parameters spread across 96 layers in the neural network, making it one of the largest deep learning models ever created. The input and output to the model are organized by token. Tokens are numerical representations of words, or more correctly, parts of the words.
Numbers are used for tokens rather than words because they can be processed more efficiently. GPT-3. 5 was trained on a large chunk of Internet data.
The source dataset contains 500B tokens. Looking at it another way, the model was trained on hundreds of billions of words. The model was trained to predict the next token given a sequence of input tokens.
It is able to generate text that is structured in a way that is grammatically correct and semantically similar to the internet data it was trained on. But without proper guidance, the model can also generate outputs that are untruthful, toxic, or reflect harmful sentiments. Even with that severe downside, the model is already useful, but in a very structured way.
It could be “taught” to perform natural language tasks using carefully engineered text prompts. This is where the new field “prompt engineering” came from. To make the model safer, and be capable of question and answer in the style of a chatbot, the model is further fine-tuned to become a version that was used in ChatGPT.
Fine-tuning is a process that turns the model that does not quite align with human values into a fine-tuned model that ChatGPT could use. This process is called Reinforcement Training from Human Feedback (RLHF). OpenAI explains how they ran RLHF on the model, but it is not easy to understand for non-ML people.
Let’s try to understand it with an analogy. Imagine GPT-3. 5 as a highly skilled chef who can prepare a wide variety of dishes.
Fine-tuning GPT-3. 5 with RLHF is like refining this chef's skills to make their dishes more delicious. Initially, the chef is trained with a large dataset of recipes and cooking techniques.
However, sometimes the chef doesn't know which dish to make for a specific customer request. To help with this, we collect feedback from real people to create a new dataset. The first step is to create a comparison dataset.
We ask the chef to prepare multiple dishes for a given request, and then have people rank the dishes based on taste and presentation. This helps the chef understand which dishes are preferred by the customers. The next step is reward modeling.
The chef uses this feedback to create a "reward model," which is like a guide for understanding customer preferences. The higher the reward, the better the dish. Next, we train the model with PPO, or Proximal Policy Optimization.
In this analogy, the chef practices making dishes while following the reward model. They use a technique called Proximal Policy Optimization to improve their skills. This is like the chef comparing their current dish with a slightly different version, and learning which one is better according to the reward model.
This process is repeated several times, with the chef refining their skills based on updated customer feedback. With each iteration, the chef becomes better at preparing dishes that satisfy customer preferences. To look at it another way, GPT-3.
5 is fine-tuned with RLHF by gathering feedback from people, creating a reward model based on their preferences, and then iteratively improving the model's performance using PPO. This allows GPT-3. 5 to generate better responses tailored to specific user requests.
Now we understand how the model is trained and fine-tuned, let’s take a look at how the model is used in ChatGPT to answer a prompt. Conceptually, it is as simple as feeding the prompt into the ChatGPT model and returning the output. In reality, it’s a bit more complicated.
First, ChatGPT knows the context of the chat conversation. This is done by ChatGPT UI feeding the model the entire past conversation every time a new prompt is entered. This is called conversational prompt injection.
This is how ChatGPT appears to be context aware. Second, ChatGPT includes primary prompt engineering. These are pieces of instructions injected before and after the user’s prompt to guide the model for a conversational tone.
These prompts are invisible to the user. Third, the prompt is passed to the moderation API to warn or block certain types of unsafe content. The generated result is also likely to be passed to the moderation API before returning to the user.
And that wraps up our journey into the fascinating world of ChatGPT. There was a lot of engineering that went into creating the models used by ChatGPT. The technology behind it is constantly evolving, opening doors to new possibilities and reshaping the way we communicate.
Tighten the seat belt and enjoy the ride. If you like our videos, you may like our system design newsletter as well. It covers topics and trends in large-scale system design.
Trusted by 250,000 readers. Subscribe at blog. bytebytego.