Bom, e para encerrar esse nosso conteúdo sobre a representação, vamos discutir um pouquinho sobre representação para áudio. eh de volta, né? A a história contada de maneira bastante similar com o que a gente viu até então para texto e pra imagem.
Eh, a gente usava no começo, nos anos 50, como eu disse lá, texto e áudio foram as duas primeiras aplicações que a gente teve eh para testar algoritmos de aprendizagem de máquina. Da mesma forma como a gente fazia em texto, o áudio, a gente pegava o sinal e usava transformado de furrier lá nos nos anos 50, até anos 70. Depois bastante parte de engenharia de característica tentando imitar a percepção humana, né, que é esse o que faz o o framework chamado Maras.
Foi bastante usado até o começo dos anos 2000. É um framework em C++. Atualmente a gente tem um framework chamado Liby Rosa, que é bastante interessante em Python, bem fácil de usar também para quem ainda eh tá interessado em extrair características de de texto e os as técnicas de deep learning também tomando, dominando eh esse tipo de aplicação, aplicação de áudio, tá?
Engenharia de características, eh algumas delas são bastante usadas ainda de volta. Se você tem um contexto bem específico para alguma aplicação específica, que técnicas de deep learning ainda são muito pesadas e tal, eh características como short furrier é transformado de de de furrier. Eh, os o as características baseadas na frequência de mel.
Essas são características que são que tem um um apelo eh bastante interessante, porque elas tem uma fundamentação que mostram que é assim que a a percepção auditiva humana funciona. Então, ela tenta fazer essa imitação, tá? Características que usam, capturam o tom, né?
são bastante usados para fazer discriminação de gêneros musicais e tal, eh, que são as chamadas chroma features. E tem outras características também que são usadas na classificação e segmentação de áudio, tipo taxa de cruzamento zero, né, aonde faz o cruzamento, eh, centroides pract. Todas essas características hoje em dia tão implementadas dentro desses frameworks como o Marcias e como o o o Liby Rosa, tá?
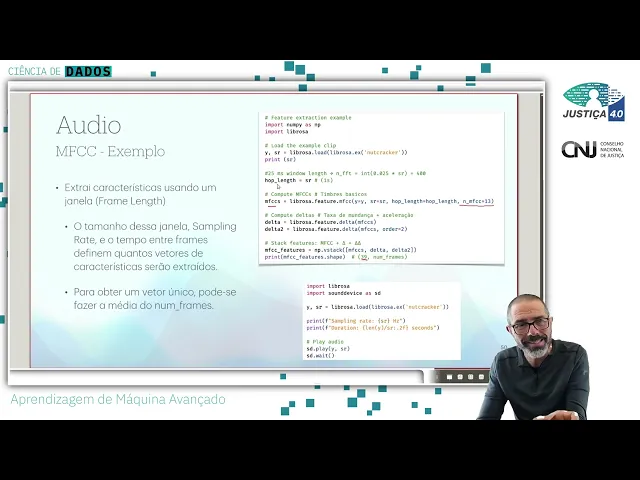
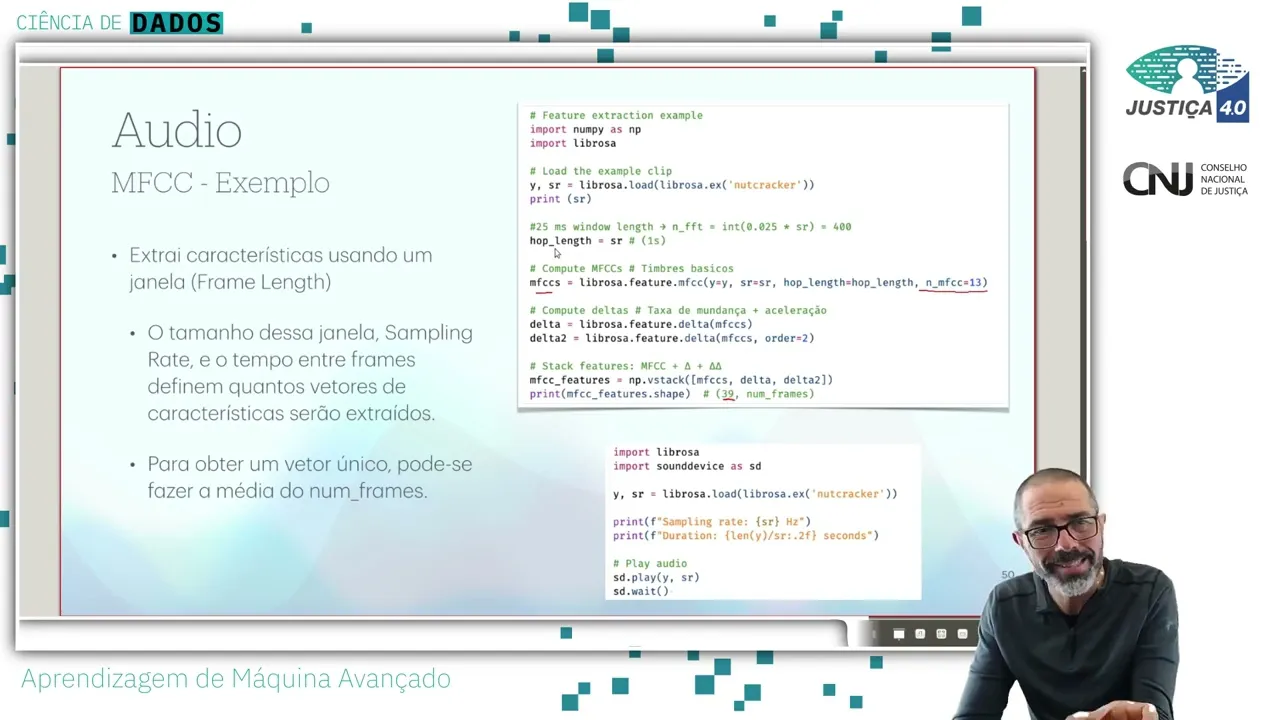
Eh, aqui a gente tem um um exemplinho bem simples do do do MFCC, que é uma das características que que é bastante usada hoje em dia. Eh, então vocês podem ver que ela funciona de maneira bastante simples. Então aqui tem um exemplo onde a gente carrega da própria biblioteca um um pedaço de áudio, né?
Eh, aí a gente tem o nosso áudio dentro desse desse dessa variável Y. E ele retorna também qual que é o sampling rate, né, dessa dessa desse áudio foi gravado, né? Eh, e eu vou calcular os componentes do do MFCC, simplesmente chamando a funçãozinha em DMFCC, passando alguns parâmetros.
Quantos componentes você quer? Ah, eu quero os 13 principais. Eu tenho os Aí você pode verificar quantos componentes do MFC você quer.
Eh, nesse nesse exemplo ainda a gente calcula o delta 1 e o delta 2, que é basicamente a taxa de mudança e aceleração desse áudio. E no fim a gente tem um conjunto de características para cada frame, ou seja, ele vai ter 39, um vetor de 39 posições, somando essas três características aqui para um conjunto de frames. Se eu quero ter, você suponha que você tem um áudio de uma duração, sei lá, de 10 segundos, eh, e eu faço um essa janela de um de segundo em segundo.
Então, passando o sampling rate para esse tamanho de janela, nesse caso aqui, ele vai me extrair um vetor de característica a cada segundo, sem sobreposição. Eu posso ter com sobreposição ou sem sem sobreposição. E aqui a gente entra, eh, tem a similaridade entre texto e outro, porque os dois são uma sequência.
Falando, bom, mas eu, legal, eu tenho um áudio inteiro, eu quero saber se esse áudio pertence a qual classe. Que que eu vou fazer? Eu posso fazer uma média de todos os as janelas de um segundo que eu tenho, fazer uma média e pedir pro classificador, olha, esse aqui é o exemplo desse áudio inteiro.
Ou eu posso pegar alguns pedaços, algumas algumas janelas, falar: "Olha, tá aqui os exemplos desse áudio que eu tenho. 10 exemplos, por exemplo, do mesmo áudio, mas são representações, cada um de um pedaço do meu áudio diferente. " Então, depende muito da aplicação, o que que você tá fazendo.
por exemplo, aplicação de de classificação de gênero musical. Eh, por exemplo, você pega uma música que é meio progressiva, ela começa devagar e acaba rápida. Eh, depende muito a área que você pega do do pedaço do áudio que você pega, você vai ter um resultado diferente, um vetor de característica diferente.
Então, geralmente a gente faz alguns algumas amostras, pega algumas amostras desse áudio para fazer a classificação. Isso pode ser feito de várias maneiras usando esse tipo de biblioteca, tá? Eh, aqui tem um exemplinho de código simplesmente para você baixar o código, né, usando essa essa linha de comando aqui e e dar um play, né, dentro desse desse teu do código aqui para vocês e terem ideia do que que tem aqui.
Eu tenho um um exemplo de de um exemplo de áudio aqui. E esse um outro exemplo de áudio que é uma música, tá? Então tem esses dois exemplos de áudio aqui.
Eh, a gente já vai voltar nesses dois exemplos de áudio, só para vocês verem como que eh algumas técnicas de deep learning podem classificar esses exemplos, tá? Eh, uma outra técnica que foi bastante usada e ainda é usada é os gerar o espectrograma da imagem, tá? Então eu converto o sinal de áudio num espectrograma.
Então o que que é esse espectrograma aqui? É alguma coisa parecida com que a gente viu uma imagem, certo? Nada mais é do que uma textura.
Então eu posso fazer, por exemplo, que eu tenho texto, o espectrograma numa música clássica, que eu tenho espectrograma numa música eletrônica. É um pedaço da música, né? Então eu vou fazer pegar uma amostra e gerar um espectrograma.
Então notem que eu posso converter um problema de áudio num problema de imagem, que é uma textura, e usar as técnicas de representação de imagem, pode ser um LBP, pode ser uma CNN para fazer a classificação do áudio usando uma imagem. Isso, a gente tem um monte de literatura mostrando que isso funciona eh muito muito bem, tá? Eh, e finalmente deep learning de volta, né?
Então, vários modelos de prarning podem ser usados para fazer represent gerar representação. Diria que uma que é bastante usada é a tal da net, que gera uma representação de 1024 característica, que pode ser usada para treinar um classificador. Ou essa rede, ela também já foi treinada para 521 classes.
Então, ela tem 521 classes possíveis de áudio lá dentro de de diferente a é uma música, é um é um discurso. Eh, então são vários exemplos que eles já estão treinados lá dentro. Como que a gente usa?
Mesma coisa. Eh, você pode e usar o o tensor flow, o tensor flow hub para ele, tá? É que eu tô usando e carregando mesmo, um exemplinho de áudio, tá?
carreguei um modelo lá do do Hub transferor flow, então esse Yamnet aqui, eh, e a gente classif usa a representação. Então, notem que eu tenho a representação gerada dentro da minha da dentro da minha variável embedings aqui. Então, dentro do meu embeding, esse modelo vai me retornar um vetor de característica, ele vai me retornar o espectrograma, se eu quiser, e também o score.
essas classes aqui. Então, por exemplo, se eu pegar esse esse áudio que eu toquei para vocês anteriormente, deixa eu tocar ele de volta. Então, notem que é um discurso.
Se eu pegar esse áudio, que é esse, exatamente esse arquivo aqui, e falar: "Olha, me gera uma representação, ele vai me gerar uma representação, eu posso fazer o que eu quiser com essa representação para treinar um classificador". Mas esse classificador, essa rede já me classifica esse áudio na classe spe, tá? Então, eh, eu tenho um notebook aqui que eu posso compartilhar aqui com vocês.
Deixa eu só. Então, nesse notebook a gente pode ver os exemplinhos de como esse o libros funciona. Então, eu tenho o libros carregando o nosso exemplo.
A gente pode dar um play nesses exemplos aqui, tá? Eh, aquele mesmo exemplo que tá no slide, ele tá aqui. Então, notem que eh eu tenho a representação gerada dentro para aquele para aquele exemplo de áudio.
Então, notem que ele gerou 39 pelo frame rate que a gente usou de um segundo. São 120 frames que ele tem aqui. Então, se eu quiser uma representação inteira da música, que é aquela música que eu toquei anteriormente, que é essa música aqui, né?
Então essa música que tá tocando, eu posso representar ela com vetor de 39 features em 128 frames, ou seja, tenho 128 vetores de 39. Se eu quiser um único vetor para essa música, posso fazer uma média dela, mas não há que fazer uma média inteira de um vetor inteiro acaba não sendo uma boa uma boa alternativa, né? Geralmente a gente pega vários vetores dessa dessa dessa música, tá?
Eh, então se como aquele exemplo, se eu calcular, se eu rodar aquele exemplo para fazer a classificação, ele vai atribuir a classe speit. Se eu rodar o outro exemplo da outra do outro, esse exemplo nesse pedaço de código, vocês vão notar que ele vai atribuir a outra classe que não é speech, ok? Eh, e finalmente, eh, a gente pode usar também alguns modelos, não para extrair representação, mas modelos prontos.
Por exemplo, esse é um clássico que é o whisper para fazer eh tradução, né, do nosso áudio pro transcrição do nosso áudio para texto. Então aquele esse essa esse áudio de que a gente deu como exemplo do speech ali, ele tá transcrito aqui simplesmente com essas três linhas de código aqui usando a biblioteca Whisper. você passa o teu áudio e ele vai imprimir para você a transcrição desse áudio, tá?
Então esse é um é um já não é mais extrair uma representação, mas é mostrar que modelos eh de deep learning podem ser usados, né, para diferentes tipos de aplicações, eh além de extrair só uma representação. Hoje em dia a gente tem diversos tipos de aplicações. Então, era isso pro nosso conteúdo de áudio e era o isso fecha o nosso conteúdo de eh representação em aprendizagem máquina.
Obrigado.